介绍
你是不是常常想要在各大音乐网站上下载音乐?但是网站却逼迫你下载他们的应用?然而,你下载了应用,它们却逼迫你购买vip......没关系,今天我们就来用爬虫手段“制裁”这些网站!首先,就由最简单的酷狗音乐开始爬!
功能概述
让用户输入要搜索的音乐名,然后把所有的音乐以及每一个音乐对应的信息展示给用户。再询问用户要不要下载任何音乐,如果要,则让用户输入音乐对应的id号来下载(支持批量下载)。
找出思路
首先,在获取多首歌曲的信息和下载地址之前,我们需要知道如何获取一首歌的下载地址。
打开www.kugou.com ,在搜索栏里输入你想要查找的歌曲名。按下回车。切换网页之后,点进一首歌曲的播放页。按下F12,调出开发者工具。选择network,然后点all。可以看到,目前是没有任何东西显示的。因为所有的文件已经在你打开开发者工具的时候加载完了,此时此刻,你只需要F5刷新一下网页。好了,现在
你就能看到类似这样的页面。

![]()
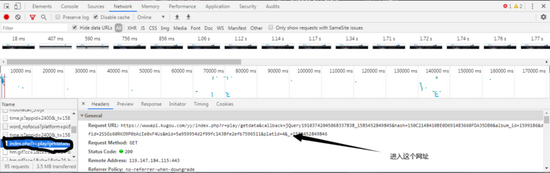
可以看到什么js文件啊,png文件啊,音频文件啊,都没有!因为我们在调出开发者工具之前,网站已经加载完了文件,这个时候,我们只需要按下F5刷新一下网站。好了,所有的文件加载出来了。进入到一个叫做index.php?的文件,然后进入到这个文件的地址。
![]() 、
、
进入这个文件地址之后,这实际上就是音乐的信息(为了方便,我在文章后面就说是信息地址)。我们还可以看到一个叫play_url的东西,这个play_url就是音频的mp3文件地址,可以看到,这些play_url都是把/变成了/。我们不用担心这个,因为网址输入栏会自动帮我们调整成/,但是在用代码实现爬虫的时候,我们就需要把/变成/了。但短时间内,我们先不用管这个。让我们进入到这个网址,咦?这不是我们刚刚播放的音乐吗?
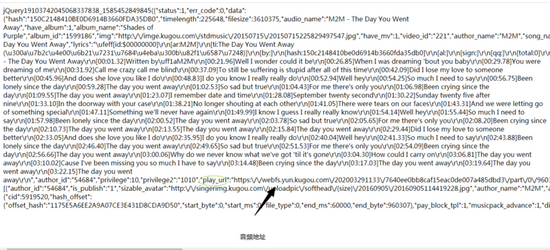
![]()
成功之后,我们就有了更大的信心和思路去爬虫。我们只要把每首歌曲的信息地址找出来,然后用正则表达式把每首歌曲的信息和音乐地址获取出来。再一次用爬虫获取到音乐的二进制编码,保存在本地。
那我们如何获取每首歌的信息地址呢?通过拼接地址!让我们看这两首歌的url有啥不同,你就知道了。
Faded - https://wwwapi.kugou.com/yy/i...
卡路里 - https://wwwapi.kugou.com/yy/i...
可以看到除了hash值以外的东西,就没有啥区别了。也就是说我们只需要通过 https://wwwapi.kugou.com/yy/i...
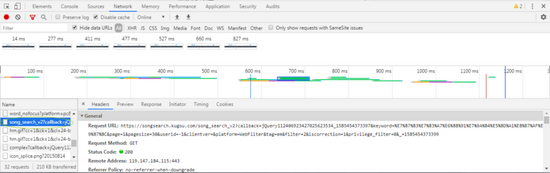
来拼接每首歌的信息地址就行了。那歌曲的hash要去那里找呢?回到酷狗的音乐搜索栏,随便搜一首歌按下回车。可以看到这里有好多首歌。F12-NETWORK-ALL-F5,我们找出一个这样的文件。
![]()
我们进入这个网址,就可以看到刚刚所有歌曲的hash。那问题又来了,我们又要怎样获取到这个hash信息网址呢?这个太简单了,只需要通过 https://songsearch.kugou.com/...
拼接网址就行。
这个搜索的歌曲名,我们代码用input让用户输入歌曲名就行了。那么,你找到思路了吗?
思路:拼接出hash信息网址,正则表达式获取到所有歌曲的hash,再拼接出单首歌曲的url。最后再一次用正则表达式获取歌曲的play_url即可。
开始写代码
首先导入我们的requests和re正则表达式库。re用来找出音乐的信息和下载地址,requests负责获取文本和下载音乐。

![]()
我们还要设置一些变量,这些变量在后面可是会派上大用场的。

![]()
我们不是要拼接出多首歌曲的信息网址吗?那我们就先要让用户输入歌曲名。接着再拼。

![]()
现在,我们就可以用requests请求文本了!由于这个网址是get请求的而且我们请求的是文本,所以,我们也要用方法requests.get().text方法。
![]()
![]()
接着,你可以试着打印一下文本。打印出来的文本和我们拼接的网址的内容毫无区别(我这里就不打印了,等下python卡死就完了)
在这些文本里,我们可以获取到每首歌的hash值。用正则表达式查找就行了。
![]()
![]()
打印一下song_hashes,可以看到,他是个列表。所以我们要进行for遍历。

![]()
上段代码中,我们进行了每个hash的拼接操作,然后我们在从单首歌曲的信息文本里找到了音乐名和作者和下载地址。由于音乐名和作者是进行ascii编码过的,所以我们也要进行一个解码。由于歌曲名和歌手有时候会重复打印,所以我们每一次打印音乐和作者之前,都会把音乐和作者名加入到一个字典。每一次打印都会进行一次是否存在字典的判断。字典的key就由我们的timer变量的变化进行改变key名。另外,我们还把每首歌的下载地址保存到了song_urls字典里。
打印了音乐信息之后,就要询问用户要下载那首歌了。

![]()
按以前的做法,用requests.get().content把音乐转换成二进制文件再进行保存。在get之前,我们还需要把网址的乱七八糟的/变成/。之后,就能保存下来了!
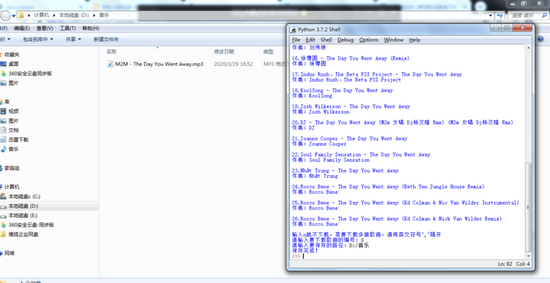
我们就拿一首叫做the day you went away的歌试一下
代码实现效果:
![]()
程序的不足
酷狗每隔一段时间都会弄个滑动验证码,这个时候我们的程序就不能获取到数据。这种情况,用selenium就可以轻松解决。
完整代码:

![]()

![]()
此文转载文,著作权归作者所有,如有侵权联系小编删除!
原文地址:https://www.tuicool.com/articles/Vjyau2Y
需要源代码或者想了解多的(点击这里下载)