Node.js 修炼
node.js 官网 https://nodejs.org/zh-cn/
node.js API http://nodejs.cn/api/
笔记:
Javascript语言将任务的执行模式分成两种:同步(Synchronous)和异步(Asynchronous)。
"同步模式"就是上一段的模式,后一个任务等待前一个任务结束,然后再执行,程序的执行顺序与任务的排列顺序是一致的、同步的;"异步模式"则完全不同,每一个任务有一个或多个回调函数(callback),前一个任务结束后,不是执行后一个任务,而是执行回调函数,后一个任务则是不等前一个任务结束就执行,所以程序的执行顺序与任务的排列顺序是不一致的、异步的。

自己总结:即是一旦遇到node.js里面的含有回调函数的异步函数,他不会等你,就继续执行下面的代码,而异步函数里的它本职代码先执行完后,便后立即执行它自己的回调函数。因为异步函数自己+回调函数 ,这肯定需要一定的时间,所以异步函数下面的语句就不等你上面怎么样了,继续往下面执行
这一天的笔记与心得
res.end() 如果不写的话 小菊花会一直在转
write 不能再end后面
pathname : 就是不包括?后面的那一堆
nodejs.cn/api/url.html
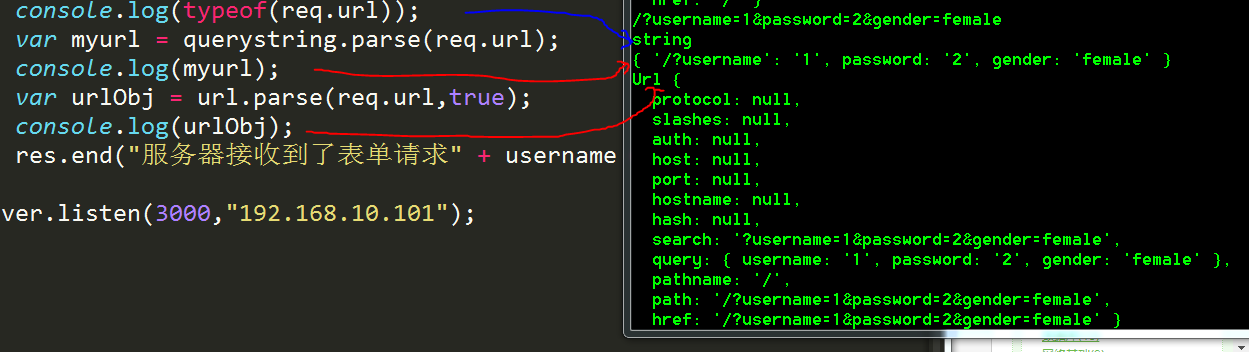
req.url 也就是/之后的东西 包括?name=sdsasdad
url.parse(req.url,true) 返回的是一个URL{protocol:null,hostname:null,query:{username:"1},pass:"2" }
原来返回的预计服务器返回数据类型 的正确性也会影响 err 和success
预计服务器返回数据类型与返回的数据类型 不相同时 ,ajax会执行err方法
在一个 HTML 文档中, 我们可以使用 .html() 方法来获取任意一个元素的内容。
假如ajax发送数据,而服务器不req.end()回响应他,那么它前端的ajax就会失败,过了段时间,它如果还没有得到相应,就会自动执行err方法
查找静态图片时或页面,如果我不写writeHead 那些,它浏览器好像也会自动识别
pathname 文件名
====================================================================
01: HelloWorld,最简单搭建一个服务器
02: 这个案例是个演示,不用研究。说明Node.js没有web容器的概念,呈递的静态文件和URL没有任何关系。
访问127.0.0.1/fang实际显示的是test文件夹中的xixi.html页面
访问127.0.0.1/yuan实际显示的是test文件夹中的haha.html页面
相应的图片,都要有自己的路由
03: req对象的end()方法、write()方法、writeHead()方法
04:req.url的演示,能够得到用户的请求的地址
05:url模块很好用,里面有url.parse()方法,能够将url拆分成为很多部分。
06:接收表单GET提交的模拟,可以得到表单提交上来的name、age、sex。表单是test文件夹中的form.html
07:当用户访问/student/1234567890 的查询此学号的学生信息。
当用户方位/teacher/645433 的时候,查询此老师的信息
其他的,我们提示错误。如果位数不对,也是提示位数不对
08: 这个案例,给每一个访问者加一个id,这样可以探究node事件环机制。
09: fs模块的mkdir函数,创建文件夹
10: fs模块的stat函数,检测文件状态。回调函数中的stats有isDirectory()方法,可以判断文件夹。
11: 失败案例。列出album文件夹中的所有子文件夹
12: 正确的读取所有文件夹的案例。强行把异步变成同步。
13:一个比较完整的静态资源案例。
笔记
Node.js不是一种独立的语言,与PHP、JSP、Python、Perl、Ruby的“既是语言,也是平台”不同,Node.js的使用JavaScript进行编程,运行在JavaScript引擎上(V8)。
● 与PHP、JSP等相比(PHP、JSP、.net都需要运行在服务器程序上,Apache、Naginx、Tomcat、IIS。
),Node.js跳过了Apache、Naginx、IIS等HTTP服务器,它自己不用建设在任何服务器软件之上。Node.js的许多设计理念与经典架构(LAMP = Linux + Apache + MySQL + PHP)有着很大的不同,可以提供强大的伸缩能力。一会儿我们就将看到,Node.js没有web容器。
特点
所谓的特点,就是Node.js是如何解决服务器高性能瓶颈问题的。
1.单线程
在Java、PHP或者.net等服务器端语言中,会为每一个客户端连接创建一个新的线程。而每个线程需要耗费大约2MB内存。也就是说,理论上,一个8GB内存的服务器可以同时连接的最大用户数为4000个左右。要让Web应用程序支持更多的用户,就需要增加服务器的数量,而Web应用程序的硬件成本当然就上升了。
Node.js不为每个客户连接创建一个新的线程,而仅仅使用一个线程。当有用户连接了,就触发一个内部事件,通过非阻塞I/O、事件驱动机制,让Node.js程序宏观上也是并行的。使用Node.js,一个8GB内存的服务器,可以同时处理超过4万用户的连接。
另外,带线程的带来的好处,还有操作系统完全不再有线程创建、销毁的时间开销。
坏处,就是一个用户造成了线程的崩溃,整个服务都崩溃了,其他人也崩溃了。
**2.非阻塞I/O non-blocking I/O **
例如,当在访问数据库取得数据的时候,需要一段时间。在传统的单线程处理机制中,在执行了访问数据库代码之后,整个线程都将暂停下来,等待数据库返回结果,才能执行后面的代码。也就是说,I/O阻塞了代码的执行,极大地降低了程序的执行效率。
由于Node.js中采用了非阻塞型I/O机制,因此在执行了访问数据库的代码之后,将立即转而执行其后面的代码,把数据库返回结果的处理代码放在回调函数中,从而提高了程序的执行效率。
当某个I/O执行完毕时,将以事件的形式通知执行I/O操作的线程,线程执行这个事件的回调函数。为了处理异步I/O,线程必须有事件循环,不断的检查有没有未处理的事件,依次予以处理。
阻塞模式下,一个线程只能处理一项任务,要想提高吞吐量必须通过多线程。而非阻塞模式下,一个线程永远在执行计算操作,这个线程的CPU核心利用率永远是100%。所以,这是一种特别有哲理的解决方案:与其人多,但是好多人闲着;还不如一个人玩命,往死里干活儿。
3.事件驱动event-driven
在Node中,客户端请求建立连接,提交数据等行为,会触发相应的事件。在Node中,在一个时刻,只能执行一个事件回调函数,但是在执行一个事件回调函数的中途,可以转而处理其他事件(比如,又有新用户连接了),然后返回继续执行原事件的回调函数,这种处理机制,称为“事件环”机制。
Node.js底层是C++(V8也是C++写的)。底层代码中,近半数都用于事件队列、回调函数队列的构建。用事件驱动来完成服务器的任务调度,这是鬼才才能想到的。针尖上的舞蹈,用一个线程,担负起了处理非常多的任务的使命。
总结
单线程,单线程的好处,减少了内存开销,操作系统的内存换页。
如果某一个事情,进入了,但是被I/O阻塞了,所以这个线程就阻塞了。
非阻塞I/O, 不会傻等I/O语句结束,而会执行后面的语句。
非阻塞就能解决问题了么?比如执行着小红的业务,执行过程中,小刚的I/O回调完成了,此时怎么办??
事件机制,事件环,不管是新用户的请求,还是老用户的I/O完成,都将以事件方式加入事件环,等待调度。
说是三个特点,实际上是一个特点,离开谁都不行,都玩儿不转了。
Node.js很像抠门的餐厅老板,只聘请1个服务员,服务很多人。结果,比很多服务员效率还高。
Node.js中所有的I/O都是异步的,回调函数,套回调函数。
适合开发什么?
Node.js适合用来开发什么样的应用程序呢?
善于I/O,不善于计算。因为Node.js最擅长的就是任务调度,如果你的业务有很多的CPU计算,实际上也相当于这个计算阻塞了这个单线程,就不适合Node开发。
当应用程序需要处理大量并发的I/O,而在向客户端发出响应之前,应用程序内部并不需要进行非常复杂的处理的时候,Node.js非常适合。Node.js也非常适合与web socket配合,开发长连接的实时交互应用程序。
比如:
● 用户表单收集
● 考试系统
● 聊天室
● 图文直播
● 提供JSON的API(为前台Angular使用)
HTTP模块
2 var http = require("http");
3 //创建服务器,参数是一个回调函数,表示如果有请求进来,要做什么
4 var server = http.createServer(function(req,res){
5 //req表示请求,request; res表示响应,response
6 //设置HTTP头部,状态码是200,文件类型是html,字符集是utf8
7 res.writeHead(200,{"Content-type":"text/html;charset=UTF-8"});
8 res.end("哈哈哈哈,我买了一个iPhone" + (1+2+3) + "s");
9 });
10
11 //运行服务器,监听3000端口(端口号可以任改)
12 server.listen(3000,"127.0.0.1");
Node.js没有根目录的概念,因为它根本没有任何的web容器!
让node.js提供一个静态服务,都非常难!
也就是说,node.js中,如果看见一个网址是
1 127.0.0.1:3000/fang
别再去想,一定有一个文件夹,叫做fang了。可能/fang的物理文件,是同目录的test.html
URL和真实物理文件,是没有关系的。URL是通过了Node的顶层路由设计,呈递某一个静态文件的。
==========
我们现在来看一下req里面能够使用的东西。
最关键的就是req.url属性,表示用户的请求URL地址。所有的路由设计,都是通过req.url来实现的。
我们比较关心的不是拿到URL,而是识别这个URL。
识别URL,用到两个新模块,第一个就是url模块,第二个就是querystring模块
字符串查询,用querystring处理
1 querystring.parse('foo=bar&baz=qux&baz=quux&corge')
2 // returns
3 { foo: 'bar', baz: ['qux', 'quux'], corge: '' }
4
5 // Suppose gbkDecodeURIComponent function already exists,
6 // it can decode gbk encoding string
7 querystring.parse('w=%D6%D0%CE%C4&foo=bar', null, null,
8 { decodeURIComponent: gbkDecodeURIComponent })
9 // returns
10 { w: '中文', foo: 'bar' }