all < index < range < ref < eq_ref < const(system) < Null
全表 < index < 辅助索引 < 多表辅助索引 < primary key/unique < Null
查看使用的索引类型
desc select * from test;
>>> 可能走的索引类型 索引数据类型长度*****
id 选择类型 表名 分区 索引类型 索引名
--------------------------------------------------------------------------------------------------------------------------------------------
1、索引数据类型长度计算:
utf8:
char(4) 每个字符最大预留长度3个字节 4*3 再加一个空或非空的标识符占一个字节 4*3+1=13个字节 ken_len=13
varchar(4) 最大预留3个字节, 4*3 varchar是变长类型 1个开始1个结束一个空或非空标识 4*3+3个字节 ken_len=15
utf8_mb4:
char(4) 预留4个字节,加1个非空标识字节
varchar(4) 预留4个字节,加3个标识字节
2、如果是联合索引
index(a,b,c,d)
select * from test where a=1 and b=2 and c=3 and d=4;
走全辅助索引,utf8下 "char(1)的key_len=16, varchar(1) key_len=24"
3、联合索引只要所有列都用上,无关排列顺序,优化器会自动做查询条件的排列
abcd abdc cadb dbca... 都可以
4、 即时是联合索引ref,有时候也会走普通索引,且key_len会变化
utf8mb4 char(1)情况下 "varchar多加开头和结尾两个字节,其他一样的算法"
abcd type=ref ref=const,const,const,const key_len=20 四个辅助索引都用了,type=ref
abc type=ref ref=const,const,const key_len=15 只用了abc三个辅助索引,type=ref
adc type=ref ref=const key_len=5 只要不连续就只用了a的索引,ken_len也只算a的,type=ref
bcd type=index ref=NULL key_len=20 没有带a掉级成index,但是key_len全部算上了,不知
d type=index ref=NULL key_len=20 没有a掉级index,key_len也算四个,type=index
总结:建联合索引时 将唯一值多的列放在最左侧
对于不连续的联合索引,考虑是否新建联合
对于多子句联合索引应考虑列的出场顺序
index(name,age) desc select * from test where name='ruan' order by age;
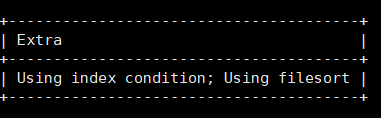 order by 如果有索引 也可以省略排序的过程,稍加性能
order by 如果有索引 也可以省略排序的过程,稍加性能
如果出现using filesort 说明在查询中有关排序的条件列列没有合理的应用索引
order by
group by
distinct
union/union all
--------------------------------------------------------------------------------------------------------------------------------------------
索引应用规范
1:建表必须要有主键,一般是无关列,自增长
2:经常做为where条件列,order by,group by,join on,distinct的条件
3:最好使用唯一值多的列作为联合索引前导列,其他的按照联合索引优化细节来做
4:列值长度较长的索引列,我们建议使用前缀索引 index(name(3))
5:降低索引条目,一方面不要创建没用索引,不常使用的索引清理,percona toolkit(xxxxxxx)
6:索引维护要避开业务繁忙期
7:小表不建索引
不走索引的情况
1:没有查询条件,或者查询条件没有建立索引
2:查询结果集是原表中的大部分数据,应该是25%以上
3:索引本身失效,统计数据不真实
面试题:同一条语句昨天用还好的,今天用速度突然变慢
在前一天进行大量数据更新,索引的统计信息过久,导致的索引失效
4:查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+-*/,!)等
5:隐式转换导致索引失败,比如char类型的数字 不加''引号查找,sql默认使用了函数进行转换为字符串
6:<>, not in 不走索引(辅助索引),主键将为index
7:like %aa% 百分号在前面不走索引,有大量这种需求可以考虑用ES数据库
8:联合索引的索引顺序问题