首先用scala语言编辑Spark程序,通过SparkContext创建RDD

点击源码,发现地层创建了MapPartitionsRDD对象,描述信息为:通过第一个传入的函数,对这个RDD中的所有元素做运算,之后扁平结果集,返回一个新的RDD。

其中sc.clean(f)主要是做闭包检测。如果传入参数没问题的话返回值也是f:
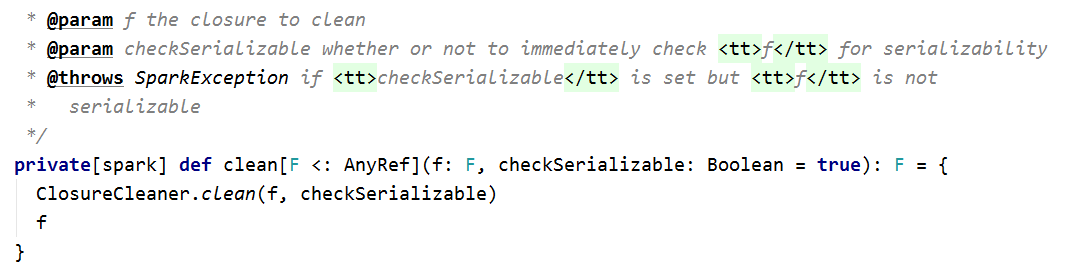
而Spark中的flatmap则是调用的iter的flatmap算子,与Scala不同,Scala中集合调用的flatmap是将数据先存入Mutable.Builder里面。再进行扁平化。