腾讯与高校合作的论文入选数据库顶会
腾讯TDSQL团队携手中国人民大学信息学院、武汉大学计算机学院合作的DEMO论文“MSQL+: a Plugin Toolkit for Similarity Search under Metric Spaces in Distributed Relational Database Systems”被国际数据库顶级会议VLDB 2018录取。
该论文设计了一款基于RDBMS的插件式近似查询工具MSQL+。MSQL+遵循SQL标准,支持面向度量空间(一种比文本空间、向量空间等更为简洁和通用的表达方式)的近似查询,依托分布式数据库系统TDSQL,实现了通用、易用、高效的相似查询处理技术。
会议期间,团队展示了基于腾讯分布式数据库TDSQL实现的相似查询工具MSQL+,用于在分布式系统TDSQL中实现相似查询。在TDSQL数据库内部集成更多的计算功能,赋予数据库更为丰富的计算能力。
原论文请见http://www.vldb.org/pvldb/vol11/p1970-lu.pdf。论文信息如下:
Wei Lu, Xinyi Zhang, Zhiyu Shui, Zhe Peng, Xiao Zhang, Xiaoyong Du, Hao Huang, Xiaoyu Wang, Anqun Pan, Haixiang Li: MSQL+: a Plugin Toolkit for Similarity Search under Metric Spaces in Distributed Relational Database Systems. VLDB 2018 Demonstration
如果您想了解更多技术细节,请参考如下内容(如下重点介绍MSQL+的产生背景、功能、架构、设计):
论文解读
以下重点介绍MSQL+的产生背景、功能、架构、设计,原论文请见http://www.vldb.org/pvldb/vol11/p1970-lu.pdf。
MSQL+产生背景
相似查询是诸多数据库应用的基本操作。
举例来说,相似查询在文本检索、拼写检查、指纹认证、人脸识别等场景作用显著。
那么这些应用是如何进行相似查询的?给出对象q和集合R,返回R中与q相似度相差不超过θ的元素。最直接地,遍历r∈R,计算r与q的相似度,可想而知,此方法效率很低。
各领域已发展出多种方式对上述相似查询方式针对优化,但仍存在以下问题:
1与现有数据库系统剥离:现有的相似查询方法,大量建立新系统或新式索引提高效率,如M-Tree、D-Index、kd-tree等,虽说性能得以提升,但很难将其融合到现有RDBMS。另有一些方法基于B+-tree实现相似查询,但要在现有RDBMS上开发新API,而且效率表现不佳。这些方法缺少统一标准、兼容性差,每接触新方法,都要付出额外的学习成本。
2数据空间有限,普适性差:众多应用场景对“相似”的定义不同,衡量维度、数据类型不同,难以建立通用的相似查询模型。借助于定制化的剪枝规则,特定场景相似查询性能得到提升,但几乎不可能移植到其他应用场景。作为基本操作,相似查询应该具有普适性,在不同RDBMS应用中都能保证良好表现。
3仅适用中心化系统,难应对“大数据”场景:大数据时代下,借助于分布式系统维护日益增长的数据是大势所趋。遗憾的是现有的相似查询方式,并未良好地支持分布式系统。
为避免上述问题,MSQL+被设计为:基于RDBMS,遵循SQL标准,借力分布式数据库,以实现通用、易用、高效。在实际生产系统中,MSQL+以腾讯公司的分布式数据库TDSQL为依托,高效地实现了论文提出的思想和功能。
MSQL+主要功能
MSQL+由两大模块组成:
1构建索引:MSQL+为每个数据对象生成可比较的签名(Signature),并在签名上建立B+-tree索引,签名值位于相似度范围内的对象,作为相似查询的候选项;
2查询处理:用户提交SELECT-FROM-WHERE语句,该语句须提供两个约束条件,分别为:a) 用户定义的相似度函数,b) 相似度范围,条件b)初步筛选候选项,条件a)精炼候选项、返回相似结果集。
相比于现有的相似查询方式,MSQL+具备以下优势:
1基于RDBMS现有功能实现,使用B+-tree索引数据,使用SELECT-FROM-WHERE语句相似查询;
2支持广泛的数据空间:任意类型数据可被合理地索引(见下文设计),经由统一接口相似查询;
3可运行于单机和分布式RDBMS,依托分布式关系数据库系统TDSQL,能够加快预处理及相似查询进程。
MSQL+设计方案
本节将对MSQL+近似查询方案做简单介绍,细节请见原论文。
- Similarity Search in Metric Spaces
MSQL+采用分治策略,将完整的数据集划分成多个独立的分片,每个分片筛选出若干较为相似的候选者,这些候选者后续会被二次精选。
MSQL+如何划分数据集?论文说明,数据集内一些对象被选为pivot(下节介绍选举pivot的策略),剩余的数据对象按某种策略分配到唯一的pivot(比如,与之最近的pivot),这些pivot和分配至此的数据对象构成了一个分片。如此,完整的数据集被划分成多个互不相交的小数据集,然后在各分片内筛选较为相似的候选者。
筛选候选者的规则是什么呢?我们从一个例子入手:给出对象q和数据集R,相似查询返回R中与q相差不超过θ的数据对象。对分区Pi而言,筛选r∈Pi ,且|q,r|≦θ的对象r作为候选者。
定理 1:
对于分区Pi(其pivot为Pi),∀r∈Pi ,|q,r|≦θ的必要条件是:
LBi=|pi, q|-θ≦|pi, r|≦|pi, q|+θ = UBi
Pivot的挑选,是上述过程的基础,那么,MSQL+如何挑选pivot?
2. Pivot Selection
选择合适的pivot,可以加快筛选候选者及精选结果集的过程,论文提出了四种pivot选择方式:
1Random:从集合R中随机挑选对象作为pivot;
2MaxVariance:从集合R中挑选方差最大的一组对象作为pivots;
3MaxProb:pivot需满足,预期筛选出的候选项的个数最少;
4Heuristic:采取类似于k-means的启发式算法,整体上看,各分区中的元素尽量靠近pivot。
到此,已经可以筛选较为相近的候选者,那么,如何从中精选出更相近的结果集呢?
3. Processing similarity queries in RDBMS
为了快速精选出结果集,MSQL+在数据集上构建B+-tree索引,以下分两步,介绍该索引如何构建、如何使用。
论文做出定义:某表存储了数据集R,表上有M个属性(即M列),部分属性作为相似度的度量,记作A:{ A1, A2, ..., An } n≦M ,对于r∈R ,r[A]表示数据r属性{A1, A2, ..., An}的值。
3.1 Index Building
在A上建立B+-tree索引,有两个条件:a) 域{ A1, A2, ..., An }都是可比较的,b) 只需比较A各域的值即可精选候选项。借助于此索引,可方便地实现相似查询。那么,如何构建这样的索引?论文做出这样的设计:
对于r∈R,一张“签名表”(Signature generation schema)记录了r的签名S(r[A]),S(r[A])=<i, |r, Pi|>,其中i是分区ID,|r, Pi|是分区内数据对象r和pivot Pi的差距,签名的比较规则为:
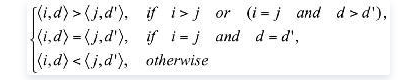
原表(存储数据集R)上新增一列I记录签名<i, |r, Pi|>,并在I上建立B+-tree索引,此索引满足“可比较”和“比较索引可确定候选项”两要素,故可借助此索引方便地近似查询。
3.2 Query Processing
至此,已经构建了合适的B+-tree索引,如何利用该索引精选候选者?
MSQL+支持用户自定义相似度函数DIST(r[A], q[A], θ),此函数判断r[A]和q[A]的距离未超过θ,用户定义相似度函数这一设计,扩展了MSQL+支持的数据空间和类型。有了DIST函数,用户输入SELECT-FROM-WHERE语句形如:
SELECT R.A1,...,R.An
FROM R
WHERE DIST(r[A], q[A], θ)
上面这条SQL,直接从数据集R中精确筛选结果集,效率堪忧。
候选者此时派上用场,定理1(见Similarity Search in Metric Spaces)描述了如何筛选候选者,减少精确筛选的数据量,加速精拣过程。结合定理1和DIST函数,用户输入SELECT-FROM-WHERE语句形如:
SELECT R.A1,...,R.An
FROM R, PivotsRangeSet PRS
WHERE I BETWEEN PRS.LB and PRS.UB AND
DIST(r[A], q[A], θ)
其中,临时表PivotsRangeSet维护了各pivot的LU和UB。因为PivotsRangeSet规模很小,查询优化器总会先索引扫描得到候选项,然后DIST函数精炼结果集。
MSQL+分布式架构
MSQL+既可在本地RDBMS上工作,又可部署在分布式RDBMS。论文给出MSQL+基于TDSQL的架构。
- System Architecture
1.1 TDSQL介绍
TDSQL是腾讯针对金融联机交易场景推出的高一致性,分布式数据库集群解决方案,能够保证强一致下的高可用,拥有灵活的全球部署架构,实现了倍数性能提升,增强了MySQL原生的安全机制,能够在水平方向上分布式扩展,具有自动化的运营体系和完善的配套设施。
TDSQL由以下关键组件构成:
1Routing Node:负载均衡;
2ZooKeeprt:维护系统元信息,如表、索引、分区等;
3Global Executor:接收SQL、下发local executor、汇集本地结果、生成执行计划等;
4Local executor:本地数据存、取、计算等。
1.2 TDSQL增益
MSQL+是一款由用户自定义函数、存储过程实现的插件式工具,可以无缝融入TDSQL。
MSQL+如何在TDSQL上工作呢?
ZooKeeper维护MSQL+特需的元信息,并同步至各local executors;Global executor接收相似查询请求,分发至各local executors执行,汇集最终结果并给出执行计划;Local executor完成本地分片相似查询,返回执行结果。
TDSQL又能给MSQL+带来什么样的增益?
首先是可靠、可用性,TDSQL实现了多副本强一致性,最大程度地保障MSQL+所需的大量样本数据的安全、可用、可靠。
其次,TDSQL支持水平方向分布式扩展,免除单机存储容量不足的后顾之忧,无论MSQL+样本数据多大,TDSQL都可轻松应对。
TDSQL在安全机制做出的优化,很大程度保证MSQL+样本数据的安全和机密。
我们最关心的性能问题,从分布式角度看,TDSQL多个本地节点并行查询,全局相似查询效率大幅度提升;具体到本地节点,TDSQL在数据库内核方面做出大量优化,使得单节点效率也有很大提升。
-
Index Building
ZooKeeper维护了全部pivot信息,并由Global executor将pivot信息下发至local executors。 Global executor协调local executors构建索引,每个local executor维护一定数量的分片,也就维护对应的pivots,基于这些pivots,local executor生成签名S(r[A]),进而构建起索引。 -
Query Processing
用户发起相似查询请求时,routing node选择一个global executor,global executor协调local executors并行执行相似查询,汇集本地执行结果并生成执行计划。
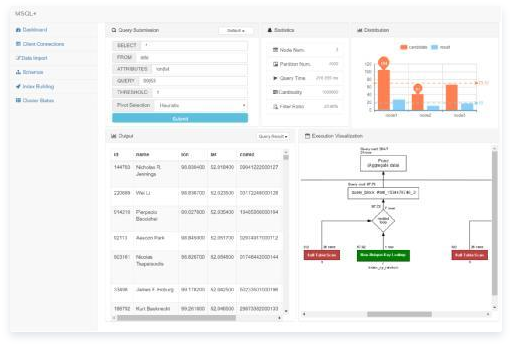
MSQL+界面展示
论文展示的操作界面如下,MSQL+支持相似查询、索引构建、客户端连接、集群管理、数据导入、查询状态显示、执行计划可视化等功能。
结论:
MSQL+是一款基于RDBMS的插件式近似查询工具,基于腾讯TDSQL实现,具有通用、易用、高效的特点:统一接口支持多种数据空间;遵循SQL标准,发起SELECT-FROM-WHERE命令即可完成相似查询任务;MSQL+依托腾讯分布式数据库TDSQL,实现了负载均衡、多点并行,可高效地完成相似查询。