【GiantPandaCV导语】知识蒸馏结合NAS的一篇工作,提出了DNA,让教师网络来指导超网的学习。这个工作将知识蒸馏非常深入的融合在一起,有很强的创新性,已被CVPR20接收。
1. 背景介绍
知识蒸馏通常作为One-Shot NAS中的一个训练技巧,但是他起到非常大的作用。
简便起见,知识蒸馏在这里被分为四类:
-
基于softmax输出层的知识蒸馏
-
基于中间层的知识蒸馏
-
基于相关性知识的知识蒸馏
-
基于GAN的知识蒸馏
第一个基于softmax输出层的知识蒸馏是最传统的,Hinton提出来的蒸馏方法可以视为soft label蒸馏。
第二个基于中间层的知识蒸馏一般使用教师网络特征图作为指导层,指导对应学生网络的特征图。
- OFA中蒸馏操作
OFA中使用了Progressive Shrinking的策略,先训练好最大的网络,结合inplace distillation策略进行训练。所谓inplace distillation指没有使用hard label,仅使用教师网络提供的soft label进行训练。
- BigNAS中蒸馏操作
为了简便性,和OFA中蒸馏操作一致,但是使用了三明治法则进行训练。
- Cream of the Crop中的蒸馏操作
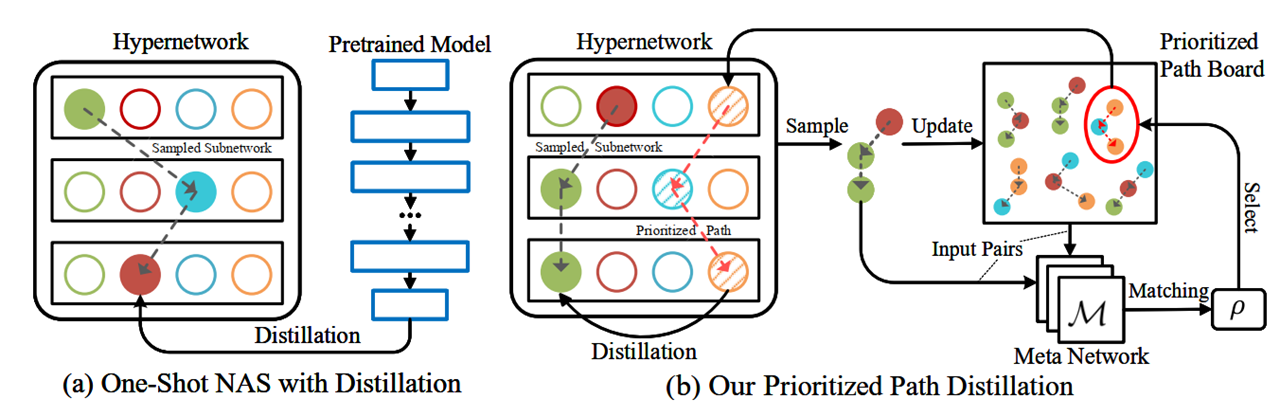
在知识蒸馏中,如果教师网络和学生网络相差比较大,那学生可能很难学习到合适的知识。基于这个Motivation,Cream of the Crop探索了为学生找到合适教师的方法:
-
提出了优先路径board用于保存优先路径,其中维护了一组最优路径。
-
Meta Network则用于根据学生网络从优先路径board中匹配合适的教师网络。
本文介绍的DNA实际上属于“基于中间层的知识蒸馏”,使用教师网络的中间层输出对学生网络的中间输出进行监督,细粒度引导学生网络的学习过程。本文贡献如下:
-
提出将NAS搜索空间模块化,搜索对象是不同的block。确保所有潜在候选架构能够被平等地训练,降低两阶段单次神经网络结构搜索中排序失序问题(本文称其为表征迁移问题)
-
提出网络模型的知识不仅仅体现在网络参数中,还体现于网络结构中。
-
性能 超过了SCARLETNAS和ProxylessNAS,取得了SOTA。
2. DNA
2.1 蒸馏训练过程
一般情况下,基于中间层的知识蒸馏中,学生模型的每个block输入是来自自身上一个block的输出。但是DNA受RNN顺序训练带来的低效性的启发,提出并行化训练block。
Student SuperNet设计思路:

block-wise 的设计引用了一篇1985年的老论文,认为视觉皮层对应几个部分。所以DNA将SuperNet划分为相互独立的几个block。
蒸馏方法设计思路:
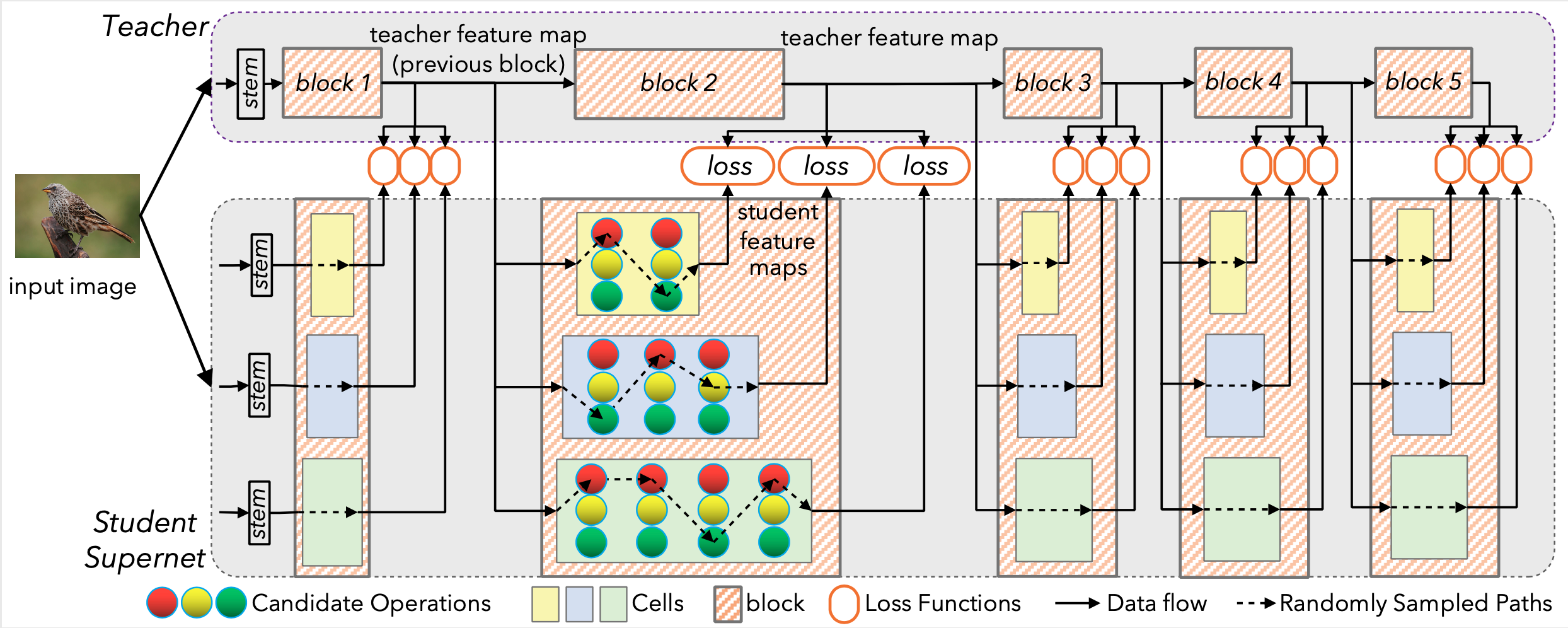
如上图所示,Student Supernet有几个block组成,值得注意的是,每个block的输入是教师网络的上一层输出,这样就可以独立训练Supernet每个block。
每个block的输出将教师网络中对应block的输出作为监督,这部分loss使用的是MSE,或者也可以使用KLConsineSimilarity的方法计算相似度。
Student Supernet和teacher的网络配置,其中教师网络使用的是efficientnet-b7, 学生网络基于MobileNetv2的SPOS-Like搜索空间。

2.2 搜索过程
在使用蒸馏方法将Student SuperNet训练完成后,需要完成对搜索子网络,找到相对性能最好的模型。
在DNA中,不使用传统的acc作为评价模型间相对性能的指标,而是通过计算学生网络模型输出和教师网络模型输出特征图间差距值作为评价标准。
但是由于不同层特征图大小不同,单纯使用MSE会导致不公平,所以引入了归一化参数,使用relative L1 loss:
具体采用的方法是深度优先搜索DFS:

在有约束情况下的搜索采用以下遍历搜索算法:
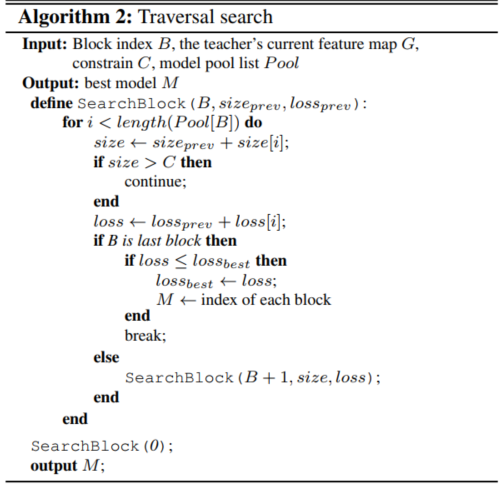
值得注意的是,使用DFS的过程中,树的每个中间结点的特征图会保存下来,从而可以加快评估过程。
3. 实验部分
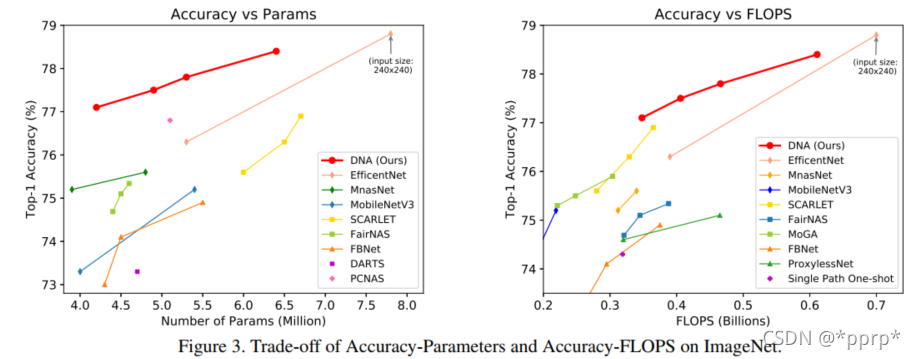
与SOTA的NAS模型比较(在224x224限制下已经效果不错了):
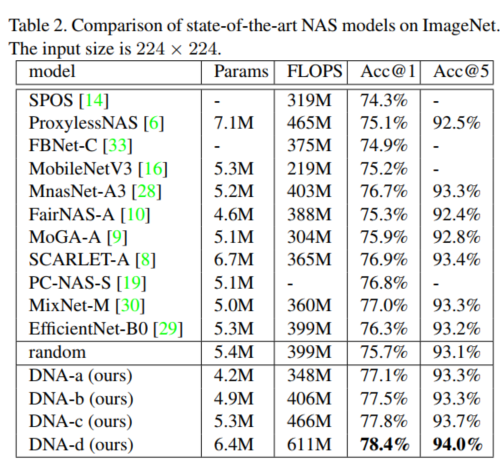
Accuracy vs Params 和 Accuracy vs FLOPS:
评估排序一致性:
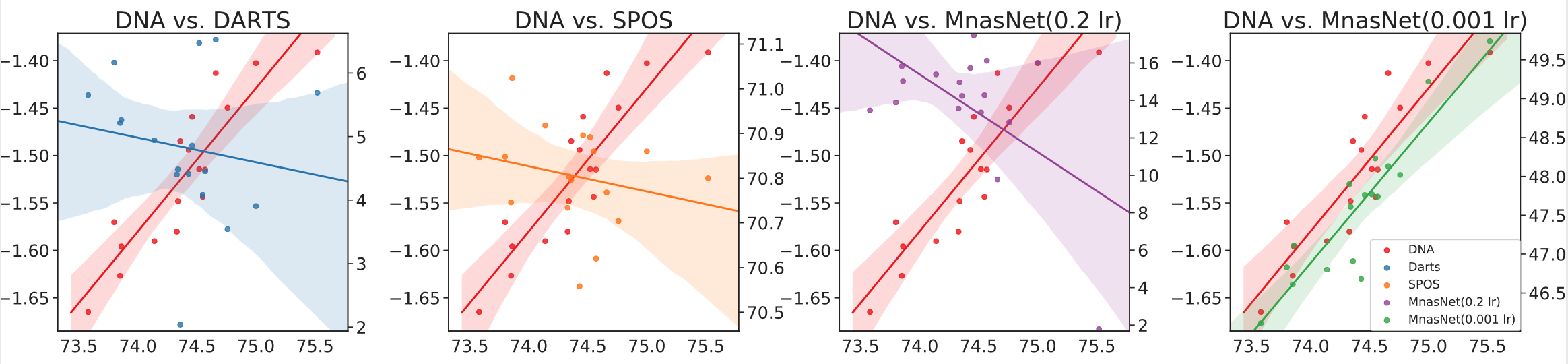
可以看出,使用这种评估标准得到的性能排序一致性更加可靠,除了MnasNet其他几种算法的排序一致性都很差。
4. 结论
本文是将NAS和知识蒸馏结合非常深入的工作,基于经典的SPOS架构,并使用block级别蒸馏方式,搜索得到的网络可以超过教师网络。同时本文抛弃了经典SPOS中将准确率作为评估指标的做法,通过衡量子图特征与教师网络特征的接近程度作为评判指标,有效提升了模型的排序一致性。
5. 参考文献
https://dblp.uni-trier.de/db/conf/cvpr/cvpr2020.html#LiPYWLLC20