怎样实现一个无锁队列,网络上有很多的介绍,其中流传最广,影响最大的恐怕就属于以下两篇论文:
a) "Implementing lock free queue" by John.D.Valois
b) "Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms" by M.M. Michael & M.L. Scott。
很多基于链表的无锁队列的实现基本参考了该两篇论文里的算法,网络上也充斥着各种各样的文章,而在众多的文章中,Christian Hergert 的这篇:Introduction to lock-free/wait-free and the ABA problem(可能需要翻墙) 介绍了他基于 M.M.Michael & M.L.Scott 的论文,用 c++ 做的实现,后来被广泛流传。本文接下来的讨论,也基本来自上述三个出处, 站在巨人的肩膀上,容易看得更远。
前面两篇博客简单介绍了怎样基于数组来实现一个无锁的栈,虽然最后没能如愿写出一个满足理想条件的,但还好它们至少给了我们一些新的思路。现在我们就来探讨探讨怎样用链表来实现一个无锁队列,以下的计论均假设基于强类型的内存模型,所有的读写操作至少带有 acquire/release 语义,开始之前,先贴一张以链表为基础的队列图。
上面这个队列应该都不陌生,在 tail 指向的一端插入,在 head 指向的一端取出。有了前两篇博文的基础,对于这样的队列,理论上我们只要处理好 tail, head 两个指针及头尾两个结点就可以实现无锁了,事情看起来也比较简单,那现在我们来尝试写一个 Push 操作,先定义结点:
// list based queue
1 struct Node 2 { 3 Node* next; 4 void* data; 5 }; 6 7 static Node* tail = NULL; 8 static Node* head = NULL;
然后准备插入:
1 void Push(void* data) 2 { 3 Node* old_tail; 4 Node* node = new Node(); 5 node->data = data; 6 7 do 8 { 9 old_tail = tail; 10 11 if (!cas(&tail, old_tail, node)) 12 continue 13 14 if (old_tail) 15 old_tail->next = node; 16 else 17 cas(&head, NULL, node); 18 19 break; 20 21 }while (1); 22 23 }
上面一段代码乍看起来好像没什么大问题,应该能正常工作吧??
--- 很遗憾,它是有问题的:
1) 首先是第 4 行,我们用 new 来分配节点,但是 new 这个操作本身很有可能是有锁的(如果你没重载它实现自己的分配方式),至少在标准库中这个 new 是有锁的,我们在一个无锁的操作里调用了有锁的函数,后面还有必要去展示你精妙的算法吗?
2) 第 15 行,我们的原意是想把尾结点指向我们新插入的结点,想法太单纯太一厢情愿,你怎么保证当你执行这个操作时,old_tail->next 这个语句中的 old_tail 指向的结点没有被别的线程所释放掉?设想一下,当你从 11 行执行完 CAS 操作后,当前线程就可能会被切换了出去,再被切换回来时,或许又是沧海桑田,或许 old_tail 已经不复存在了。
前面我说过,用链表来实现无锁队列,有几个麻烦问题要解决,上面这两个问题中关于 new 的使用就是其中一个,而这个问题已经有点儿类似于蛋生鸡还是鸡生蛋的问题了,所以最开始我就想着要不干脆避开动态内存分配的问题,用数组来试试,只是后面发现这不是一个可以躲避的问题,所以现在又老老实实跑回来。对于这个问题,目前来说,比较直接的解法方法是把分配节点的那套用另外的方法来实现,比如说用 tls(thread local storage),分配内存完全在线程内进行,不和别的线程竞争,这样就没必要用锁了,缺点是不好写出有好移值性的代码来,因为 tls 与平台,OS 相关。对于 tls 的使用,不熟悉的读者可以参考一下这篇文档, 我根据自己的需要,做了一个简单的封装,代码放这里。
对于上面提到的第二个问题, 我们再仔细看一下,old_tail 所指向的节点之所以有可能被释放,原因是它现在是在链表上,而任何在链表上的节点,都属于线程间的公共变量,随时有可能被某个线程取下来做其它事情,因此一定要避免直接在链表上修改某个节点,这种操作不能保证原子性及线程独有(exclusive)? 如果需要修改它,就先把它取下来,确保了它只属于当前线程,再进行相关的修改。
现在回到之前的问题,我们是不是应该像刚刚讨论的那样,直接把节点从链表上摘下来,修改完再放回去呢? 很显然不可行,因为节点一但取出来,我们很难再把它放回原来的位置了,而队列这个数据结构对结点顺序有严格要求,不应该因为我们的操作而导致里面的节点乱序。怎么办呢?John.D.Valois 在它的论文里介绍了一种做法,下图展示了他设计的链表的样子:
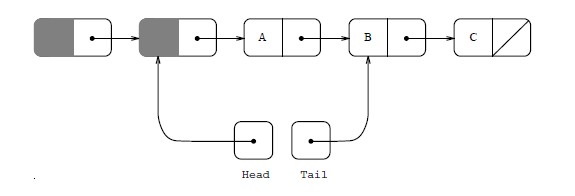
他的做法是引入一个 dummy 的头,head 指向这个 dummy 的头,链表中真正包含数据的结点由 dummy->next 指向。这个改进保证了,在进行 push 操作的时候,tail 指向的节点永远都是存在的(空队列的时候,指向 dummy 头), 因此也就避免了之前所遇到的问题, 除此之外,这个 dummy header 也使得在处理更空队列时,更加的容易。
Jobh.D.valois 算法伪代码如下:
1 Enqueue(x) 2 { 3 q = new record 4 q.value = x 5 q.next = NULL 6 7 do 8 { 9 p = tail 10 succ = cas(p.next, NULL, q) 11 if succ != true 12 cas(tail, p, p.next) 13 } while(succ == false) 14 15 cas(tail, p,q) 16 } 17 18 Dequeue 19 { 20 do 21 { 22 p = head 23 if p.next == NULL 24 return NULL 25 }while(false == cas(head, p, p.next) 26 27 return p.next.value 28 }
其中第 10 行是尝试把新节点挂到队列的尾巴上,这个操作有可能失败,因此用一个 while 来反复尝试,第 11,12 的代码是个很关键的两行,假设当前的线程 1 在第 10 行执行失败了,那证明已经有别的线程,假设为线程 2,成功把它的结点挂到了链表的尾端,正常情况下,线程 1 也没必要执行 11,12 行,但在某些情况下,如果不幸,线程 2 在把节点挂到链表的尾巴上后,还没有来得及更新 tail 指针时,就挂了。这时线程 1 执行 11,12 行就能帮助线程 2 把 tail 更新一下,否则线程 1 就只能一直在 while 里面一直打传了,这两行代码事实上保证了任何 push 操作都会在有限的时间内能完成。
上面的伪代码是算法的原始版本,John.D.valois 在论文里指出上面的第 11,12行虽然保证了任何 push 操作不会等太久,但有一个缺陷,在并发比较快的场景下,第 11,12 行可能会被反复执行,而 cas 操作相对是一个比较费时的操作,因此这里的效率相对受影响,回头仔细再想想,第 11,12 行那么费劲,只是为了更新一下 tail 指针,这个是有必要的吗?是不是 tail 如果不指向最后的节点,就没法完成插入了呢?
答案是否定的,tail 不必随时都指着尾巴,我们之所以固定思维地觉得一定要 tail 指向尾巴,不过是因为我们插入新节点时,总是需要在尾巴的后面,但是我们忘了,tail 即使不指向尾巴,我们可以也是可以找到尾巴节点的:顺着 tail->next 往下搜索不就行了吗,于是得到如下的改进:
1 Enqueue 2 { 3 q = new record 4 q.value = x 5 q.next = NULL 6 7 p = tail 8 oldp = p 9 10 do 11 { 12 13 while( p.next != NULL) 14 p = p.next 15 16 } while(cas(p.next, NULL, q) == false) 17 18 cas(tail, oldp, q) 19 }
其中第 13,14 行就是为找到最尾巴上的节点,注意此时的 tail 并不一定是指向最后一个节点的。改进的版本减少了对 cas 的使用,而把大部分时间花在找尾巴节点上了,但是有研究表明,这个找节点的循环不会太长,假如当前有 p 个线程在 enqueue,那 tail 离尾巴最多就隔着 2p-1 个节点,具体的证明可以参看原论文,不难理解。
到目前为止,一切看起来都还好,仿佛实现一个无锁队列马上就能完成了,现在我们来看看别人是怎么做的,根据 John.D.Valois 的论文,Christian Hergert 在他的博客中用 c++ 实现了一个版本,代码如下:
1 typedef struct _Node Node; 2 typedef struct _Queue Queue; 3 4 struct _Node { 5 void *data; 6 Node *next; 7 }; 8 9 struct _Queue { 10 Node *head; 11 Node *tail; 12 }; 13 14 Queue* 15 queue_new(void) 16 { 17 Queue *q = g_slice_new(sizeof(Queue)); 18 q->head = q->tail = g_slice_new0(sizeof(Node)); 19 return q; 20 } 21 22 void 23 queue_enqueue(Queue *q, gpointer data) 24 { 25 Node *node, *tail, *next; 26 27 node = g_slice_new(Node); 28 node->data = data; 29 node->next = NULL; 30 31 while (TRUE) { 32 tail = q->tail; 33 next = tail->next; // 改为 q->tail->next 会更好 34 if (tail != q->tail) 35 continue; 36 37 if (next != NULL) { 38 CAS(&q->tail, tail, next); 39 continue; 40 } 41 42 if (CAS(&tail->next, null, node) // 应改为 CAS(&q->tail->next, null, node) 43 break; 44 } 45 46 CAS(&q->tail, tail, node); 47 } 48 49 gpointer 50 queue_dequeue(Queue *q) 51 { 52 Node *node, *tail, *next; 53 54 while (TRUE) { 55 head = q->head; 56 tail = q->tail; 57 next = head->next; // 应改为 q->head->next 58 if (head != q->head) 59 continue; 60 61 if (next == NULL) 62 return NULL; // Empty 63 64 if (head == tail) { 65 CAS(&q->tail, tail, next); // next 不空,head == tail, 即 tail 并没有指向真正的尾巴 66 continue; 67 } 68 69 data = next->data; 70 if (CAS(&q->head, head, next)) 71 break; 72 } 73 74 g_slice_free(Node, head); // This isn't safe 75 return data; 76 }
上面的代码看起来和论文里的伪代码是完全一致的,前面我们一直在讨论 enqueue,现在我们来看 dequeue.
a) 有人可能注意到 33/57/69 行有问题,tail/head/next 有可能已经被释放了。确实有可能,33/57 行的问题好解决(纯粹只是写的不对,参看我的注释),69 行的问题却非常麻烦了,这个问题是实现 lock free queue 最难解决的问题之一:memory reclamation,但是这个问题在现代的操作系统中,也往往较难触发,比如在有 virtual memory 的系统中,上面的操作只是读取可能被 freed 掉的内存,而标准库对内存分配常常有缓冲处理,free 掉的内存并不一定会立即返回给 OS, 而且即使被返回 OS,只要相应的内存没有真正释放(如在 linux 中,unmap),哪怕这块内存再次被重新分配了,也是可以去读的,因此问题不容易出现,但问题仍然是存在的,因此不能存在绕幸的想法,想一想,用着一个明知有问题的东西,然后祈祷问题不会出现,那感觉,仿佛心里有只苍蝇。
b) 还有问题的地方是在第 70 行,这一行想要做什么呢?它的作用是把 dummy head 指向的节点取下来,看似比较简单的事情,但上面的代码在 c, c++ 中却是不安全的。。。当然,这个不安全不容易看出来, 现在我们看看这儿究竟怎么不安全。假设某时刻,队列如下:
Node1 -> node2 -> node3
假设线程 1,开始执行 dequeue, 在执行到 70 行时(还没开始 cas), 它被停下,切换了出去,此时线程 1 来说,第 70 行中,head, next 分别指向 node1, node2。
另一个线程 2,开始执行,然后它成功把 node1 pop 出去了,然后第 74 行,free(node1),它运气比较好,然后又把 node2,node3 也 Pop 出去了,此时队列为空!
然后又切换到线程 3,它要执行 enqueue 操作,此时它会在 27 行分配一个节点,坏事来了,如果十分巧合的情况下,它分配得到了线程 1 所 free 掉的 node1,enqueue 之后,队列成了如下样子:
Node1-> NULL
线程 3 执行完后,如果恰好又切换回线程 1,此时,对线程 1 来说,第 70 行中的 q->head == head == node1, 因此 cas 会成功!但是 next 呢?next 指向的是被释放掉的 node2! 严重问题!
这个就是无锁世界里所谓的 ABA 问题,这个问题就是我为什么最开始想尝试用数组来实现无锁操作的原因之二,而且,ABA 问题不容易解决。