目录:
- 编码的补充
- 文件操作
- 集合
- 函数的参数
- 函数的递归
- 匿名函数与高阶函数
- 二分查找示例
一、编码的补充:
在python程序中,首行一般为:#-*- coding:utf-8 -*-,就是告诉python解释器使用的字符编码类型来解释以下代码;
查看python默认的字编码命令:
>>> import sys >>> sys.getdefaultencoding() 'utf-8'
编码的转码:
不同国家的字符编码进行正常显示,先将机的字符编码转成unicode,读取时再将unicode转换成自己的字符编码;
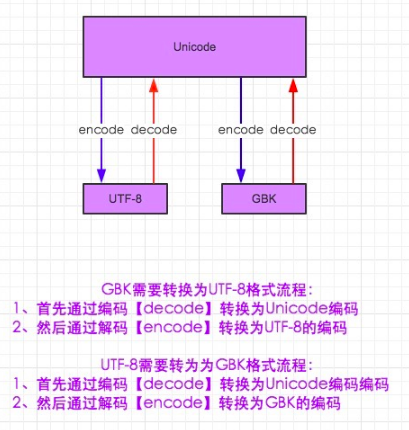
注:
windows默认支持gbk; 同时支持unicode与gbk
默认如果不是这两种会显示乱码;
python3中默认文件编码是utf-8,解释器默认编码是unicode,文件加载到内存后会自动解码成unicode; 同时把字符转换成bytes格式;
python3内存解释器默认由unicode运行;在硬盘文件中存储格式为utf-8;
在硬盘中文件加载到内存中,python3会自动解码成unicode;只需直接编码即可;
python2与python3中编码的区别:
python2 str == python3 bytes
python3 str == unicode
python3中的bytes格式是一个单独的数据类型;
python2在windows中解码是必须的,编码成gbk可不作操作;
python在linux中:
如果为utf-8 --> gbk,则显示乱码;
如果为gbk --> utf-8,则必须解码,解码可不操作;
linux默认支持utf-8与unicode;
所有程序在内存里默认都是unicode,一般情况下都不需要解码;只有在保存文件时才会用到;
二、文件操作
- 打开文件模式:
r: 只读模式(默认)
w: 只写模式(不可读,不存在则创建,存在则删除内容;)
a: 追加模式(可读,不存在则创建,存在则只内容;)
r+: 读写模式
相当于追加模式;相比较a,r+表示追加+读
可以定长修改;文件开头改
w+: 写读模式
会先清空原文件内容,再写入新内容;
a+: 追加写模式
可文件尾部改;
rU:
将
自动转换成
;
rb:
二进制的模式读取;不进行转码与编码,直接打印字节类型;
主要用于网络传输;有助于解决乱码问题;bytes对应于ascii里面的数字;最后需要再解码;
以二进制模式打开文件,不能声明encoding
示例:
>>> a = bytes('abc',encoding='utf-8')
>>> a
b'abc'
>>> a[0]
97
>>> a[1]
98
wb:
在写入的时候,必须编码:f.write('城'.encode('gbk'))
以二进制写入文件,必须写入bytes格式;
- 文件打开方法:
open() encoding如果不声时,默认使用操作系统的编码来解释文件; f.tell() 返回光标位置; f.seek(10) 移动光标到第10个字节 print(f.read(5)) 表示读取5个字符; 注: 一个汉字占三个字节;f.seek(10)移动的是字节;f.read(5)读的是字符; f.fileno() 返回一个nummber,number是操作系统里所有打开的文件的一个下标;又称为文件描述符; f.isatty() 判断是否为一个终端;
示例: >>> import sys >>> sys.stdout.write('fsdjklj') fsdjklj7 #数字表示显示打印了几个字符; f.read(): 文件内容全部读完 f.readable() 判断文件是否可读 f.readall() 读所有 f.seekable() seek只适用于文本文件; f.truncate() 用于r+或a+;表示默认从开头进行截断;结果在文件中显示;不能使用seek在某一位置截断; f.flush() 将内存缓存区中的文件内容刷写到文件中去;常用于打印实时日志时;
三、集合:
定义一个集合:
name = {} #与字典近似
特性:
去重、无序、关系运算;无索引
示例:
>>> name = {1,2,3,4,5,4,3,2,1}
>>> print(name)
{1, 2, 3, 4, 5}
功能:
name.copy()
name.add(111) #有则不添加
name.remove(9)
交集:
示例:
>>> a = {1,3,5,7,10}
>>> b = {2,3,4,5,6,8}
>>> print(a & b)
{3, 5}
差集:
示例:
>>> a = {1,3,5,7,10}
>>> b = {2,3,4,5,6,8}
>>> print(b - a)
{8, 2, 4, 6}
并集:取出一共有多少个人?
示例:
>>> a = {1,3,5,7,10}
>>> b = {2,3,4,5,6,8}
>>> print(a | b)
{1, 2, 3, 4, 5, 6, 7, 8, 10}
对称差集:
示例:
>>> a = {1,3,5,7,10}
>>> b = {2,3,4,5,6,8}
>>> print(a ^ b)
{1, 2, 4, 6, 7, 8, 10}
集合的方法:
a.intersection(b) 取交集 a.difference(b) 取差集 a.union(b) 取并集 a.symetric_difference() 对称差集或反差集 a.intersection_update(b) print(a) a = a.intersection(b) a.issubset(b) a是不是b的子集; a.issuperset(b) a是不是b的副集;
四、函数的参数:
Pythond 的函数是由一个新的语句编写,即def,def是可执行的语句--函数并不存在,直到Python运行了def后才存在。
函数是通过赋值传递的,参数通过赋值传递给函数
def语句将创建一个函数对象并将其赋值给一个变量名,def语句的一般格式如下:
函数代码结构:
def function_name(arg1,arg2[,...]): statement [return value]
优点:
易扩展、易维护、代码少;
局限性:
不能适用于所有场景;解决不了复杂问题;
return:
返回值;用于被外部调用;return只能返回一个值,如果为多个值会以一个元组形式返回,当成一个值;
作用:
代表函数的结束;
返回函数结果;
函数两个位置参数:
形参:
函数调用结整个后则即刻释放内存单元,形参只在函数内部有效,函数调用结束则不能再使用该形参;
(只有在被调用时才分配内存,调用结束后,立刻释放内存,值仅在函数内部有效;(可以称其为局部变量;形参的作用域只在当前函数内部;))
实参:
有确定值的参数,所有的数据类型都可以被当做参数传递给函数,
局部变量:
作用域只在当前函数内部,外部变量默认不能被函数内部修改,只能引用;
如果要在函数里修改全局变量,必须global,但不建议使用global;使用global会增加代码debug的难度;

注:
函数内部是可以修改列表、字典、集合、实例等;
位置参数:
按顺序;
默认参数:
默认参数必须放在形参中位置参数的后面;
关键字参数:
正常情况下,给函数传参数要按顺序,只要指定参数名即可;
放在实参中:如age=22,name=alex
运行代码: def fun(a,b,c): print("a:{0},b:{1},c:{2}".format(a,b,c)) fun(1,2,3) # 位置参数传递 fun(a=2,c=1,b=3) #关键参数传递 fun(1,c=5,b=2) #位置参数与关键参数同时传递 运行结果: a:1,b:2,c:3 a:2,b:3,c:1 a:1,b:2,c:5
非固定参数:(放在形参中的最后)
*args = ()
以位置参数的形式传入,以元组形式输出;打印时在def中print(args)打印时不加*
**kwargs = {}
以关键字参数形式传入,以字典形式输出;打印时在def中print(kwargs)打印时不加*
运行代码: def fun(a,b,*args,**kwargs): print("a:{0},b:{1}".format(a,b)) print(args) print(kwargs) fun(1,2,3,'a','b',4,5,6,c=1) 运行结果: a:1,b:2 (3, 'a', 'b', 4, 5, 6) {'c': 1} # *args表示非关键字参数,**kwargs表示关键字参数;
五、函数的递归:
在函数内部,可以调用其他函数,如果一个函数内部调用自身本身,这个函数就是递归函数;
注:
如果没有判断或return就是进入死循环;
函数如果没有return就会返回None
递归的特性:
1、必须有一个明确的结束条件;
2、每次进入更深一层递归时,问题规模相比上次递归都应有所减少;
3、递归的效率不高,递归层次过多会导致栈溢出,栈的大小一般为2M;
示例:
运行代码: def cacl(n): print(n) if n//2 > 0: cacl(n//2) # return n cacl(10) 运行结果: 10 5 2 1
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
六、高阶函数:
1、把一个函数的内存地址当做参数传给另外一个函数;
2、一个函数把另外一个函数当做返回值返回;


运行代码: def add(x,y,f): return f( x)+ f( y) print add(-18,11,abs) 运行过程: abs(-18) + abs(11) 运行结果: 29
高阶函数中的map():
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。
七、匿名函数:
在python中有一个匿名函数lambda,匿名函数顾名思义就是指:是指一类无需定义标识符(函数名)的函数或子程序。最早引入匿名函数的是LISP语言,LISP是最早的函数编程式语言,我们使用的Vim的插件大部分都是使用LISP语言进行编写的,后来又派生出Emacs Lisp,Emacs的扩展插件就是使用Lisp编写的。在C++11和C#中都有匿名函数的存在。下面看看在python中匿名函数的使用。
函数: def calc(n): return n ** n print(calc(10)) 匿名函数: calc = lambda n: n ** n print(calc(10)) # 相对于函数来说,匿名函数在使用上要简洁一些,但匿名函数只能实现一些相对简单的功能;
如在高阶函数中提到的map()方法;可与匿名函数实现一些较复杂的功能:
运行代码: res = map(lambda x:x**2,[1,5,7,4,8]) for i in res: print(i) 运行结果: 1 25 49 16 64
八、二分算法:
二分查找也叫折半查找,通过不断比较目标元素与一个有序序列(注意是有序序列)中间元素的值,达到每次查找都能排除一半元素的一种算法。
代码实现:
运行代码: data = range(0,1000000000000) def search(find_str,num,count): mid = len(num) // 2 if mid < 0: print('is nothing') return if num[mid] == find_str: print('got',find_str,count+1) elif num[mid] > find_str: print('got in left',find_str,num[0:mid],count+1) search(find_str, num[0:mid],count+1) else: print('got in right',find_str,num[mid+1:],count+1) search(find_str, num[mid + 1:],count+1) search(151200000653,data,0) 运行结果: got in left 151200000653 range(0, 500000000000) 1 got in left 151200000653 range(0, 250000000000) 2 got in right 151200000653 range(125000000001, 250000000000) 3 got in left 151200000653 range(125000000001, 187500000000) 4 got in left 151200000653 range(125000000001, 156250000000) 5 got in right 151200000653 range(140625000001, 156250000000) 6 got in right 151200000653 range(148437500001, 156250000000) 7 got in left 151200000653 range(148437500001, 152343750000) 8 got in right 151200000653 range(150390625001, 152343750000) 9 got in left 151200000653 range(150390625001, 151367187500) 10 got in right 151200000653 range(150878906251, 151367187500) 11 got in right 151200000653 range(151123046876, 151367187500) 12 got in left 151200000653 range(151123046876, 151245117188) 13 got in right 151200000653 range(151184082033, 151245117188) 14 got in left 151200000653 range(151184082033, 151214599610) 15 got in right 151200000653 range(151199340822, 151214599610) 16 got in left 151200000653 range(151199340822, 151206970216) 17 got in left 151200000653 range(151199340822, 151203155519) 18 got in left 151200000653 range(151199340822, 151201248170) 19 got in left 151200000653 range(151199340822, 151200294496) 20 got in right 151200000653 range(151199817660, 151200294496) 21 got in left 151200000653 range(151199817660, 151200056078) 22 got in right 151200000653 range(151199936870, 151200056078) 23 got in right 151200000653 range(151199996475, 151200056078) 24 got in left 151200000653 range(151199996475, 151200026276) 25 got in left 151200000653 range(151199996475, 151200011375) 26 got in left 151200000653 range(151199996475, 151200003925) 27 got in right 151200000653 range(151200000201, 151200003925) 28 got in left 151200000653 range(151200000201, 151200002063) 29 got in left 151200000653 range(151200000201, 151200001132) 30 got in left 151200000653 range(151200000201, 151200000666) 31 got in right 151200000653 range(151200000434, 151200000666) 32 got in right 151200000653 range(151200000551, 151200000666) 33 got in right 151200000653 range(151200000609, 151200000666) 34 got in right 151200000653 range(151200000638, 151200000666) 35 got in right 151200000653 range(151200000653, 151200000666) 36 got in left 151200000653 range(151200000653, 151200000659) 37 got in left 151200000653 range(151200000653, 151200000656) 38 got in left 151200000653 range(151200000653, 151200000654) 39 got 151200000653 40