作者:Bay0net
时间:2019-07-01 14:20:09
更新:
介绍:记录使用过的 wireshark 过滤规则
0x01、 使用介绍
抓包采用 wireshark,提取特征时,要对 session 进行过滤,找到关键的stream,这里总结了 wireshark 过滤的基本语法,供自己以后参考。(脑子记不住东西)
wireshark进行过滤时,按照过滤的语法可分为 协议过滤 和 内容过滤。
对标准协议,既支持粗粒度的过滤如HTTP,也支持细粒度的、依据协议属性值进行的过滤
如 tcp.port==53、http.request.method=="GET"
对内容的过滤,既支持深度的字符串匹配过滤如 http contains "Server"
也支持特定偏移处值的匹配过滤如 tcp[20:3] == 47:45:54
0x02、过滤规则
过滤 IP 和 mac 地址
ip 改成 eth,就是过滤 mac 地址
ip.addr == 8.8.8.8
ip.src == 8.8.8.8
ip.dst == 8.8.8.8
ip.addr == 10.0.0.0/16
过滤端口
下面的 tcp 可以改成 udp
tcp.port == 9090
tcp.dstport == 9090
tcp.srcport == 9090
tcp.port >=1 and tcp.port <= 80
根据长度过滤
tcp.len >= 7 (tcp data length)
ip.len == 88 (except fixed header length)
udp.length == 26 (fixed header length 8 and data length)
frame.len == 999 (all data packet length)
HTTP 数据包过滤
http.host == xxx.com
// 过滤 host
http.response == 1
// 过滤所有的 http 响应包
http.response.code == 302
// 过滤状态码 202
http.request.method==POST
// 过滤 POST 请求包
http.cookie contains xxx
// cookie 包含 xxx
http.request.uri=="/robots.txt"
//过滤请求的uri,取值是域名后的部分
http.request.full_uri=="http://1.com"
// 过滤含域名的整个url
http.server contains "nginx"
//过滤http头中server字段含有nginx字符的数据包
http.content_type == "text/html"
//过滤content_type是text/html
http.content_encoding == "gzip"
//过滤content_encoding是gzip的http包
http.transfer_encoding == "chunked"
//根据transfer_encoding过滤
http.content_length == 279
http.content_length_header == "279"
//根据content_length的数值过滤
http.request.version == "HTTP/1.1"
//过滤HTTP/1.1版本的http包,包括请求和响应
可用协议
tcp、udp、arp、icmp、http、smtp、ftp、dns、msnms、ip、ssl、oicq、bootp
0x03、知识学习
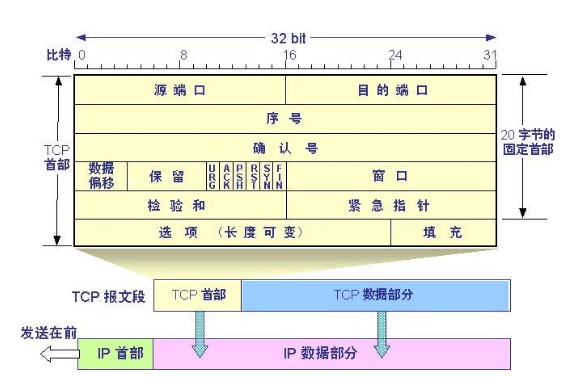
IP 报文

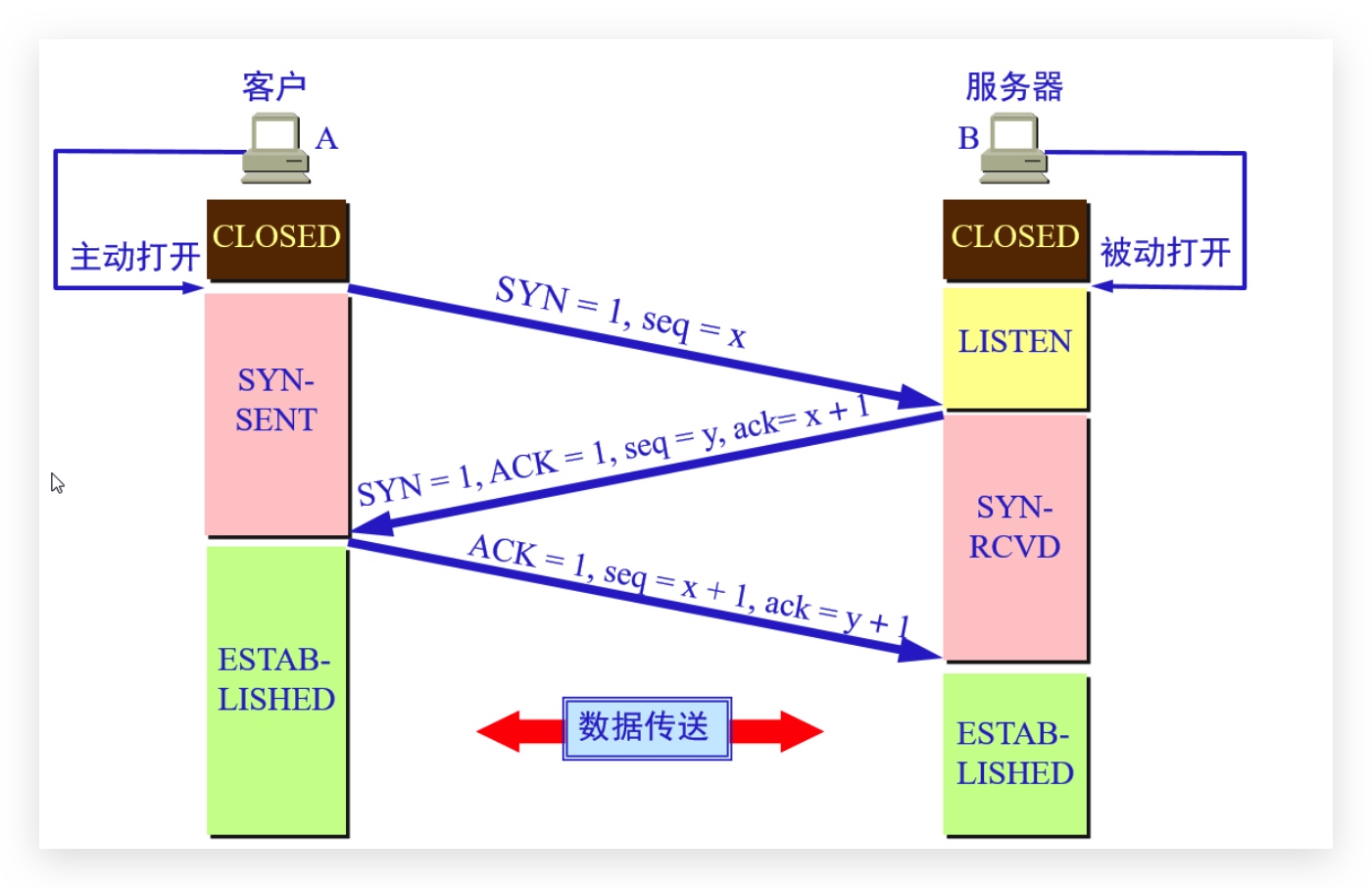
三次握手

实战
