1、选项,函数助手对话框,打开函数助手
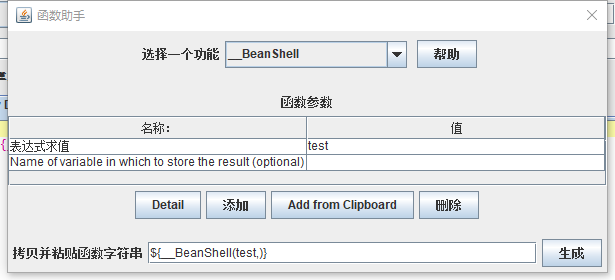
2、使用方法
输入参数,点击生成,可以直接使用(Name of variable in which to store the result (optional)为选填项,新建变量,可将值赋给该变量)


3、函数说明
__BeanShell:beanshell脚本 ,例:${__BeanShell(1=2),},值为false
__char:将十进制或十六进制转为Unicode字符,例:${__char(A)}
__counter:计数器,只有两个参数,TRUE和FALSE,TRUE:只统计当前线程,FALSE:全局统计
__CSVRead:读取文件内容,例如:${__CSVRead(/home/data.txt,0)},第一个参数为文件目录,第二个为列数,常用于参数化(CSV Data Set Config参数化更方便)
__escapeHtml:将字符转化为html格式,例如:${__escapeHtml("bread" & "butter")}="bread" & "butter"
__escapeOroRegexpChars:将正则表达式中的特殊字符进行转义,例:${__escapeOroRegexpChars([^"].+?)}=[^"].+?
__eval:执行含有参数的字符串,一般配合参数一起使用
例:定义变量name=测试企业,table=company,SQL=select * from ${table} where entname='${name}',${__eval(${SQL})}=select * from company where entname='测试企业'
__evalVar:执行包含参数的表达式,功能类似eval,例: ${__eval(SQL)}=select * from company where entname='测试企业'
__FileToString:读入文件,例:${__FileToString(E:Jmeter um ext.txt,utf-8,)},第一个参数为文件目录,第二个参数为编码格式
__intSum:int型数据求和,例:${__intSum(-1,2,3)},如需计算更多数据,可在后面添加,中间逗号分隔
__javaScript:执行js脚本,例:${__javaScript(new Date())}
__jexl:执行jexl表达式,例:${__jexl(5*7+30-21,)}=44
__log:记录日志,例:${__log("test",out,,)},第一个参数为日志内容,第二个参数为日志级别info、err、out
__logn:记录日志并返回空字符串,用法同__log
__longSum:long数据求和,例:${__longSum(123,456,111)}
__machineIP:返回主机IP,例:${__machineIP()}
__machineName:返回主机名,例:${__machineName()}
__P:返回命令行中定义的属性值,例:jmeter -Jgroup1.threads=7 -Jhostname1=www.realhost.edu ,${__P(group1.threads)},属性如未定义,默认返回1
__property:返回jmeter属性值,例:${__property(usr.dir,,1)},第三个参数为默认值
__Random:生成随机数,例:${__Random(1,100,)},两个参数分别为随机数的范围
__RandomString:生成随机字符串,例:${__RandomString(10,!@#$%^&*987765agfdasfdghsa,)},第一个参数为字符串长度,第二个参数为用来生成字符串的字符
__regexFunction:使用正则表达式提取上一个响应内容,类似正则表达式提取器,例:${__regexFunction(session=(20180806d{8}),1,1,,,,)}
|
函数参数 |
描述 |
是否必需 |
|
第1个参数 |
第1个参数是用于解析服务器响应数据的正则表达式,它会找到所有匹配项;如果希望将表达式中的 某部分应用在模板字符串中,一定记得为其加上圆括号。例如,<a href="(.*)">,这样就会将链 接的值存放到第一个匹配组合中(这里只有一个匹配组合)。又如,<input type="hidden" name="(.*)"value="(.*)">,在这个例子中,链接的name作为第一个匹配组合,链接的value会 作为第二个匹配组合,这些组合可以用在测试人员的模板字符串中。 |
是 |
|
第2个参数 |
这是一个模板字符串,函数会动态填写字符串的部分内容。要在字符串中引用正则表达式捕获的匹配组 合,请使用语法:[groupnumber][groupnumber]。例如11或者 22,模板可以是任何字符串。 |
是 |
|
第3个参数 |
第3个参数告诉JMeter使用第几次匹配;测试人员的正则表达式可能会找到多个匹配项,对此, 有4种选择: n 整数,直接告诉JMeter使用第几个匹配项; n “1”对应第一个匹配,“2”对应第二个匹配,以此类推; n RAND,告诉JMeter随机选择一个匹配项; n ALL,告诉JMeter使用所有匹配项,为每个匹配项创建一个模板字符串,并将它们连接在一起 n 浮点值0到1之间,根据公式(找到的总匹配数目*指定浮点值)计算使用第几个匹配项,计算值 向最近的整数取整 |
否,默认值为1 |
|
第4个参数 |
如果在上一个参数中选择了“ALL”,那么这第4个参数会被插入到重复的模板值之间 |
否 |
|
第5个参数 |
如果没有找到匹配项返回的默认值 |
否 |
|
第6个参数 |
重用函数解析值的引用名,参见上面内容 |
否 |
|
第7个参数 |
输入变量名称。如果指定了这一参数,那么该变量的值就会作为函数的输入,而不再使用前面的采样结 果作为搜索对象 |
否 |
__samplerName:获取采样器名称,例:${__samplerName()}
__setProperty:设置Jmeter属性的值,例:${__setProperty(user.id,1,true)},第一个参数必须为jmeter属性,第二个参数为属性值,第三个参数false返回空字符串,true返回属性的原始值
__split:根据分隔符将字符串分隔为数组,例:"${__split(a|b|c,var,|)}",第一个参数为需要分隔的字符串,第二个参数为变量名,第三个参数为分隔符,var_1=a,var_2=b,var_3=c
__StringFromFile:从.dat文件中逐行读取数据,例:"${__StringFromFile(E:Jmeter um est.dat,,,)}",第一个参数为文件目录,
如果需要读取多个文件user1,user2,user3,例:"${__StringFromFile(E:Jmeter umuser#.dat,data,1,3)}",第二个参数为存储的变量名,第三个参数为文件起始序列号(例中为user1),第四个参数为终止序列号
__TestPlanName:返回当前测试计划名称(我的jmeter 3.0,返回的为空),例:${__TestPlanName}
__threadNum:返回当前线程编号,例:${__threadNum}
__time:返回当前时间,例:"${__time(yyyy-MM-dd HH:mm:ss,)}",第一个参数为时间格式,第二个为变量名,不输入参数为时间戳
__unescape:反转义java中的转义字符,例:"${__unescape(1 2)}"=“1 2”
__unescapeHtml:反转义html中的转义字符,例:"${__unescapeHtml(<>)}"="<>"
__urldecode:解码url转义字符,例:${__urldecode(%22hello%22)}=“hello”
${__urlencode:将字符转为url转义字符,例:${__urlencode(测试企业)}=%E6%B5%8B%E8%AF%95%E4%BC%81%E4%B8%9A
__UUID:生产随机uuid数,例:${__UUID}
__V:使用变量名表达式调用其它变量,例:A1和N=1都为变量,${A{N}}不能用,${__V(A${N})}=A1
__XPath:读取XML文件,并返回与XPath表达式相符的值,例:${__XPath(E:/test.xml,//project/@name)}=test
新建xml,test.xml:
<project name="test"></project>
__StringFromFile:从文本中读取字符串,例:${__StringFromFile(E: est.xml,,,)}