今天发现大家对NSQ等组件的集群原理还不了解,所以这遍文章对一些常见组件的集群原理做一个汇总整理。我会不定期更新,增加一些新的组件或修改错误。
1 NSQ
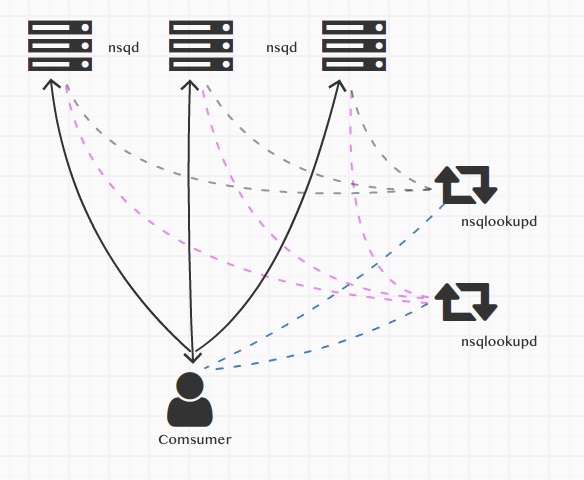
NSQ集群比较简单,主要包含4个部分,一是生产者(图上没画)、二是nsq实例(nsqd)、三是服务发现nsqlookupd、四是消费者(Comsumer)。
这4个部分的工作方式如下:
- 生产者
- 生产者需要指定将消息写入哪个实例nsqd
- 当一个nsqd实例宕机时,生产者可以选择将消息写到其他的实例
- 生产者也可以将同一条消息写入两个nsqd(HA)
- nsqd
- 消息不会在nsqd之间传递,生产者把消息写到哪个nsqd就只能在该nsqd消费
- 不同的nsqd可以接收同一个生产者的相同的消息,参考生产者的说明
- nsqd会将自己的服务信息广播给集群内的nsqlookupd
- 服务发现nsqlookupd
- nsqlookupd与集群内的所有nsqd建立连接,检测实例的状态,并接收实例广播过来的服务注册
- nsqlookupd接收消费者客户端的服务发现请求,将对应的实例返回给消费者(这里可以是多个实例)
- 一个集群可以有多个nsqlookupd
- 消费者comsumer
- 消费者可以与nsqd直连,但为了防止单点故障,不应该有这种固定的关系
- 官方推荐走服务发现nsqlookupd,参考生产者的说明,当一个nsqd宕机时,生产者可以将消息写入其他的nsqd,或者为了HA,生产者可以双写
针对上述特性说明,我们可以得出以下结论或支撑系统高可用的方案:
- 当一个nsqd宕机时,这台机上尚未消费且尚未落盘的消息会丢失;集群本身不提供副本和分片
- 鉴于上一条,对于幂等且不可丢失的消息,生产者可以选择双写,一条消息同时写两个实例
- 当正在写的nsqd宕机时,生产者可以选择写入其他的nsqd。前提是消费者通过nsqlookupd完成服务发现,及时感知集群的变化;或者消费者可以同时连上集群内所有的Nsqd实例
- 生产者可以做一定的负载均衡,将消息分散生产到不同的nsqd中
2 Elasticsearch
2.1 拓扑结构
ES集群涉及数据迁移、负载均衡和HA等,所以会比NSQ集群更复杂些,下面我们通过一张图来简单介绍下:
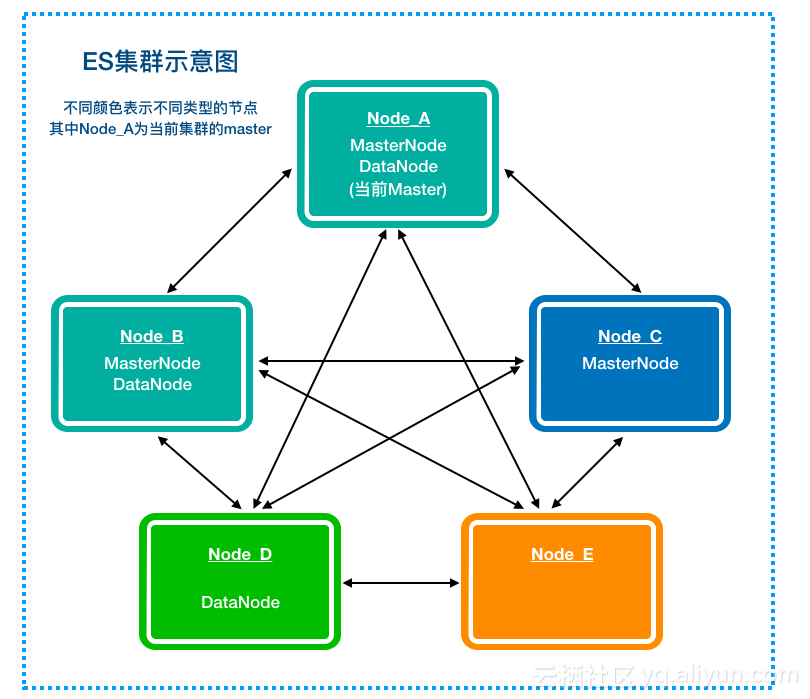
ES的节点可以通过两组配置项来决定每个节点类型,即"node.master: true/false"和"node.data: true/false",具体类型如下表:
| node.master | node.data | 是否参与选主 | 是否保存数据 | 是否参与计算 | 对应上图节点 |
|---|---|---|---|---|---|
| true | true | 是 | 是 | 是 | Node A/B |
| true | false | 是 | 否 | 是 | Node C |
| false | true | 否 | 是 | 是 | Node D |
| false | false | 否 | 否 | 是 | Node E |
特殊的,像Node E这种又不参与选主,又不保存数据的节点,也是有用的,它可以用来处理用户请求。所有的节点都可以接收并处理用户请求。具体逻辑见后续章节。
ES集群还支持其他的节点类型,在此不展开讨论。
集群内所有节点理论上两两相连(网络异常时允许部分节点之间通讯中断,保证最终整个集群是拓扑连续的即可)。每个节点都会保存与其相连的其他节点的信息,用于选主和路由。节点之间通过Gossip谣言传播算法实现数据交换和最终一致性,具体的原理细节这里就不讨论了。
2.2 数据分布
ES支持数据分片和分片副本:
- 主分片与副本分片一般分布在不同的节点(HA高可用)
- 不同的主分片可以在同一个节点
- 数据更新只能发生在主分片
- 查询请求可以在主副分片
- 当主分片丢失时,会自动选择一个最新的副本分片作为主
分片分布在哪个节点上是不固定的,随着集群的数据变化和节点的增加删除,分片会在不同节点之间移动。这个由master主节点来负责协调。具体参见“master主节点”章节。
2.3 数据访问
集群所有节点均可接收用户请求。
2.1章节提到每个节点会保存其他节点的信息,所以当一个用户请求到来时,当前节点负责解析用户请求,并从本地节点列表中选择有相关分片的节点(数据分片往往被打散到不同的节点)将请求转发过去。
对于写请求:
- Node A收到用户请求,解析后确定需要写Node B所保存的主分片,则Node A将请求转发给Node B
- Node B完成主分片的写入(注意,只有主分片能写,副本分片从主分片同步数据)
- Node B将数据同步给集群内其他副本分片,待所有分片均返回后,响应Node A写入成功
- Node A响应用户请求
对于读请求:
- Node A收到用户请求,解析后确认涉及哪些分片,从本地节点列表中找出有相关分片的节点将请求转发过去
- 各分片完成查询,将数据返回给Node A
- Node A将数据运算汇总后,响应用户请求
2.4 master主节点
主节点是由集群自动选举出来的。
集群内有且只能有一个master主节点,它负责集群的协调工作,比如新节点加入、分片的转移等。
根据2.1章节的描述,只有node.master配置为true的节点才有可能成为主节点。
集群选举
- 选举由node.master配置为true的节点发起,当某个候选节点发现当前集群缺少master的时候,会主动发起选举(节点之间会相互通过ping交换信息,包括主节点信息,如果超过半数的节点都连不上主节点时,就认为没有主节点)
- 选举的方式是集群所有节点投票,投票规则是每个节点都选择本地列表中version最高的(如果存在并列最高,则选id最小的那个节点),节点通过join指令投票。
- 被选节点通过收集join的次数,超过集群节点总数的一半+1的节点选自己为主节点时,选举即成功。
- 否则超时开启下一轮选举,直到集群选出master。
关于脑裂
当集群存在两个或以上的master时,我们称之为脑裂。这种情况会导致集群的一致性受到威胁。
略有遗憾的是ES存在小概率的脑裂问题。比如当Node A发起选举,Node X投了一票;但选举迟迟未成功,接着又有个节点发起了一轮投票,刚好这时Node X发现Node B的版本更高,又投了一票给Node B。于是Node X投出了两票,条件契合的情况下,Node A/B可能同时认为自己被选上。这种情况可以通过引入选举周期来解决,同一周期一个节点只投一票,最终选择周期最新的节点为主。
特别注意:只有两个节点的集群,一旦通讯异常,master就选不出来了,因为拿不到总节点数/2 + 1的票数
类似的,当集群有超过半数的节点宕机,集群将变的不可用。
2.5 节点发现和退出
当有节点需要加入集群时,通过给它配置discovery.zen.ping.unicast.hosts: [xx.xx.xx.xx, yy.yy.yy.yy]参数来完成自动发现,加入集群。原理是节点会向上述hosts列表发送请求,寻找master,然后join master。该hosts建议配置成所有的主候选节点。
节点需要退出时,先标记待退出状态,待master将分片全部移走时,才能退出集群。