InnoDB与MyISAM的最大不同有两点:一是支持事务(TRANSACTION);二是采用了行级锁。行级锁与表级锁本来就有许多不同之处,另外,事务的引入也带来了一些新问题
1.事务(Transaction)及其ACID属性
事务是由一组SQL语句组成的逻辑处理单元,事务具有以下4个属性,通常简称为事务的ACID属性。
原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
银行转帐就是事务的一个典型例子。 //https://blog.csdn.net/bigtree_3721/article/details/77417518
2.并发事务处理带来的问题
相对于串行处理来说,并发事务处理能大大增加数据库资源的利用率,提高数据库系统的事务吞吐量,从而可以支持更多的用户。但并发事务处理也会带来一些问题,主要包括以下几种情况。
更新丢失(Lost Update):当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题--最后的更新覆盖了由其他事务所做的更新。例如,两个编辑人员制作了同一文档的电子副本。每个编辑人员独立地更改其副本,然后保存更改后的副本,这样就覆盖了原始文档。最后保存其更改副本的编辑人员覆盖另一个编辑人员所做的更改。如果在一个编辑人员完成并提交事务之前,另一个编辑人员不能访问同一文件,则可避免此问题。
脏读(Dirty Reads):一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做"脏读"。
不可重复读(Non-Repeatable Reads):一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫做“不可重复读”。
幻读(Phantom Reads):一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。
3.事务隔离级别
在上面讲到的并发事务处理带来的问题中,“更新丢失”通常是应该完全避免的。但防止更新丢失,并不能单靠数据库事务控制器来解决,需要应用程序对要更新的数据加必要的锁来解决,因此,防止更新丢失应该是应用的责任。
“脏读”、“不可重复读”和“幻读”,其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。数据库实现事务隔离的方式,基本上可分为以下两种。
一种是在读取数据前,对其加锁,阻止其他事务对数据进行修改。
另一种是不用加任何锁,通过一定机制生成一个数据请求时间点的一致性数据快照(Snapshot),并用这个快照来提供一定级别(语句级或事务级)的一致性读取。从用户的角度来看,好像是数据库可以提供同一数据的多个版本,因此,这种技术叫做数据多版本并发控制(MultiVersion Concurrency Control,简称MVCC或MCC),也经常称为多版本数据库。
4. 获取InnoDB行锁争用情况
可以通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况。
mysql> show status like 'innodb_row_lock%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| InnoDB_row_lock_current_waits | 0 |
| InnoDB_row_lock_time | 0 |
| InnoDB_row_lock_time_avg | 0 |
| InnoDB_row_lock_time_max | 0 |
| InnoDB_row_lock_waits | 0 |
+-------------------------------+-------+
5 rows in set (0.01 sec)
如果发现锁争用比较严重,如InnoDB_row_lock_waits 和 InnoDB_row_lock_time_avg的值比较高,还可以通过设置InnoDB Monitors来进一步观察发生锁冲突的表、数据行等,并分析锁争用的原因。
5. InnoDB的行锁模式及加锁方法
InnoDB实现了以下两种类型的行锁。
共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
另外,为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁(Intention Locks),
这两种意向锁都是表锁。
意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
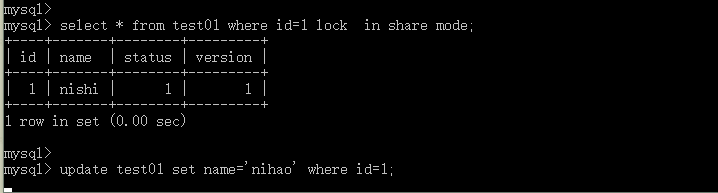
InnoDB存储引擎的共享锁例子: lock share in mode
对左边session加上共享锁,右边session仍然可以查询记录,并也可以对该记录加share mode的共享锁:

当左边session对锁定的记录进行更新操作,等待锁:
当右边sessionsession也对该记录进行更新操作,则会导致死锁退出,释放锁,左边session更新成功

InnoDB存储引擎的排他锁例子: for update
两个session都能获取数据

当左边session加入排它锁,右边其他session可以查询该记录,但是不能对该记录加排他锁,会等待获得锁:

当左边session执行更新操作并提交事务,右边session才能查询数据,并且是其他session提交的最新的数据

6. InnoDB行锁实现方式
InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过在数据块中对相应数据行加锁来实现的。
InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
在实际应用中,要特别注意InnoDB行锁的这一特性,不然的话,可能导致大量的锁冲突,从而影响并发性能。
6.1、在不通过索引条件查询的时候,InnoDB确实使用的是表锁,而不是行锁
InnoDB存储引擎的表在不使用索引时使用表锁例子,id是没有索引的



当查询条件是有索引的时候,只会锁行

6.2 由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,
但是如果是使用相同的索引键,是会出现锁冲突的。应用设计的时候要注意这一点。
InnoDB存储引擎使用相同索引键的阻塞例子
共享锁(s):又称读锁。允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
排他锁(X):又称写锁。允许获取排他锁的事务更新数据,阻止其他事务取得相同的数据集共享读锁和排他写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。
对于共享锁大家可能很好理解,就是多个事务只能读数据不能改数据。
对于排他锁大家的理解可能就有些差别,我当初就犯了一个错误,以为排他锁锁住一行数据后,其他事务就不能读取和修改该行数据,其实不是这样的。排他锁指的是一个事务在一行数据加上排他锁后,其他事务不能再在其上加其他的锁。mysql InnoDB引擎默认的修改数据语句:update,delete,insert都会自动给涉及到的数据加上排他锁,select语句默认不会加任何锁类型,如果加排他锁可以使用select …for update语句,加共享锁可以使用select … lock in share mode语句。所以加过排他锁的数据行在其他事务种是不能修改数据的,也不能通过for update和lock in share mode锁的方式查询数据,但可以直接通过select …from…查询数据,因为普通查询没有任何锁机制。
参考:https://www.liangzl.com/get-article-detail-1144.html