| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | 熟悉对 Git / Github 的使用,锻炼编程能力和自主解决问题的手腕,直接越级挑战 |
| 学号 | 031802506 |
目录
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 180 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 60 | 120 |
| Analysis | 需求分析 (包括学习新技术) | 480 | 480 |
| Design Spec | 生成设计文档 | 120 | 60 |
| Design Review | 设计复审 | 120 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 120 | 120 |
| Coding | 具体编码 | 480 | 600 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 360 | 360 |
| Reporting | 报告 | 120 | 100 |
| Test Report | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 2210 | 2280 |
二、解题思路
语言选择
Python 便于快速实现,也常用于数据分析,还有参考程序它不香吗?
优化目标
参考代码经过一顿 Ctrl C + Ctrl V 操作之后,发现该代码已经可以正常跑通样例数据的!
并且已经实现了基本的三个查询功能:“用户——事件”、“项目——实践”、“用户——项目——事件” 并统计出某个事件对应的次数。
- 主目标:保证正确率的前提下,优化读取、处理、查询速度
- 附加目标
- 代码重构,将原始代码变得简单易读( P.S. 原来的代码我觉得来自远古时代)
- 需要应对各种特殊状况,例如有上 G 内存的数据轰炸和反反复复的冗余询问
代码分析
将总体任务划分为三大块:
- json 数据读取与拆分
- (1)输入数据采用了 json 数据结构,读取以后将转化为 python 语言中的键值对 ( key -> value )字典。每一行对应一个 github 数据,虽然内容庞大,但实际只需要处理的是 "actor" 中的 " login "、"repo" 中的 "name"、事件类型"type",以及"type"中仅关注其中四种数据类型。
- PushEvent
- IssueCommentEvent
- IssuesEvent
- PullRequestEvent
- (2)源代码将这些数据读取出来以后,逐行拆分,再将一个字典中嵌套的字典再进行拆分,直到重新组成一个无嵌套的字典。
- (1)输入数据采用了 json 数据结构,读取以后将转化为 python 语言中的键值对 ( key -> value )字典。每一行对应一个 github 数据,虽然内容庞大,但实际只需要处理的是 "actor" 中的 " login "、"repo" 中的 "name"、事件类型"type",以及"type"中仅关注其中四种数据类型。
- 数据重新统计
- 直接重新读取处理好的数据,根据三种查询,分门别类统计好,并持久化存储。
- 命令行运行
- 调用 Commander,并输入查询命令,返回查询结果或者错误提示。
> python GHAnalysis.py -i (file_path)
> python GHAnalysis.py -u (user) -e (event)
> python GHAnalysis.py -r (repo) -e (event)
> python GHAnalysis.py -u (user) -r (repo) -e (event)
注:此处 windows 输入 python 或者 python3,需要根据安装路径下 python.exe 文件名来决定。
优化方向
- 速度
- 多线程 / 多进程 / 协程
- 加速 IO 存取
- 减少原始代码里的套娃行为
- 去除冗余数据或者无效数据
- 其他 - 正确率( 100%,保证代码没有 BUG 即可)
学习方向
- Python
- 了解库 argparse、 multiprocessing、 threading 等等函数库,直接查看 python 官方的文档,以及参考别人博客园和 CSDN 的资料
- 学习使用 git、github 使用
- 学习单元测试相关的知识,参考链接
三、实现过程
总体构造框架
按照上述分析和题目要求,所需要的总体框架已经在参考代码中给出:
- 一个读取命令行参数决定后续任务的函数 argparse_init()
- 一个初始化读取函数 init()
- 一个字典解析重构函数 process()
- 一个分析统计函数 calculate()
- 三个查询函数 get_xxx()
原始流程
1、命令行参数的读取依赖于argparse库,输入对应参数并匹配,格式为“ python GHAnalysis.py [—x|--xxxx] [args]”,原参考代码已实现
2、初始化读取函数需要传入 json 文件所在文件夹的路径(暂定为当前目录下的相对路径)。传入路径参数以后,搜索该路径下所有 .json 文件并调用 json 库打开,生成对应的带有嵌套的原始数据字典。
3、将逐一搜索原始的字典中的 value ,发现是字典嵌套,解除嵌套并赋予与原 key 相关联的新key,并继续深入搜索,直到解除所有嵌套,返回无嵌套的字典
4、收集全部解析重构过的字典,直接提取我们需要的键值对进行数值统计,将结果持久化保存。
5、对于下一次查询,若已经初始化则跳过初始化到统计的全过程,直接提取已经存储好的键值对结果,直接返回所需查询功能下的查询结果。
优化
- 对源代码的修改想法
- 为了追求效率,重新统计各步骤的耗费时间,我们发现解除嵌套的步骤消耗了将近全过程一半的运行时间,并且由于字典嵌套可以通过多重键值访问来替代,可以直接无视重构步骤,也就是直接删了 process() 这个处理函数和过程
- 由于一个文件夹内可能有多个 json 文件需要读入,可以通过创建线程对应每一个 json 文件的读写,节约时间
- 源代码最终创建了三个统计完成的 json 文件:1.json 、2.json 、3.json,可以尝试合并为一个统一可查询的文件,也可引入其他类型的数据文件或者数据库,降低代码冗余程度,避免读取高达 10G 数据时电脑蓝屏(dbq我电脑很烂...)
- 每次查询必定需要重新读取一遍统计完毕的 json 文件,当数据量巨大时耗时也相应提升。假如查询的数据符合局部性原理,建立 Cache.json 文件,对近期查询的数据及其关联数据保留一定时长,至于是何种内存映射或者存储结构还需要试验。(要是随机访问就有点无奈了)
尝试
- 多线程(已尝试)
使用之后发现作用不大,Python中的多线程只能利用单核,这是假的多线程。 - 多进程(已尝试)
比较有效果,能够有效提升一定的性能,但是由于受限于 CPU 数量,以及不够稳定,综合起来看效果一般 - 更换存储结构
- 建立 Cache 临时文件
- 更换索引过程(从别人的博客看到的)
流程图

四、代码说明
代码链接:点击进入
注:说明在注释当中
多进程
for root, dic, files in os.walk(dict_address):
# print(cpu_count())
pool = Pool(processes=max(cpu_count(), 6)) # 调用进程池
for filename in files:
if filename[-5:] == '.json':
pool.apply_async(self.read, args=(filename, dict_address)) # 分配进程,让每个进程读取一个文件,同时处理
pool.close()
pool.join()
查询
# 查询用户——事件
def get_events_users(self, username: str, event: str) -> int:
if not self.__U2E.get(username, 0):
return 0
else:
self.cache()
return self.__U2E[username].get(event, 0)
# 查询项目——事件
def get_events_repos(self, repo_name: str, event: str) -> int:
if not self.__R2E.get(repo_name, 0):
return 0
else:
self.cache()
return self.__R2E[repo_name].get(event, 0)
# 查询用户——项目——事件
def get_events_users_and_repos(self, username: str, repo_name: str, event: str) -> int:
if not self.__U2E.get(username, 0) or not self.__UR2E[username].get(repo_name, 0):
return 0
else:
self.cache()
return self.__UR2E[username][repo_name].get(event, 0)
预处理
# 存储预处理过的json文件,去除除了四个事件之外的事件类型,并重新整理数据的键值对
def store_in_mem(self, json_list, filename):
batch_message = [] # 临时存储该json的重要信息
for item in json_list:
# 类型不符就跳过
if item['type'] not in ["PushEvent", "IssueCommentEvent", "IssuesEvent", "PullRequestEvent"]:
continue
# 直接查找最重要的三个属性并重构
batch_message.append({'actor__login': item['actor']['login'], 'type': item['type'], 'repo__name': item['repo']['name']})
with open('json_temp\' + filename, 'w', encoding='utf-8') as F: # 持久化存储
json.dump(batch_message, F)
五、单元测试
测试代码
该处参考了别人的博客和 CSDN ,专门测试了初始化函数和三个查询函数,代码如下:
import unittest
import GHAnalysis
class TestClass(unittest.TestCase):
def setUp(self):
print("========================TEST BEGIN==========================
")
def tearDown(self):
print("========================TEST END==========================
")
def test_init(self):
self.data = GHAnalysis.Data("json", 1)
self.assertEqual(self.data.init("json"), "Init Finish")
def test_quest_U_E(self):
self.data = GHAnalysis.Data("json", 1)
self.assertEqual(self.data.get_events_users("waleko", "PushEvent"), 8)
def test_quest_R_E(self):
self.data = GHAnalysis.Data("json", 1)
self.assertEqual(self.data.get_events_repos("katzer/cordova-plugin-background-mode", "PushEvent"), 0)
def test_quest_U_R_E(self):
self.data = GHAnalysis.Data("json", 1)
self.assertEqual(self.data.get_events_users_repos("cdupuis", "atomist/automation-client", "PushEvent"), 4)
if __name__ == '__main__':
unittest.main()
测试结果
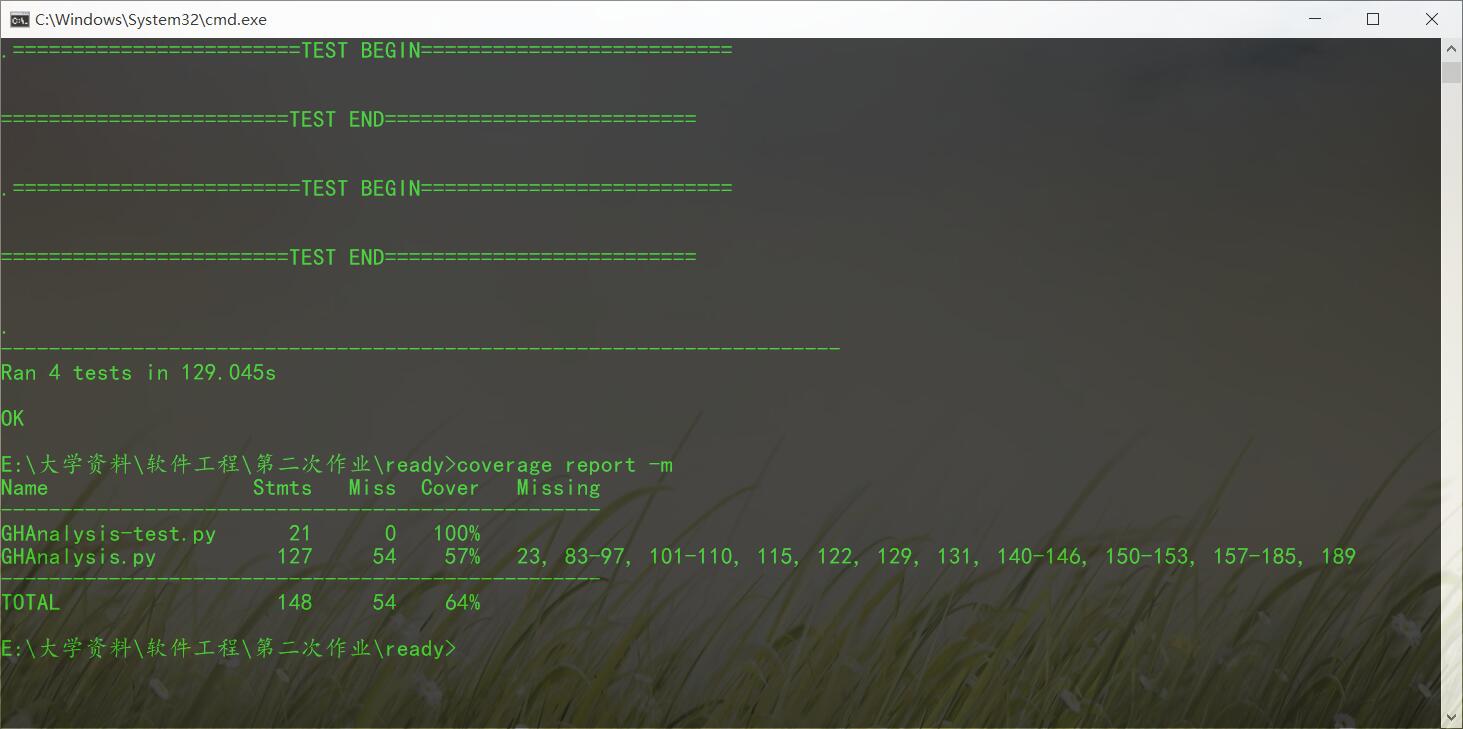
性能
- 测试样例: 420 MB 的数据
- 测试环境:别人家的电脑,CPU 和内存都不错的那种(自己电脑太烂了,多进程效果不显著)
- 测试结果:仅测试初始化过程,查询过程耗时较少可以暂时忽略,如图,大致在 3.6-4.0 s 之间

六、代码规范
七、总结
- 又一不小心接触了好多 python 库,感觉大脑又充实了一吨
- 也看了一下别人的优化方法,也和别人讨论过,再次感慨自己对语言工具的使用依然处于浅层,能学的还能更加深入一些。
- 下次一定要记得博客和代码同时开工,先写好博客园定下大致的方向对后续的工作开展非常有效
- github 好久没用了,平时得多用用
八、附录
Git指令
$ git clone (url)
$ git add [filename1] [filename2] [filename3] ...
$ git commit -m "annotation"
$ git remote add origin git@github.com:username/repo-name
$ git push -u origin master
...