以fork()函数为例,分析内核态进程切换的实现
首先在用户态的某个进程中执行了fork()函数

fork引发中断,切入内核,内核栈绑定用户栈
首先分析五段论中的第一段:
中断入口:先把相关寄存器压栈保存,然后call真正的fork系统调用

当前进程被阻塞或时间片到后,使用调度算法进行线程切换

reschedule的展开:其实是把ret_from_sys_call的地址压栈(作用之后就会看到),然后再去进行调度算法

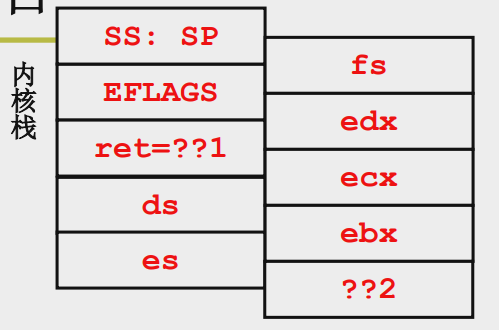
此时的内核栈:??2后是内核当前的esp指针
第五段和调度算法:执行完调度算法后,即cpu已经调度到新的进程,此时从内核态返回用户态,这时就要用到ret_from_sys_cal
注意eax里存的是返回值,返回的位置是新的进程


中间三段论:
switch_to:把cpu从一个内核栈调度到另一个内核栈,即找到目标进程的tcb,这样就完成了一次切换。
但是linux0.11用了tss方式,即用tcb保留当前进程的运行情况(保留下所有相关寄存器的值,可以理解为运行现场的照相),然后把新的进程的tcb保存的运行现场扣给所有寄存器
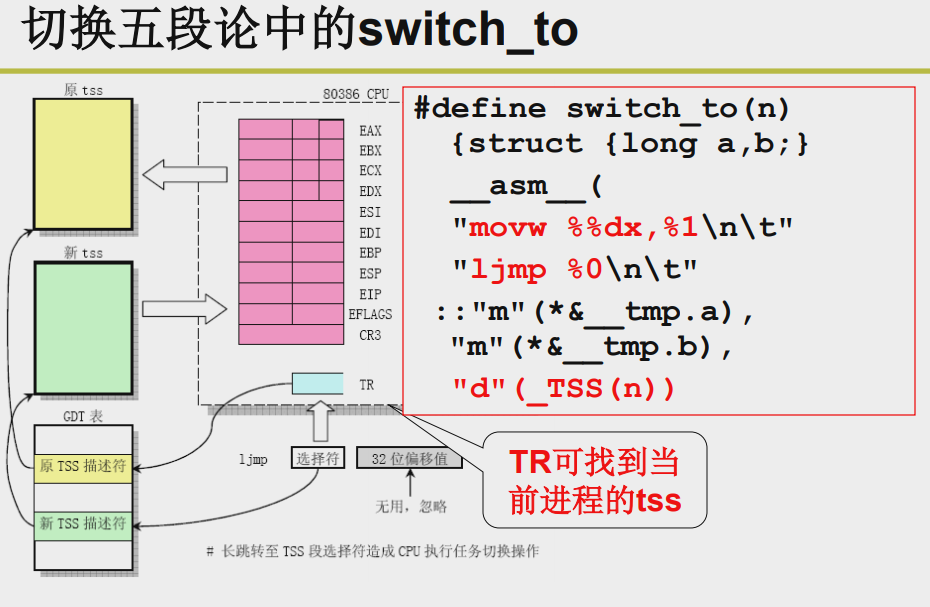
内嵌汇编注释:
 :新TSS描述符赋值给TR(32位)
:新TSS描述符赋值给TR(32位)
 :把TR赋值给tmp.b
:把TR赋值给tmp.b
 :跳转到tmp.a执行,ljmp是长跳转指令,需要64位的目标操作数
:跳转到tmp.a执行,ljmp是长跳转指令,需要64位的目标操作数
因为fork的工作时建立一个新的进程
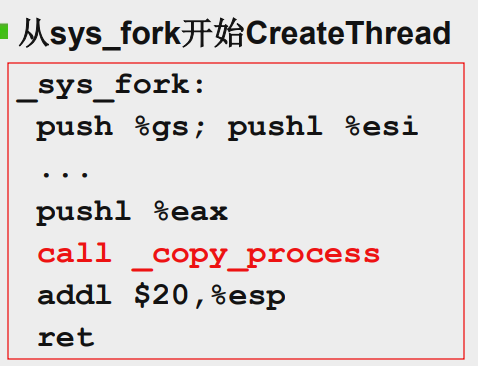
copy_process函数里需要把父进程的所有寄存器信息赋值给子进程(子进程目前和父进程是一样的)

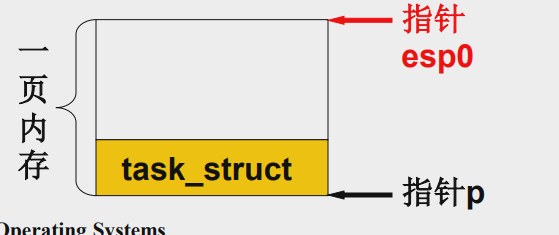
创建子进程的内核栈和绑定的用户栈
给p分配一页内核空间,esp0指向栈顶,由于子进程和父进程共用用户栈,所以绑定的用户栈和父进程也一样

copy时的一些细节:
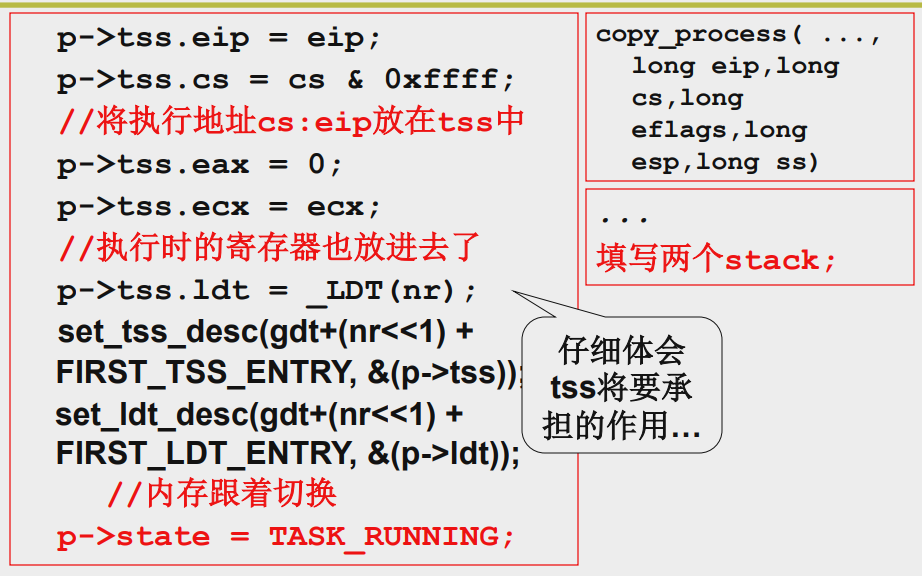
因为是fork所以新的tss先复制旧的tss
然后进程切换,内存也跟着切换
eax要变成0(之后会说)
因为新的进程需要被调度,所以状态设置为0
同时也必须填写两个栈
fork的一些特别之处
1.返回值有两个:父进程非0,子进程为0,(res和eax是绑定的,子进程的eax在tss中被置为0了,而父进程的eax在第一段里被压栈保存了,返回值是子进程pid)
2.子进程在被创建后,返回到用户态运行时会阻塞父进程,那么父进程什么时候返回?是子进程阻塞或退出后cpu调度到父进程时,通过iret返回到父进程对应的用户态的
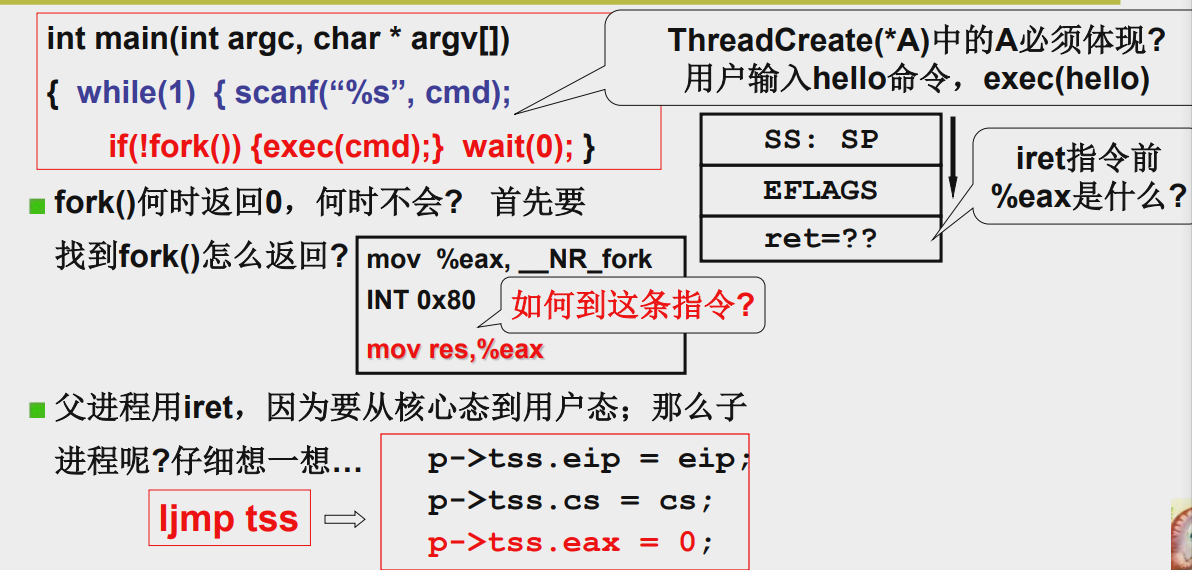
那么调用fork的结果就是:父进程等待,子进程运行
exec系统调用可以调用cmd命令:exec返回前,子进程执行和父进程一样的代码,返回后就,子进程就开始调用cmd,和父进程不一样了

那么如何才能让子进程找到a并开始运行?
调用do_execve后,a在编译链接时会产生一个链接地址(入口地址entry),通常a的第一句就是a的入口地址,从这个入口地址进入就可以按指令运行a了
所以exec就是找到a的入口地址,将其赋值给ret作为用户栈的返回地址返回,那么返回后就可以直接从a入口地址开始运行a了
