本节内容
- ORM介绍
- sqlalchemy安装
- sqlalchemy基本使用
- 多外键关联
- 多对多关系
- 表结构设计作业
1. ORM介绍
orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言
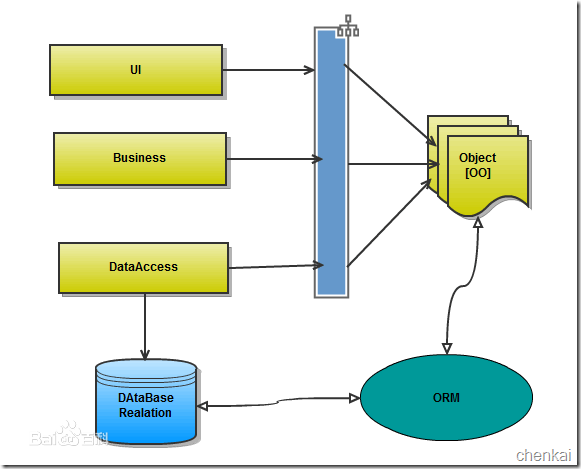
orm的优点:
- 隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。
- ORM使我们构造固化数据结构变得简单易行。
缺点:
- 无可避免的,自动化意味着映射和关联管理,代价是牺牲性能(早期,这是所有不喜欢ORM人的共同点)。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的。
2. sqlalchemy安装
在Python中,最有名的ORM框架是SQLAlchemy。用户包括openstack\Dropbox等知名公司或应用,主要用户列表http://www.sqlalchemy.org/organizations.html#openstack
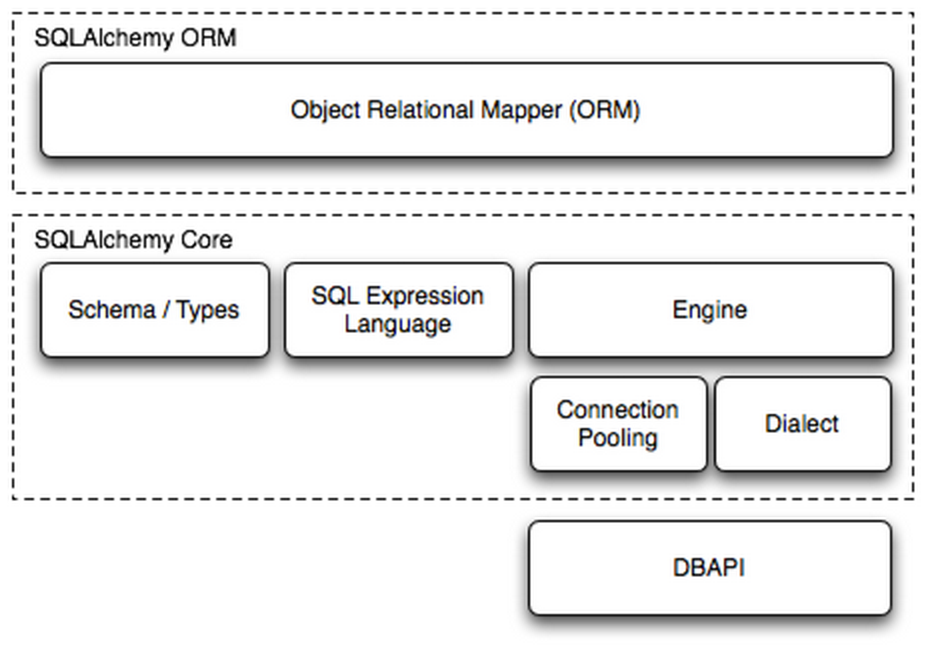
Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html
安装sqlalchemy
pip install SQLAlchem
3. sqlalchemy基本使用
mysql 创建表
CREATE TABLE user (
id INTEGER NOT NULL AUTO_INCREMENT,
name VARCHAR(32),
password VARCHAR(64),
PRIMARY KEY (id)
)
sqlalchemy 创建表
# !/usr/bin/env python
# _*_coding:utf-8_*_
# Author:Joker
import pymysql # 如果你链接的pymysql需要安装这个模块
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
engine = create_engine("mysql+pymysql://joker:123456@remoteip/lili",
encoding='utf-8', echo=True) # ECHO=TRUE就是会显示SQL语句
# MYSQL+接的MYSQL类型,用户密码地址库
Base = declarative_base() # 生成orm基类
class User(Base):
__tablename__ = 'user' # 表名
id = Column(Integer, primary_key=True) # COLUMN类型
name = Column(String(32))
password = Column(String(64))
def __repr__(self): # DJANGO的ORM
return self.name
Base.metadata.create_all(engine) # 创建表结构
除上面的创建之外,还有一种创建表的方式,虽不常用,但还是看看吧
from sqlalchemy import Table, MetaData, Column, Integer, String, ForeignKey
from sqlalchemy.orm import mapper
metadata = MetaData()
user = Table('user', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(50)),
Column('fullname', String(50)),
Column('password', String(12))
)
class User(object):
def __init__(self, name, fullname, password):
self.name = name
self.fullname = fullname
self.password = password
mapper(User, user) #the table metadata is created separately with the Table construct, then associated with the User class via the mapper() function
我们开始用orm创建数据
Session_class = sessionmaker(bind=engine) #创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例 Session = Session_class() #生成session实例 user_obj = User(name="joker",password="123456") #生成你要创建的数据对象 print(user_obj.name,user_obj.id) #此时还没创建对象呢,不信你打印一下id发现还是None Session.add(user_obj) #把要创建的数据对象添加到这个session里, 一会统一创建 print(user_obj.name,user_obj.id) #此时也依然还没创建 Session.commit() #现此才统一提交,创建数据
查询
my_user = Session.query(User).filter_by(name="joker").first() print(my_user)
得到的结果应该是个对象
<__main__.User object at 0x105b4ba90>
我擦,这是什么?这就是你要的数据呀, 只不过sqlalchemy帮你把返回的数据映射成一个对象啦,这样你调用每个字段就可以跟调用对象属性一样啦,like this.
print(my_user.id,my_user.name,my_user.password) 输出 1 joker 123456
不过刚才上面的显示的内存对象对址你是没办法分清返回的是什么数据的,除非打印具体字段看一下,如果想让它变的可读,只需在定义表的类下面加上这样的代码
def __repr__(self):
return "<User(name='%s', password='%s')>" % (
self.name, self.password)
修改
my_user = Session.query(User).filter_by(name="alex").first() my_user.name = "joker Li" Session.commit()
回滚
my_user = Session.query(User).filter_by(id=1).first() my_user.name = "Jack" fake_user = User(name='Rain', password='12345') Session.add(fake_user) print(Session.query(User).filter(User.name.in_(['Jack','rain'])).all() ) #这时看session里有你刚添加和修改的数据 Session.rollback() #此时你rollback一下 print(Session.query(User).filter(User.name.in_(['Jack','rain'])).all() ) #再查就发现刚才添加的数据没有了。 # Session # Session.commit()
获取所有数据
print(Session.query(User.name,User.id).all() )
多条件查询
objs = Session.query(User).filter(User.id>0).filter(User.id<7).all()
上面2个filter的关系相当于 user.id >1 AND user.id <7 的效果
统计
Session.query(User).filter(User.name.like("Ra%")).count()
分组
from sqlalchemy import func print(Session.query(User.name,func.count(User.name)).group_by(User.name).all()) 用户明,统计的数,按用户明分组 [(2, 'alex'), (1, 'joker')]
删除
Session.query(User).filter_by(id=1).delete() Session.commit()
fiter和fiter_by
都为过滤的意思,建议FITE(FITER关于类的值对),filter_by(NAME='joker')
filter(User.id>3) filter(User.id==3) filter(User.id>1).filter(User.id<3)
# !/usr/bin/env python
# _*_coding:utf-8_*_
# Author:Joker
import pymysql
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
engine = create_engine("mysql+pymysql://joker:123456@remoteip/lili",
encoding='utf-8', echo=True) # ECHO=TRUE就是会显示SQL语句
# MYSQL+接的MYSQL类型,用户密码地址库
Base = declarative_base() # 生成orm基类
class User(Base):
__tablename__ = 'user' # 表名
id = Column(Integer, primary_key=True) # COLUMN类型
name = Column(String(32))
password = Column(String(64))
def __repr__(self): # DJANGO的ORM
return self.name
Base.metadata.create_all(engine) # 创建表结构
# 创建数据
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=engine) # 游标 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例。SESSIONMAKE类PYMYSQL的CURSE
Session = Session_class() # 生成session实例 # 游标对象
# user_obj = User(name="alex", password="alex3714") # 生成你要创建的数据对象
# user_obj2 = User(name="alex2", password="alex3714") # 生成你要创建的数据对象
# print(user_obj.name, user_obj.id) # 此时还没创建对象呢,不信你打印一下id发现还是None
# print(user_obj2.name, user_obj2.id) # 此时还没创建对象呢,不信你打印一下id发现还是None
#
# Session.add(user_obj) # 把要创建的数据对象添加到这个session里, 一会统一创建
# Session.add(user_obj2) # 把要创建的数据对象添加到这个session里, 一会统一创建
# print(user_obj.name, user_obj.id) # 此时也依然还没创建
# print(user_obj2.name, user_obj2.id) # 此时也依然还没创建
# Session.commit() # 现此才统一提交,创建数据
# 查询不需要COMMIT
# data = Session.query(User).filter_by().all() # 是个列表,里面是对,FIRST()
# print(data[0].name,data[0].password)
# print(type(data[0]))
# filter_by与filter 都为过滤的意思,建议FITE(FITER关于类的值对),filter_by(NAME='ALEX')
# filter(User.id>3)
# filter(User.id==3)
# filter(User.id>1).filter(User.id<3)
# 修改,需要COMMIT
# data = Session.query(User).filter(User.id>2).first() # 是个列表,里面是对,FIRST()
# data.name = 'joker'
# Session.commit() # 现此才统一提交,创建数据
# 回滚
# my_user = Session.query(User).filter_by(id=1).first()
# my_user.name = "Jack"
#
# fake_user = User(name='Rain', password='12345')
# Session.add(fake_user)
#
# print(Session.query(User).filter(User.name.in_(['Jack', 'rain'])).all()) # 这时看session里有你刚添加和修改的数据
#
# Session.rollback() # 此时你rollback一下
#
# print(Session.query(User).filter(User.name.in_(['Jack', 'rain'])).all()) # 再查就发现刚才添加的数据没有了。
# 如果插入数据,ID会增大,插入删除一个意思
# 统计 大小写都可以匹配到
# print(Session.query(User).filter(User.name.in_(['Alex', 'rain'])).count()) # 2
# 分组
# from sqlalchemy import func
# print(Session.query(User.name,func.count(User.name)).group_by(User.name).all())
# 用户明,统计的数,按用户明分组
# [(2, 'alex'), (1, 'joker')]
# 删除
# Session.query(User).filter_by(id=1).delete()
# Session.commit()
# 自带事务
关联查询
手动绑定关联字段,进行查询
ret = Session.query(Student,User).filter(User.id==Student.id).all()
# !/usr/bin/env python
# _*_coding:utf-8_*_
# Author:Joker
# 我们上面有个一个人名,密码的表,咱们在创建一个学生表
import pymysql
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Enum, DATE
engine = create_engine("mysql+pymysql://joker:123456@remoteip/lili",
encoding='utf-8', echo=True) # ECHO=TRUE就是会显示SQL语句
# MYSQL+接的MYSQL类型,用户密码地址库
Base = declarative_base() # 生成orm基类
class Student(Base):
__tablename__ = 'student'
id = Column(Integer,primary_key=True)
name = Column(String(32),nullable=False)
register_date = Column(DATE,nullable=False)
gender = Column(Enum('M','F'),nullable=False)
def __repr__(self): # DJANGO的ORM
return self.name
class User(Base):
__tablename__ = 'user' # 表名
id = Column(Integer, primary_key=True) # COLUMN类型
name = Column(String(32))
password = Column(String(64))
def __repr__(self): # DJANGO的ORM
return self.name
# Base.metadata.create_all(engine) # 创建表结构
# 创建数据
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=engine) # 游标 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例。SESSIONMAKE类PYMYSQL的CURSE
Session = Session_class() # 生成session实例 # 游标对象
# s2 = Student(name='s2',register_date='2010-09-22',gender='M')
# Session.add(s2)
# Session.commit()
# one 关联查询
ret = Session.query(Student,User).filter(User.id==Student.id).all()
print(ret)
# [(s2, alex)]
# two 要有外键才能使用这种关系去查
ret = Session.query(User).join(Student).all() # 这样是报错的,因为创建的时候没有创建关联,他找不到这个关系例如上面 User.id==Student.id
# Session.commit()
外键关联
from sqlalchemy import Column, Integer, String, Enum, DATE, ForeignKey
from sqlalchemy.orm import relationship
class StudyRecord(Base):
__tablename__ = 'study_record'
id = Column(Integer, primary_key=True)
day = Column(Integer,nullable=False)
status = Column(String(32),nullable=False)
stu_id = Column(Integer,ForeignKey('student.id')) # 外键关联
student = relationship('Student', backref="my_study_record") # 这个nb,允许你在user表里通过backref字段反向查出所有它在addresses表里的关联项,内存里面的,并非在数据库里面有记录
# student就是相当于把类STUDENT拿过来做了个实例化student=Student()
def __repr__(self): # DJANGO的ORM
return "<%s day:%s status:%s>" % (self.student.name,self.day,self.status)
表创建好后,我们可以这样反查试试
stu_obj = Session.query(Student).filter(Student.name=='alex').first() print(stu_obj) # alex 上课记录 print(stu_obj.my_study_record) # [<Alex day:1 status:YES>, <Alex day:2 status:NO>, <Alex day:3 status:YES>]
# !/usr/bin/env python
# _*_coding:utf-8_*_
# Author:Joker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Enum, DATE, ForeignKey
from sqlalchemy.orm import relationship
engine = create_engine("mysql+pymysql://joker:123456@remoteip/lili",
encoding='utf-8', echo=True) # ECHO=TRUE就是会显示SQL语句
# MYSQL+接的MYSQL类型,用户密码地址库
Base = declarative_base() # 生成orm基类
class Student(Base):
__tablename__ = 'student'
id = Column(Integer,primary_key=True)
name = Column(String(32),nullable=False)
register_date = Column(DATE,nullable=False)
def __repr__(self): # DJANGO的ORM
return "<%s name:%s>" % (self.id,self.name)
class StudyRecord(Base):
__tablename__ = 'study_record'
id = Column(Integer, primary_key=True)
day = Column(Integer,nullable=False)
status = Column(String(32),nullable=False)
stu_id = Column(Integer,ForeignKey('student.id')) # 外键关联
student = relationship('Student', backref="my_study_record") # 这个nb,允许你在user表里通过backref字段反向查出所有它在addresses表里的关联项,内存里面的,并非在数据库里面有记录
# student就是相当于把类STUDENT拿过来做了个实例化student=Student()
def __repr__(self): # DJANGO的ORM
return "<%s day:%s status:%s>" % (self.student.name,self.day,self.status)
Base.metadata.create_all(engine)
# 创建数据
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=engine) # 游标 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例。SESSIONMAKE类PYMYSQL的CURSE
Session = Session_class()
# s1 = Student(name='Alex',register_date='2010-01-22')
# s2 = Student(name='Jack',register_date='2010-02-22')
# s3 = Student(name='Rain',register_date='2010-03-22')
# s4 = Student(name='Eric',register_date='2010-04-22')
#
# study_obj1 = StudyRecord(day=1,status='YES',stu_id=1)
# study_obj2 = StudyRecord(day=2,status='NO',stu_id=1)
# study_obj3 = StudyRecord(day=3,status='YES',stu_id=1)
# study_obj4 = StudyRecord(day=1,status='YES',stu_id=2)
#
#
#
#
# Session.add_all([s1,s2,s3,s4,study_obj1,study_obj2,study_obj3,study_obj4])
stu_obj = Session.query(Student).filter(Student.name=='alex').first()
print(stu_obj)
# alex 上课记录
print(stu_obj.my_study_record)
# [<Alex day:1 status:YES>, <Alex day:2 status:NO>, <Alex day:3 status:YES>]
# Session.commit()
常用查询语法
Common Filter Operators
Here’s a rundown of some of the most common operators used in filter():
-
equals:
query.filter(User.name == 'ed')
-
not equals:
query.filter(User.name != 'ed')
-
LIKE:
query.filter(User.name.like('%ed%'))
-
IN:
-
NOT IN:
query.filter(~User.name.in_(['ed', 'wendy', 'jack'])) -
IS NULL:
-
IS NOT NULL:
-
AND:
2.1. ObjectRelationalTutorial 17
query.filter(User.name.in_(['ed', 'wendy', 'jack']))
# works with query objects too:
query.filter(User.name.in_( session.query(User.name).filter(User.name.like('%ed%'))
))
query.filter(User.name == None)
# alternatively, if pep8/linters are a concern
query.filter(User.name.is_(None))
query.filter(User.name != None)
# alternatively, if pep8/linters are a concern
query.filter(User.name.isnot(None))
SQLAlchemy Documentation, Release 1.1.0b1
# use and_()
from sqlalchemy import and_
query.filter(and_(User.name == 'ed', User.fullname == 'Ed Jones'))
# or send multiple expressions to .filter()
query.filter(User.name == 'ed', User.fullname == 'Ed Jones')
# or chain multiple filter()/filter_by() calls
query.filter(User.name == 'ed').filter(User.fullname == 'Ed Jones')
Note: Makesureyouuseand_()andnotthePythonandoperator! • OR:
Note: Makesureyouuseor_()andnotthePythonoroperator! • MATCH:
query.filter(User.name.match('wendy'))
Note: match() uses a database-specific MATCH or CONTAINS f
4. 多外键关联
from sqlalchemy import Integer, ForeignKey, String, Column
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
Base = declarative_base()
class Customer(Base):
__tablename__ = 'customer'
id = Column(Integer, primary_key=True)
name = Column(String)
billing_address_id = Column(Integer, ForeignKey("address.id"))
shipping_address_id = Column(Integer, ForeignKey("address.id"))
billing_address = relationship("Address")
shipping_address = relationship("Address")
class Address(Base):
__tablename__ = 'address'
id = Column(Integer, primary_key=True)
street = Column(String)
city = Column(String)
state = Column(String)
创建表结构是没有问题的,但你Address表中插入数据时会报下面的错
sqlalchemy.exc.AmbiguousForeignKeysError: Could not determine join condition between parent/child tables on relationship Customer.billing_address - there are multiple foreign key paths linking the tables. Specify the 'foreign_keys' argument, providing a list of those columns which should be counted as containing a foreign key reference to the parent table.
解决方法
class Customer(Base):
__tablename__ = 'customer'
id = Column(Integer, primary_key=True)
name = Column(String)
billing_address_id = Column(Integer, ForeignKey("address.id"))
shipping_address_id = Column(Integer, ForeignKey("address.id"))
billing_address = relationship("Address", foreign_keys=[billing_address_id])
shipping_address = relationship("Address", foreign_keys=[shipping_address_id])
这样sqlachemy就能分清哪个外键是对应哪个字段了
5. 多对多关系
现在来设计一个能描述“图书”与“作者”的关系的表结构,需求是
- 一本书可以有好几个作者一起出版
- 一个作者可以写好几本书
此时你会发现,用之前学的外键好像没办法实现上面的需求了,因为

当然你更不可以像下面这样干,因为这样就你就相当于有多条书的记录了,太low b了,改书名还得都改。。。
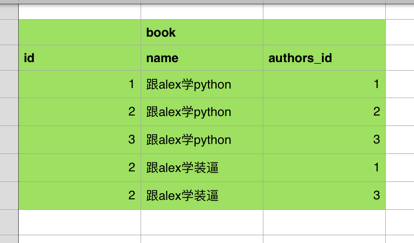
那怎么办呢? 此时,我们可以再搞出一张中间表,就可以了

这样就相当于通过book_m2m_author表完成了book表和author表之前的多对多关联
orm生成多对多关系
#一本书可以有多个作者,一个作者又可以出版多本书
from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
book_m2m_author = Table('book_m2m_author', Base.metadata,
Column('book_id',Integer,ForeignKey('books.id')),
Column('author_id',Integer,ForeignKey('authors.id')),
)
class Book(Base):
__tablename__ = 'books'
id = Column(Integer,primary_key=True)
name = Column(String(64))
pub_date = Column(DATE)
authors = relationship('Author',secondary=book_m2m_author,backref='books')
def __repr__(self):
return self.name
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
name = Column(String(32))
def __repr__(self):
return self.name
orm 多对多
接下来创建几本书和作者
Session_class = sessionmaker(bind=engine) #创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例 s = Session_class() #生成session实例 b1 = Book(name="跟Alex学Python") b2 = Book(name="跟Alex学把妹") b3 = Book(name="跟Alex学装逼") b4 = Book(name="跟Alex学开车") a1 = Author(name="Alex") a2 = Author(name="Jack") a3 = Author(name="Rain") b1.authors = [a1,a2] b2.authors = [a1,a2,a3] s.add_all([b1,b2,b3,b4,a1,a2,a3]) s.commit()
此时,手动连上mysql,分别查看这3张表,你会发现,book_m2m_author中自动创建了多条纪录用来连接book和author表
mysql> select * from books; +----+------------------+----------+ | id | name | pub_date | +----+------------------+----------+ | 1 | 跟Alex学Python | NULL | | 2 | 跟Alex学把妹 | NULL | | 3 | 跟Alex学装逼 | NULL | | 4 | 跟Alex学开车 | NULL | +----+------------------+----------+ 4 rows in set (0.00 sec) mysql> select * from authors; +----+------+ | id | name | +----+------+ | 10 | Alex | | 11 | Jack | | 12 | Rain | +----+------+ 3 rows in set (0.00 sec) mysql> select * from book_m2m_author; +---------+-----------+ | book_id | author_id | +---------+-----------+ | 2 | 10 | | 2 | 11 | | 2 | 12 | | 1 | 10 | | 1 | 11 | +---------+-----------+ 5 rows in set (0.00 sec)
此时,我们去用orm查一下数据
print('--------通过书表查关联的作者---------')
book_obj = s.query(Book).filter_by(name="跟Alex学Python").first()
print(book_obj.name, book_obj.authors)
print('--------通过作者表查关联的书---------')
author_obj =s.query(Author).filter_by(name="Alex").first()
print(author_obj.name , author_obj.books)
s.commit()
输出如下
--------通过书表查关联的作者--------- 跟Alex学Python [Alex, Jack] --------通过作者表查关联的书--------- Alex [跟Alex学把妹, 跟Alex学Python]
多对多删除
删除数据时不用管boo_m2m_authors , sqlalchemy会自动帮你把对应的数据删除
通过书删除作者
author_obj =s.query(Author).filter_by(name="Jack").first() book_obj = s.query(Book).filter_by(name="跟Alex学把妹").first() book_obj.authors.remove(author_obj) #从一本书里删除一个作者 s.commit()
直接删除作者
删除作者时,会把这个作者跟所有书的关联关系数据也自动删除
author_obj =s.query(Author).filter_by(name="Alex").first() # print(author_obj.name , author_obj.books) s.delete(author_obj) s.commit()
处理中文
sqlalchemy设置编码字符集一定要在数据库访问的URL上增加charset=utf8,否则数据库的连接就不是utf8的编码格式
eng = create_engine('mysql://root:root@localhost:3306/test2?charset=utf8',echo=True)
charset=utf8
6. 本节作业
主题:学员管理系统
需求:
- 用户角色,讲师\学员, 用户登陆后根据角色不同,能做的事情不同,分别如下
- 讲师视图
- 管理班级,可创建班级,根据学员qq号把学员加入班级
- 可创建指定班级的上课纪录,注意一节上课纪录对应多条学员的上课纪录, 即每节课都有整班学员上, 为了纪录每位学员的学习成绩,需在创建每节上课纪录是,同时 为这个班的每位学员创建一条上课纪录
- 为学员批改成绩, 一条一条的手动修改成绩
- 学员视图
- 提交作业
- 查看作业成绩
- 一个学员可以同时属于多个班级,就像报了Linux的同时也可以报名Python一样, 所以提交作业时需先选择班级,再选择具体上课的节数
- 附加:学员可以查看自己的班级成绩排名