------------恢复内容开始------------
我这里练习爬虫的网站是顶点小说网,地址如下:
我这里以爬取顶点小说网里面的凡人修仙传为例子:
首先观察界面:
第一章:
第二章:
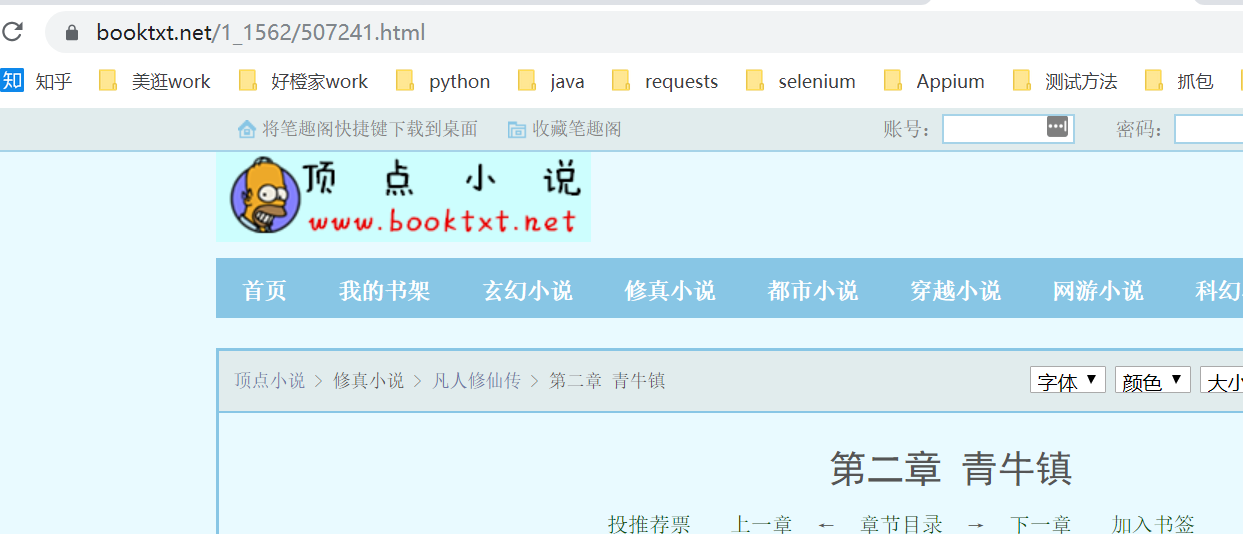
由上面可得出规律,每点一次下一章,url后面的数字就会自动加1。
爬虫主要分为3步:
第一步:构建url列表
def url_list(self): url = "https://www.booktxt.net/1_1562/{}.html" url_list = [] for i in range(self.page): url_list.append(url.format(507240 + i)) return url_list
使用for循环,传入一个参数,没循环一次url后面的数字就会自动加1,把他放到一个新的url_list列表里面。
第二步:发送请求,获取响应结果
def send_request(self, url): res = requests.get(url, headers=self.headers) res.encoding = "GBK" html_str = res.text # 获取html对象 html = etree.HTML(html_str) return html
这里用到了requests库,需要传入一个url参数,返回html对象。
第3步:解析返回的内容,使用xpath提取想要的数据
for循环遍历url_list列表,同时调用send_request函数,传入url函数,遍历网址发送请求,返回html对象,通过xpath提取想要的数据。最后可以把解析出来的数据保存到本地
def run(self): for url in self.url_list(): print(url) html = self.send_request(url) html_tatle = html.xpath("//div[@class='bookname']/h1/text()") print(html_tatle[0]) html_content = html.xpath("//div[@id='content']/text()") for content in html_content: print(content)
第4步:保存结果:
# todo 保存 with open('D:\Spider File\'+'{}.txt'.format(html_tatle), 'a+', encoding='utf-8') as f: time.sleep(random.randint(3, 6)) # 增加爬取时间间隔,防止被封ip f.write(' ' * 3 + str(html_tatle) + ' ') # 章节名 for content in range(len(html_content)): # 内容 f.write(' ' * 4 + html_content[content] + ' ')
运行结果如下:

完整代码如下:
import requests from lxml import etree import time,random import warnings requests.packages.urllib3.disable_warnings() class FictionSpider(): def __init__(self, page): self.page = page self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"} def url_list(self): url = "https://www.booktxt.net/1_1562/{}.html" url_list = [] for i in range(self.page): url_list.append(url.format(507240 + i)) return url_list def send_request(self, url): res = requests.get(url, headers=self.headers,verify=False) res.encoding = "GBK" html_str = res.text # 获取html对象 html = etree.HTML(html_str) return html def run(self): for url in self.url_list(): print(url) html = self.send_request(url) html_tatle = html.xpath("//div[@class='bookname']/h1/text()") # print(html_tatle[0]) html_content = html.xpath("//div[@id='content']/text()") # todo 保存 try: with open(r'D:\Spider File\'+'{}.txt'.format(html_tatle), 'a+', encoding='utf-8') as f: time.sleep(random.randint(1, 3)) # 增加爬取时间间隔,防止被封ip f.write(' ' * 3 + str(html_tatle) + ' ') # 章节名 for content in range(len(html_content)): # 内容 f.write(' ' * 4 + html_content[content] + ' ') except Exception as e: print("错误是:{}".format(e)) if __name__ == '__main__': FictionSpider(608).run()