C#各版本新特性
C# 2.0
泛型(Generics)
泛型是CLR 2.0中引入的最重要的新特性,使得可以在类、方法中对使用的类型进行参数化。
例如,这里定义了一个泛型类:
class MyCollection<T>
{
T variable1; private void Add(T param)
{ }
}
使用的时候:
MyCollection<string> list2 = new MyCollection<string>();
MyCollection<Object> list3 = new MyCollection<Object>();
泛型的好处
- 编译时就可以保证类型安全
- 不用做类型装换,获得一定的性能提升
泛型方法、泛型委托、泛型接口
除了泛型类之外,还有泛型方法、泛型委托、泛型接口:

//泛型委托 public static delegate T1 MyDelegate<T1, T2>(T2 item);
MyDelegate<Int32, String> MyFunc = new MyDelegate<Int32, String>(SomeMethd); //泛型接口 public class MyClass<T1, T2, T3> : MyInteface<T1, T2, T3> { public T1 Method1(T2 param1, T3 param2) { throw new NotImplementedException(); } } interface MyInteface<T1, T2, T3> { T1 Method1(T2 param1, T3 param2); } //泛型方法 static void Swap<T>(ref T t1, ref T t2) { T temp = t1; t1 = t2; t2 = temp; }
String str1 = "a"; String str2 = "b"; Swap<String>(ref str1, ref str2);
泛型约束(constraints)
可以给泛型的类型参数上加约束,可以要求这些类型参数满足一定的条件
|
约束 |
说明 |
| where T: struct | 类型参数需是值类型 |
| where T : class | 类型参数需是引用类型 |
| where T : new() | 类型参数要有一个public的无参构造函数 |
| where T : <base class name> | 类型参数要派生自某个基类 |
| where T : <interface name> | 类型参数要实现了某个接口 |
| where T : U | 这里T和U都是类型参数,T必须是或者派生自U |
这些约束,可以同时一起使用:
class EmployeeList<T> where T : Employee, IEmployee, System.IComparable<T>, new()
{
// ...
}
default 关键字
这个关键可以使用在类型参数上:
default(T);
对于值类型,返回0,引用类型,返回null,对于结构类型,会返回一个成员值全部为0的结构实例。
迭代器(iterator)
可以在不实现IEnumerable就能使用foreach语句,在编译器碰到yield return时,它会自动生成IEnumerable 接口的方法。在实现迭代器的方法或属性中,返回类型必须是IEnumerable, IEnumerator, IEnumerable<T>,或 IEnumerator<T>。迭代器使得遍历一些零碎数据的时候很方便,不用去实现Current, MoveNext 这些方法。
public System.Collections.IEnumerator GetEnumerator() { yield return -1; for (int i = 1; i < max; i++) { yield return i; } }
可空类型(Nullable Type)
可空类型System.Nullable<T>,可空类型仅针对于值类型,不能针对引用类型去创建。System.Nullable<T>简写为T ?。
int? num = null; if (num.HasValue == true) { System.Console.WriteLine("num = " + num.Value); } else { System.Console.WriteLine("num = Null"); }
如果HasValue为false,那么在使用value值的时候会抛出异常。把一个Nullable的变量x赋值给一个非Nullable的变量y可以这么写:
int y = x ?? -1;
匿名方法(Anonymous Method)
在C#2.0之前,给只能用一个已经申明好的方法去创建一个委托。有了匿名方法后,可以在创建委托的时候直接传一个代码块过去。
delegate void Del(int x); Del d = delegate(int k) { /* ... */ }; System.Threading.Thread t1 = new System.Threading.Thread (delegate() { System.Console.Write("Hello, "); } ); 委托语法的简化// C# 1.0的写法 ThreadStart ts1 = new ThreadStart(Method1); // C# 2.0可以这么写 ThreadStart ts2 = Method1;
委托的协变和逆变(covariance and contravariance)
有下面的两个类:
class Parent { } class Child: Parent { }
然后看下面的两个委托:
public delegate Parent DelgParent();
public delegate Child DelgChild();
public static Parent Method1() { return null; }
public static Child Method2() { return null; }
static void Main() { DelgParent del1= Method1; DelgChild del2= Method2; del1 = del2; }
注意上面的,DelgParent 和DelgChild 是完全不同的类型,他们之间本身没有任何的继承关系,所以理论上来说他们是不能相互赋值的。但是因为协变的关系,使得我们可以把DelgChild类型的委托赋值给DelgParent 类型的委托。协变针对委托的返回值,逆变针对参数,原理是一样的。
部分类(partial)
在申明一个类、结构或者接口的时候,用partial关键字,可以让源代码分布在不同的文件中。我觉得这个东西完全是为了照顾Asp.net代码分离而引入的功能,真没什么太大的实际用处。微软说在一些大工程中可以把类分开在不同的文件中让不同的人去实现,方便团队协作,这个我觉得纯属胡扯。
部分类仅是编译器提供的功能,在编译的时候会把partial关键字定义的类和在一起去编译,和CRL没什么关系。
静态类(static class)
静态类就一个只能有静态成员的类,用static关键字对类进行标示,静态类不能被实例化。静态类理论上相当于一个只有静态成员并且构造函数为私有的普通类,静态类相对来说的好处就是,编译器能够保证静态类不会添加任何非静态成员。
global::
这个代表了全局命名空间(最上层的命名空间),也就是任何一个程序的默认命名空间。
class TestApp { public class System { } const int Console = 7; static void Main() { //用这个访问就会出错,System和Console都被占用了 //Console.WriteLine(number); global::System.Console.WriteLine(number); } }
extern alias
用来消除不同程序集中类名重复的冲突,这样可以引用同一个程序集的不同版本,也就是说在编译的时候,提供了一个将有冲突的程序集进行区分的手段。
在编译的时候,使用命令行参数来指明alias,例如:
/r:aliasName=assembly1.dll
在Visual Studio里面,在被引用的程序集的属性里面可以指定Alias的值,默认是global。
然后在代码里面就可以使用了:
extern alias aliasName; //这行需要在using这些语句的前面 using System; using System.Collections.Generic; using System.Text; using aliasName.XXX;
属性Accessor访问控制
public virtual int TestProperty { protected set { } get { return 0; } }
友元程序集(Friend Assembly)
可以让其它程序集访问自己的internal成员(private的还是不行),使用Attributes来实现,例如:
[assembly:InternalsVisibleTo("cs_friend_assemblies_2")]
注意这个作用范围是整个程序集。
fixed关键字
可以使用fixed关键字来创建固定长度的数组,但是数组只能是bool, byte, char, short, int, long, sbyte, ushort, uint, ulong, float, double中的一种。
这主要是为了更好的处理一些非托管的代码。比如下面的这个结构体:
public struct MyArray { public fixed char pathName[128]; }
如果不用fixed的话,无法预先占住128个char的空间,使用fixed后可以很好的和非托管代码进行交互。
volatile关键字
用来表示相关的字可能被多个线程同时访问,编译器不会对相应的值做针对单线程下的优化,保证相关的值在任何时候访问都是最新的。
#pragma warning
用来取消或者添加编译时的警告信息。每个警告信息都会有个编号,如果warning CS01016之类的,使用的时候取CS后面的那个数字,例如:
#pragma warning disable 414, 3021
这样CS414和CS3021的警告信息就都不会显示了。
C# 3.0
类型推断
申明变量的时候,可以不用直指定类型:
var i = 5;
var s = "Hello";
//两种写法是一样的
int i = 5;
string s = "Hello";
类型推断也支持数组:
var b = new[] { 1, 1.5, 2, 2.5 }; // double[]
var c = new[] { "hello", null, "world” }; // string[]
扩展方法
扩展方法必须被定义在静态类中,并且必须是非泛型、非嵌套的静态类。例如:
public static class JeffClass
{
public static int StrToInt32(this string s)
{
return Int32.Parse(s);
}
public static T[] SomeMethd<T>(this T[] source, int pram1, int pram2)
{
/**/
}
}
上面一个是给string类型的对象添加了一个方法,另一个是给所有类型的数组添加了一个方法,方法有两个整型参数。
扩展方法只在当前的命名空间类有效,如果所在命名空间被其它命名空间import引用了,那么在其它命名空间中也有效。扩展方法的优先级低于其它的常规方法,也就是说如果扩展方法与其它的方法相同,那么扩展方法不会被调用。
Lamda表达式
可以看成是对匿名方法的一个语法上的简化,但是λ表达式同时可以装换为表达式树类型。
对象和集合的初始化
var contacts = new List<Contact> {
new Contact {
Name = "Chris",
PhoneNumbers = { "123455", "6688" }
},
new Contact {
Name = "Jeffrey",
PhoneNumbers = { "112233" }
}
};
匿名类型
var p1 = new { Name = "Lawnmower", Price = 495.00 };
var p2 = new { Name = "Shovel", Price = 26.95 };
p1 = p2;
自动属性
会自动生成一个后台的私有变量
public Class Point
{
public int X { get; set; }
public int Y { get; set; }
}
查询表达式
这个其实就是扩展方法的运用,编译器提供了相关的语法便利,下面两端代码是等价的:
from g in
from c in customers
group c by c.Country
select new { Country = g.Key, CustCount = g.Count() }
customers.
GroupBy(c => c.Country).
Select(g => new { Country = g.Key, CustCount = g.Count() })
表达式树
Func<int,int> f = x => x + 1;
Expression<Func<int,int>> e = x => x + 1;
C# 4.0
协变和逆变
这个在C#2.0中就已经支持委托的协变和逆变了,C#4.0开始支持针对泛型接口的协变和逆变:
IList<string> strings = new List<string>();
IList<object> objects = strings;
协变和逆变仅针对引用类型。
动态绑定
看例子:
class BaseClass
{
public void print()
{
Console.WriteLine();
}
}
Object o = new BaseClass();
dynamic a = o;
//这里可以调用print方法,在运行时a会知道自己是个什么类型。 这里的缺点在于编译的时候无法检查方法的合法性,写错的话就会出运行时错误。
a.print();
可选参数,命名参数
private void CreateNewStudent(string name, int studentid = 0, int year = 1)
这样,最后一个参数不给的话默认值就是1,提供这个特性可以免去写一些重载方法的麻烦。
调用方法的时候,可以指定参数的名字来给值,不用按照方法参数的顺序来制定参数值:
CreateNewStudent(year:2, name:"Hima", studentid: 4); //没有按照方法定义的参数顺序
C# 5.0
1. 异步编程
在.Net 4.5中,通过async和await两个关键字,引入了一种新的基于任务的异步编程模型(TAP)。在这种方式下,可以通过类似同步方式编写异步代码,极大简化了异步编程模型。如下式一个简单的实例:
static async void DownloadStringAsync2(Uri uri)
{
var webClient = new WebClient();
var result = await webClient.DownloadStringTaskAsync(uri);
Console.WriteLine(result);
}
而之前的方式是这样的:
static void DownloadStringAsync(Uri uri)
{
var webClient = new WebClient();
webClient.DownloadStringCompleted += (s, e) =>
{
Console.WriteLine(e.Result);
};
webClient.DownloadStringAsync(uri);
}
也许前面这个例子不足以体现async和await带来的优越性,下面这个例子就明显多了:
public void CopyToAsyncTheHardWay(Stream source, Stream destination)
{
byte[] buffer = new byte[0x1000];
Action<IAsyncResult> readWriteLoop = null;
readWriteLoop = iar =>
{
for (bool isRead = (iar == null); ; isRead = !isRead)
{
switch (isRead)
{
case true:
iar = source.BeginRead(buffer, 0, buffer.Length,
readResult =>
{
if (readResult.CompletedSynchronously) return;
readWriteLoop(readResult);
}, null);
if (!iar.CompletedSynchronously) return;
break;
case false:
int numRead = source.EndRead(iar);
if (numRead == 0)
{
return;
}
iar = destination.BeginWrite(buffer, 0, numRead,
writeResult =>
{
if (writeResult.CompletedSynchronously) return;
destination.EndWrite(writeResult);
readWriteLoop(null);
}, null);
if (!iar.CompletedSynchronously) return;
destination.EndWrite(iar);
break;
}
}
};
readWriteLoop(null);
}
public async Task CopyToAsync(Stream source, Stream destination)
{
byte[] buffer = new byte[0x1000];
int numRead;
while ((numRead = await source.ReadAsync(buffer, 0, buffer.Length)) != 0)
{
await destination.WriteAsync(buffer, 0, numRead);
}
}
关于基于任务的异步编程模型需要介绍的地方还比较多,不是一两句能说完的,有空的话后面再专门写篇文章来详细介绍下。另外也可参看微软的官方网站:Visual Studio Asynchronous Programming,其官方文档Task-Based Asynchronous Pattern Overview介绍的非常详细, VisualStudio中自带的CSharp Language Specification中也有一些说明。
2. 调用方信息
很多时候,我们需要在运行过程中记录一些调测的日志信息,如下所示:
public void DoProcessing()
{
TraceMessage("Something happened.");
}
为了调测方便,除了事件信息外,我们往往还需要知道发生该事件的代码位置以及调用栈信息。在C++中,我们可以通过定义一个宏,然后再宏中通过__FILE__和__LINE__来获取当前代码的位置,但C#并不支持宏,往往只能通过StackTrace来实现这一功能,但StackTrace却有不是很靠谱,常常获取不了我们所要的结果。
针对这个问题,在.Net 4.5中引入了三个Attribute:CallerMemberName、CallerFilePath和CallerLineNumber。在编译器的配合下,分别可以获取到调用函数(准确讲应该是成员)名称,调用文件及调用行号。上面的TraceMessage函数可以实现如下:
public void TraceMessage(string message,
[CallerMemberName] string memberName = "",
[CallerFilePath] string sourceFilePath = "",
[CallerLineNumber] int sourceLineNumber = 0)
{
Trace.WriteLine("message: " + message);
Trace.WriteLine("member name: " + memberName);
Trace.WriteLine("source file path: " + sourceFilePath);
Trace.WriteLine("source line number: " + sourceLineNumber);
}
另外,在构造函数,析构函数、属性等特殊的地方调用CallerMemberName属性所标记的函数时,获取的值有所不同,其取值如下表所示:
|
调用的地方 |
CallerMemberName获取的结果 |
|
方法、属性或事件 |
方法,属性或事件的名称 |
|
构造函数 |
字符串 ".ctor" |
|
静态构造函数 |
字符串 ".cctor" |
|
析构函数 |
该字符串 "Finalize" |
|
用户定义的运算符或转换 |
生成的名称成员,例如, "op_Addition"。 |
|
特性构造函数 |
特性所应用的成员的名称 |
例如,对于在属性中调用CallerMemberName所标记的函数即可获取属性名称,通过这种方式可以简化 INotifyPropertyChanged 接口的实现。
C# 6.0
1、自动属性的增强
1.1、自动属性初始化 (Initializers for auto-properties)
C#4.0下的果断实现不了的。
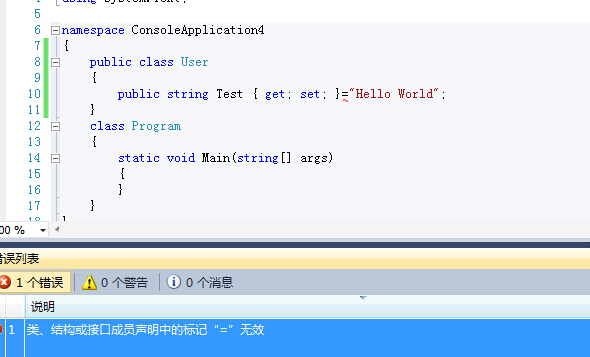
C#6.0中自动属性的初始化方式
只要接触过C#的肯定都会喜欢这种方式。真是简洁方便呀。
1.2、只读属性初始化Getter-only auto-properties
先来看一下我们之前使用的方式吧
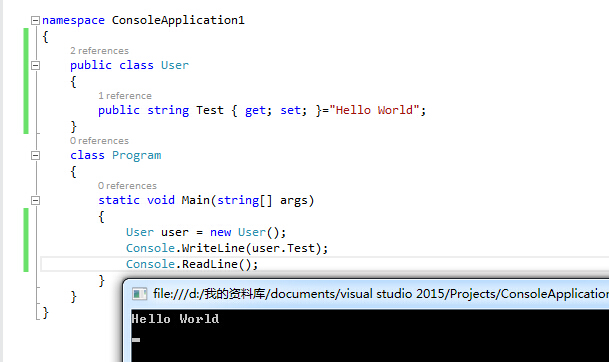
public class Customer { public string Name { get; } public Customer(string firstName,string lastName) { Name = firstName +" "+ lastName; } }
再来看一下C#6.0中
public class Customer
{
public string FirstName { get; }="aehyok";
public string LastName { get; }="Kris";
}
和第一条自动属性初始化使用方式一致。
2、Expression bodied function members
2.1 用Lambda作为函数体Expression bodies on method-like members
public Point Move(int dx, int dy) => new Point(x + dx, y + dy);
再来举一个简单的例子:一个没有返回值的函数
public void Print() => Console.WriteLine(FirstName + " " + LastName);
2.2、Lambda表达式用作属性Expression bodies on property-like function members
public override string ToString()
{
return FirstName + " " + LastName;
}
现在C#6中
public class User
{
public string FirstName { get; set; }
public string LastName { get; set; }
public override string ToString() => string.Format("{0}——{1}", FirstName, LastName);
public string FullName => FirstName + " " + LastName;
}
3、引用静态类Using Static
在Using中可以指定一个静态类,然后可以在随后的代码中直接使用静态的成员
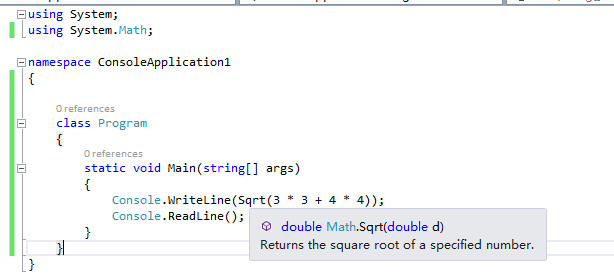
4、空值判断Null-conditional operators
直接来看代码和运行结果
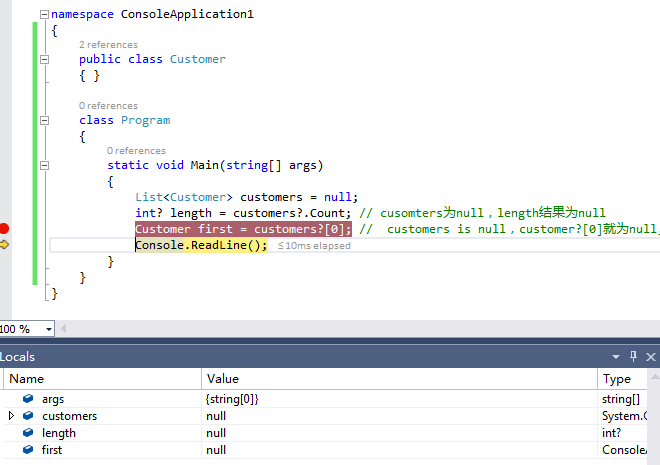
通过结果可以发现返回的都为null,再也不像以前那样繁琐的判断null勒。
5、字符串嵌入值
在字符串中嵌入值
之前一直使用的方式是
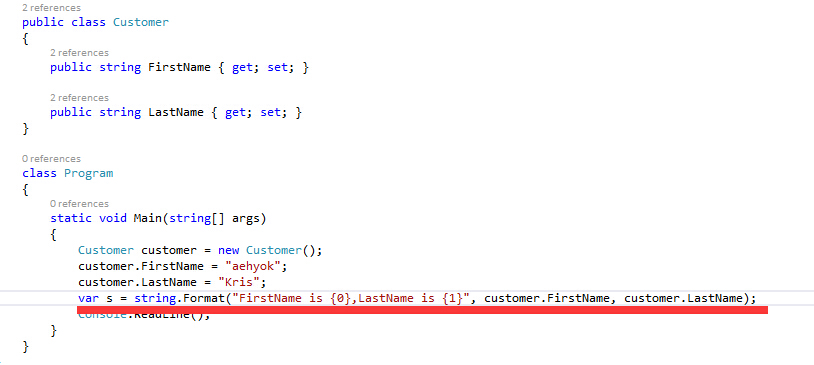
现在我们可以简单的通过如下的方式进行拼接
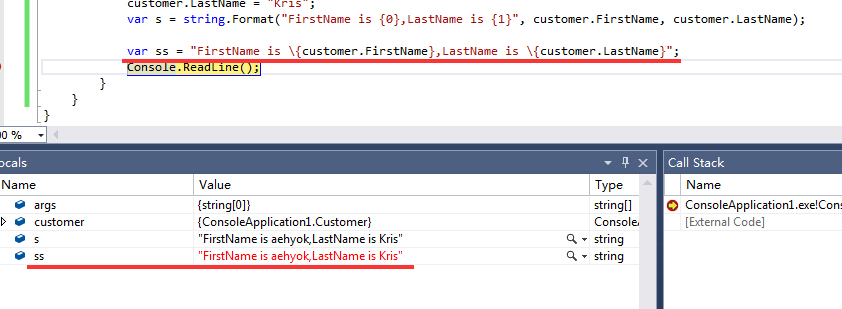
6、nameof表达式nameof expressions
在方法参数检查时,你可能经常看到这样的代码(之前用的少,这次也算学到了)
public static void AddCustomer(Customer customer)
{
if (customer == null)
{
throw new ArgumentNullException("customer");
}
}
里面有那个customer是我们手写的字符串,在给customer改名时,很容易把下面的那个字符串忘掉,C#6.0 nameof帮我们解决了这个问题,看看新写法
public static void AddCustomer(Customer customer)
{
if (customer == null)
{
throw new ArgumentNullException(nameof(customer));
}
}
7、带索引的对象初始化器Index initializers
直接通过索引进行对象的初始化,原来真的可以实现
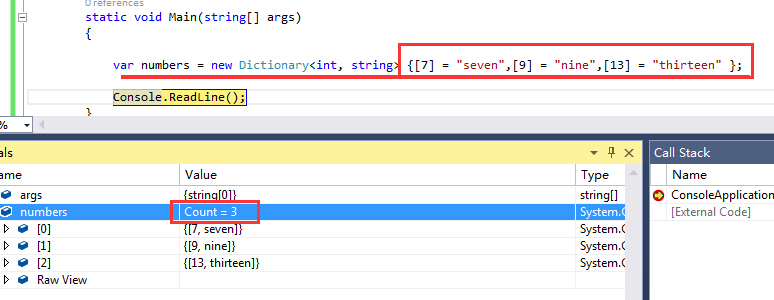
通过这种方式可以发现字典中只有三个元素,所以也就只有这三个索引可以访问额,其他类型的对象和集合也是可以通过这种方式进行初始化的,在此就不进行一一列举了。
8、异常过滤器 (Exception filters)
先来看一个移植过来的方法
try
{
var numbers = new Dictionary<int, string> {[7] = "seven",[9] = "nine",[13] = "thirteen" };
}
catch (ArgumentNullException e)
{
if (e.ParamName == "customer")
{
Console.WriteLine("customer can not be null");
}
}
在微软的文档中还给出了另一种用法,这个异常会在日志记录失败时抛给上一层调用者
private static bool Log(Exception e)
{
///处理一些日志
return false;
}
static void Main(string[] args)
{
try
{
///
}
catch (Exception e){if (!Log(e))
{
}
}
Console.ReadLine();
}
9、catch和finally 中的 await —— Await in catch and finally blocks
在C#5.0中,await关键字是不能出现在catch和finnaly块中的。而在6.0中
try
{
res = await Resource.OpenAsync(…); // You could do this. …
}
catch (ResourceException e)
{
await Resource.LogAsync(res, e); // Now you can do this …
} finally
{
if (res != null)
await res.CloseAsync(); // … and this.
}
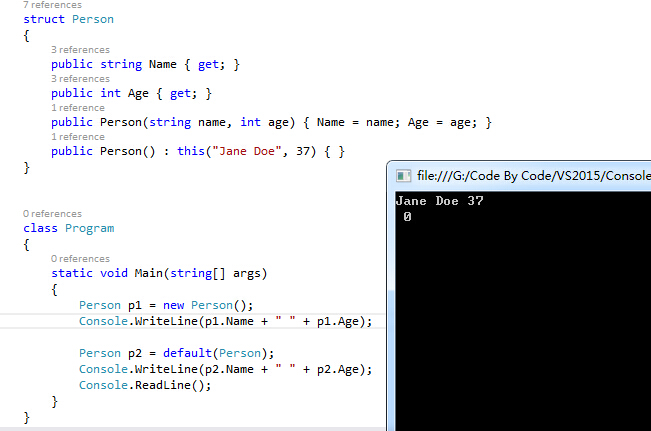
10、无参数的结构体构造函数—— Parameterless constructors in structs
C# 7.0
1. out 变量(out variables)
以前我们使用out变量必须在使用前进行声明,C# 7.0 给我们提供了一种更简洁的语法 “使用时进行内联声明” 。如下所示:
1 var input = ReadLine();
2 if (int.TryParse(input, out var result))
3 {
4 WriteLine("您输入的数字是:{0}",result);
5 }
6 else
7 {
8 WriteLine("无法解析输入...");
9 }
上面代码编译后:
1 int num;
2 string s = Console.ReadLine();
3 if (int.TryParse(s, out num))
4 {
5 Console.WriteLine("您输入的数字是:{0}", num);
6 }
7 else
8 {
9 Console.WriteLine("无法解析输入...");
10 }
原理解析:所谓的 “内联声明” 编译后就是以前的原始写法,只是现在由编译器来完成。
备注:在进行内联声明时,即可直接写明变量的类型也可以写隐式类型,因为out关键字修饰的一定是局部变量。
2. 元组(Tuples)
元组(Tuple)在 .Net 4.0 的时候就有了,但元组也有些缺点,如:
1)Tuple 会影响代码的可读性,因为它的属性名都是:Item1,Item2.. 。
2)Tuple 还不够轻量级,因为它是引用类型(Class)。
备注:上述所指 Tuple 还不够轻量级,是从某种意义上来说的或者是一种假设,即假设分配操作非常的多。
C# 7 中的元组(ValueTuple)解决了上述两个缺点:
1)ValueTuple 支持语义上的字段命名。
2)ValueTuple 是值类型(Struct)。
1. 如何创建一个元组?
1 var tuple = (1, 2); // 使用语法糖创建元组
2 var tuple2 = ValueTuple.Create(1, 2); // 使用静态方法【Create】创建元组
3 var tuple3 = new ValueTuple<int, int>(1, 2); // 使用 new 运算符创建元组
4
5 WriteLine($"first:{tuple.Item1}, second:{tuple.Item2}, 上面三种方式都是等价的。");
原理解析:上面三种方式最终都是使用 new 运算符来创建实例。
2. 如何创建给字段命名的元组?
1 // 左边指定字段名称
2 (int one, int two) tuple = (1, 2);
3 WriteLine($"first:{tuple.one}, second:{tuple.two}");
4
5 // 右边指定字段名称
6 var tuple2 = (one: 1, two: 2);
7 WriteLine($"first:{tuple2.one}, second:{tuple2.two}");
8
9 // 左右两边同时指定字段名称
10 (int one, int two) tuple3 = (first: 1, second: 2); /* 此处会有警告:由于目标类型(xx)已指定了其它名称,因为忽略元组名称xxx */
11 WriteLine($"first:{tuple3.one}, second:{tuple3.two}");
注:左右两边同时指定字段名称,会使用左边的字段名称覆盖右边的字段名称(一一对应)。
原理解析:上述给字段命名的元组在编译后其字段名称还是:Item1, Item2...,即:“命名”只是语义上的命名。
3. 什么是解构?
解构顾名思义就是将整体分解成部分。
4. 解构元组,如下所示:
1 var (one, two) = GetTuple();
2
3 WriteLine($"first:{one}, second:{two}");
1 static (int, int) GetTuple()
2 {
3 return (1, 2);
4 }
原理解析:解构元组就是将元组中的字段值赋值给声明的局部变量(编译后可查看)。
备注:在解构时“=”左边能提取变量的数据类型(如上所示),元组中字段类型相同时即可提取具体类型也可以是隐式类型,但元组中字段类型
不相同时只能提取隐式类型。
5. 解构可以应用于 .Net 的任意类型,但需要编写 Deconstruct 方法成员(实例或扩展)。如下所示:
1 public class Student
2 {
3 public Student(string name, int age)
4 {
5 Name = name;
6 Age = age;
7 }
8
9 public string Name { get; set; }
10
11 public int Age { get; set; }
12
13 public void Deconstruct(out string name, out int age)
14 {
15 name = Name;
16 age = Age;
17 }
18 }
使用方式如下:
1 var (Name, Age) = new Student("Mike", 30);
2
3 WriteLine($"name:{Name}, age:{Age}");
原理解析:编译后就是由其实例调用 Deconstruct 方法,然后给局部变量赋值。
Deconstruct 方法签名:
1 // 实例签名 2 public void Deconstruct(out type variable1, out type variable2...) 3 4 // 扩展签名 5 public static void Deconstruct(this type instance, out type variable1, out type variable2...)
总结:1. 元组的原理是利用了成员类型的嵌套或者是说成员类型的递归。2. 编译器很牛B才能提供如此优美的语法。
使用 ValueTuple 则需要导入: Install - Package System.ValueTuple
3. 模式匹配(Pattern matching)
1. is 表达式(is expressions),如:
1 static int GetSum(IEnumerable<object> values)
2 {
3 var sum = 0;
4 if (values == null) return sum;
5
6 foreach (var item in values)
7 {
8 if (item is short) // C# 7 之前的 is expressions
9 {
10 sum += (short)item;
11 }
12 else if (item is int val) // C# 7 的 is expressions
13 {
14 sum += val;
15 }
16 else if (item is string str && int.TryParse(str, out var result)) // is expressions 和 out variables 结合使用
17 {
18 sum += result;
19 }
20 else if (item is IEnumerable<object> subList)
21 {
22 sum += GetSum(subList);
23 }
24 }
25
26 return sum;
27 }
使用方法:
1 条件控制语句(obj is type variable)
2 {
3 // Processing...
4 }
原理解析:此 is 非彼 is ,这个扩展的 is 其实是 as 和 if 的组合。即它先进行 as 转换再进行 if 判断,判断其结果是否为 null,不等于 null 则执行
语句块逻辑,反之不行。由上可知其实C# 7之前我们也可实现类似的功能,只是写法上比较繁琐。
2. switch语句更新(switch statement updates),如:
1 static int GetSum(IEnumerable<object> values)
2 {
3 var sum = 0;
4 if (values == null) return 0;
5
6 foreach (var item in values)
7 {
8 switch (item)
9 {
10 case 0: // 常量模式匹配
11 break;
12 case short sval: // 类型模式匹配
13 sum += sval;
14 break;
15 case int ival:
16 sum += ival;
17 break;
18 case string str when int.TryParse(str, out var result): // 类型模式匹配 + 条件表达式
19 sum += result;
20 break;
21 case IEnumerable<object> subList when subList.Any():
22 sum += GetSum(subList);
23 break;
24 default:
25 throw new InvalidOperationException("未知的类型");
26 }
27 }
28
29 return sum;
30 }
使用方法:
1 switch (item)
2 {
3 case type variable1:
4 // processing...
5 break;
6 case type variable2 when predicate:
7 // processing...
8 break;
9 default:
10 // processing...
11 break;
12 }
原理解析:此 switch 非彼 switch,编译后你会发现扩展的 switch 就是 as 、if 、goto 语句的组合体。同 is expressions 一样,以前我们也能实
现只是写法比较繁琐并且可读性不强。
总结:模式匹配语法是想让我们在简单的情况下实现类似与多态一样的动态调用,即在运行时确定成员类型和调用具体的实现。
4. 局部引用和引用返回 (Ref locals and returns)
我们知道 C# 的 ref 和 out 关键字是对值传递的一个补充,是为了防止值类型大对象在Copy过程中损失更多的性能。现在在C# 7中 ref 关键字得
到了加强,它不仅可以获取值类型的引用而且还可以获取某个变量(引用类型)的局部引用。如:
1 static ref int GetLocalRef(int[,] arr, Func<int, bool> func)
2 {
3 for (int i = 0; i < arr.GetLength(0); i++)
4 {
5 for (int j = 0; j < arr.GetLength(1); j++)
6 {
7 if (func(arr[i, j]))
8 {
9 return ref arr[i, j];
10 }
11 }
12 }
13
14 throw new InvalidOperationException("Not found");
15 }
Call:
1 int[,] arr = { { 10, 15 }, { 20, 25 } };
2 ref var num = ref GetLocalRef(arr, c => c == 20);
3 num = 600;
4
5 Console.WriteLine(arr[1, 0]);
Print results:

使用方法:
1. 方法的返回值必须是引用返回:
a) 声明方法签名时必须在返回类型前加上 ref 修饰。
b) 在每个 return 关键字后也要加上 ref 修饰,以表明是返回引用。
2. 分配引用(即赋值),必须在声明局部变量前加上 ref 修饰,以及在方法返回引用前加上 ref 修饰。
注:C# 开发的是托管代码,所以一般不希望程序员去操作指针。并由上述可知在使用过程中需要大量的使用 ref 来标明这是引用变量(编译后其
实没那么多),当然这也是为了提高代码的可读性。
总结:虽然 C# 7 中提供了局部引用和引用返回,但为了防止滥用所以也有诸多约束,如:
1. 你不能将一个值分配给 ref 变量,如:
1 ref int num = 10; // error:无法使用值初始化按引用变量
2. 你不能返回一个生存期不超过方法作用域的变量引用,如:
1 public ref int GetLocalRef(int num) => ref num; // error: 无法按引用返回参数,因为它不是 ref 或 out 参数
3. ref 不能修饰 “属性” 和 “索引器”。
1 var list = new List<int>(); 2 ref var n = ref list.Count; // error: 属性或索引器不能作为 out 或 ref 参数传递
原理解析:非常简单就是指针传递,并且个人觉得此语法的使用场景非常有限,都是用来处理大对象的,目的是减少GC提高性能。
5. 局部函数(Local functions)
C# 7 中的一个功能“局部函数”,如下所示:
1 static IEnumerable<char> GetCharList(string str)
2 {
3 if (IsNullOrWhiteSpace(str))
4 throw new ArgumentNullException(nameof(str));
5
6 return GetList();
7
8 IEnumerable<char> GetList()
9 {
10 for (int i = 0; i < str.Length; i++)
11 {
12 yield return str[i];
13 }
14 }
15 }
使用方法:
1 [数据类型,void] 方法名([参数])
2 {
3 // Method body;[] 里面都是可选项
4 }
原理解析:局部函数虽然是在其他函数内部声明,但它编译后就是一个被 internal 修饰的静态函数,它是属于类,至于它为什么能够使用上级函
数中的局部变量和参数呢?那是因为编译器会根据其使用的成员生成一个新类型(Class/Struct)然后将其传入函数中。由上可知则局部函数的声
明跟位置无关,并可无限嵌套。
总结:个人觉得局部函数是对 C# 异常机制在语义上的一次补充(如上例),以及为代码提供清晰的结构而设置的语法。但局部函数也有其缺点,
就是局部函数中的代码无法复用(反射除外)。
6. 更多的表达式体成员(More expression-bodied members)
C# 6 的时候就支持表达式体成员,但当时只支持“函数成员”和“只读属性”,这一特性在C# 7中得到了扩展,它能支持更多的成员:构造函数
、析构函数、带 get,set 访问器的属性、以及索引器。如下所示:
1 public class Student
2 {
3 private string _name;
4
5 // Expression-bodied constructor
6 public Student(string name) => _name = name;
7
8 // Expression-bodied finalizer
9 ~Student() => Console.WriteLine("Finalized!");
10
11 // Expression-bodied get / set accessors.
12 public string Name
13 {
14 get => _name;
15 set => _name = value ?? "Mike";
16 }
17
18 // Expression-bodied indexers
19 public string this[string name] => Convert.ToBase64String(Encoding.UTF8.GetBytes(name));
20 }
备注:索引器其实在C# 6中就得到了支持,但其它三种在C# 6中未得到支持。
7. Throw 表达式(Throw expressions)
异常机制是C#的重要组成部分,但在以前并不是所有语句都可以抛出异常的,如:条件表达式(? :)、null合并运算符(??)、一些Lambda
表达式。而使用 C# 7 您可在任意地方抛出异常。如:
1 public class Student
2 {
3 private string _name = GetName() ?? throw new ArgumentNullException(nameof(GetName));
4
5 private int _age;
6
7 public int Age
8 {
9 get => _age;
10 set => _age = value <= 0 || value >= 130 ? throw new ArgumentException("参数不合法") : value;
11 }
12
13 static string GetName() => null;
14 }
8. 扩展异步返回类型(Generalized async return types)
以前异步的返回类型必须是:Task、Task<T>、void,现在 C# 7 中新增了一种类型:ValueTask<T>,如下所示:
1 public async ValueTask<int> Func()
2 {
3 await Task.Delay(3000);
4 return 100;
5 }
总结:ValueTask<T> 与 ValueTuple 非常相似,所以就不列举: ValueTask<T> 与 Task 之间的异同了,但它们都是为了优化特定场景性能而
新增的类型。
使用 ValueTask<T> 则需要导入: Install - Package System.Threading.Tasks.Extensions
9. 数字文本语法的改进(Numeric literal syntax improvements)
C# 7 还包含两个新特性:二进制文字、数字分隔符,如下所示:
1 var one = 0b0001; 2 var sixteen = 0b0001_0000; 3 4 long salary = 1000_000_000; 5 decimal pi = 3.141_592_653_589m;
注:二进制文本是以0b(零b)开头,字母不区分大小写;数字分隔符只有三个地方不能写:开头,结尾,小数点前后。
总结:二进制文本,数字分隔符 可使常量值更具可读性。
2-6 处处: http://www.cnblogs.com/zq20/p/6323205.html
7 出处:http://www.cnblogs.com/VVStudy/