原文链接:http://tecdat.cn/?p=12280
总览
本文简要介绍了一种简单的状态切换模型,该模型构成了隐马尔可夫模型(HMM)的特例。这些模型适应时间序列数据中的非平稳性。从应用的角度来看,这些模型在评估经济/市场状态时非常有用。这里的讨论主要围绕使用这些模型的科学性。
基本案例
HMM的主要挑战是预测隐藏部分。我们如何识别“不可观察”的事物?HMM的想法是从可观察的事物来预测潜在的事物。
模拟数据
为了演示,我们准备一些数据并尝试进行反向推测。通过构造,我强加了一些假设来创建我们的数据。每个状态都具有不同的均值和波动率。
library(knitr)
library(kableExtra)
library(dplyr)
theta_v <- data.frame(t(c(2.00,-2.00,1.00,2.00,0.95,0.85)))
names(theta_v) <- c("$\mu_1$","$\mu_2$","$\sigma_1$","$\sigma_2$","$p_{11}$","$p_{22}$")
kable(theta_v, "html", booktabs = F,escape = F) %>%
kable_styling(position = "center")| ( mu_1 ) | ( mu_2 ) | ( sigma_1 ) | ( sigma_2 ) | (p_ {11} ) | (p_ {22} ) |
|---|---|---|---|---|---|
| 2 | -2 | 1个 | 2 | 0.95 | 0.85 |
如上表所示,状态(s = 2 )变成“坏”状态,其中过程(x_t )表现出较高的变化性。 因此,停留在状态2的可能比停留在状态1的可能性小。
马尔可夫过程
为了模拟过程(x_t ),我们从模拟马尔可夫过程(s_t )开始。为了模拟(T )期间的过程,首先,我们需要构建给定(p_ {11} )和(p_ {22} )的转换矩阵。其次,我们需要从给定状态(s_1 = 1 )开始。从(s_1 = 1 )开始,我们知道有95%的概率停留在状态1,有5%的概率进入状态2。
p11 <- theta_v[1,5]
p22 <- theta_v[1,6]
P <- matrix(c(p11,1-p22,1-p11,p22),2,2)
P[1,]## [1] 0.95 0.05模拟(s_t )是递归的,因为它先前先前的状态。因此,我们需要构造一个循环:
set.seed(13)
T_end <- 10^2
s0 <- 1
st <- function(i) sample(1:2,1,prob = P[i,])
s <- st(s0)
for(t in 2:T_end) {
s <- c(s,st(s[t-1]))
}
plot(s, pch = 20,cex = 0.5)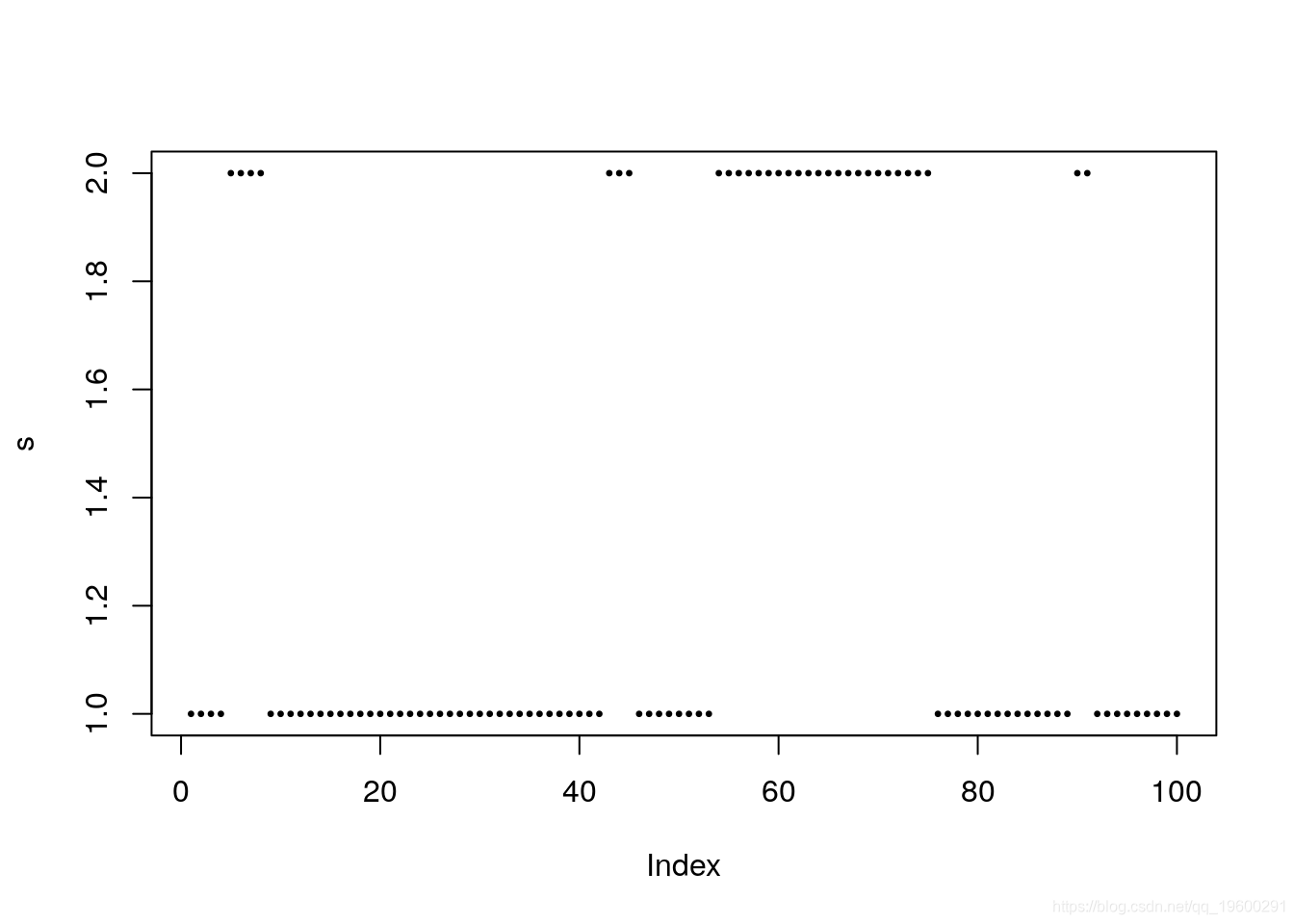
![]()
上图说明了过程(s_t )的持久性。在大多数情况下,状态1的“实现”多于状态2。实际上,这可以由固定概率确定,该固定概率由下式表示:
P_stat[1,]## [1] 0.75 0.25因此,经历时间的流逝,有15%的概率处于1状态,而有25%的概率处于状态2。这应该反映在模拟过程中 s,从而
mean(s==1)## [1] 0.69由于我们使用的是100个周期的小样本,因此我们观察到稳定概率为69%,接近但不完全等于75%。
结果
给定模拟的马尔可夫过程,结果过程的模拟非常简单。一个简单的技巧是模拟(x_t mid s_t = 1 )的(T )周期和 (x_t mid s_t = 2 )的(T )周期。然后,给定(s_t )的模拟,我们针对每个状态创建结果变量(x_t )。
plot(x~t_index, pch = 20)
points(x[s == 2]~t_index[s==2],col = 2)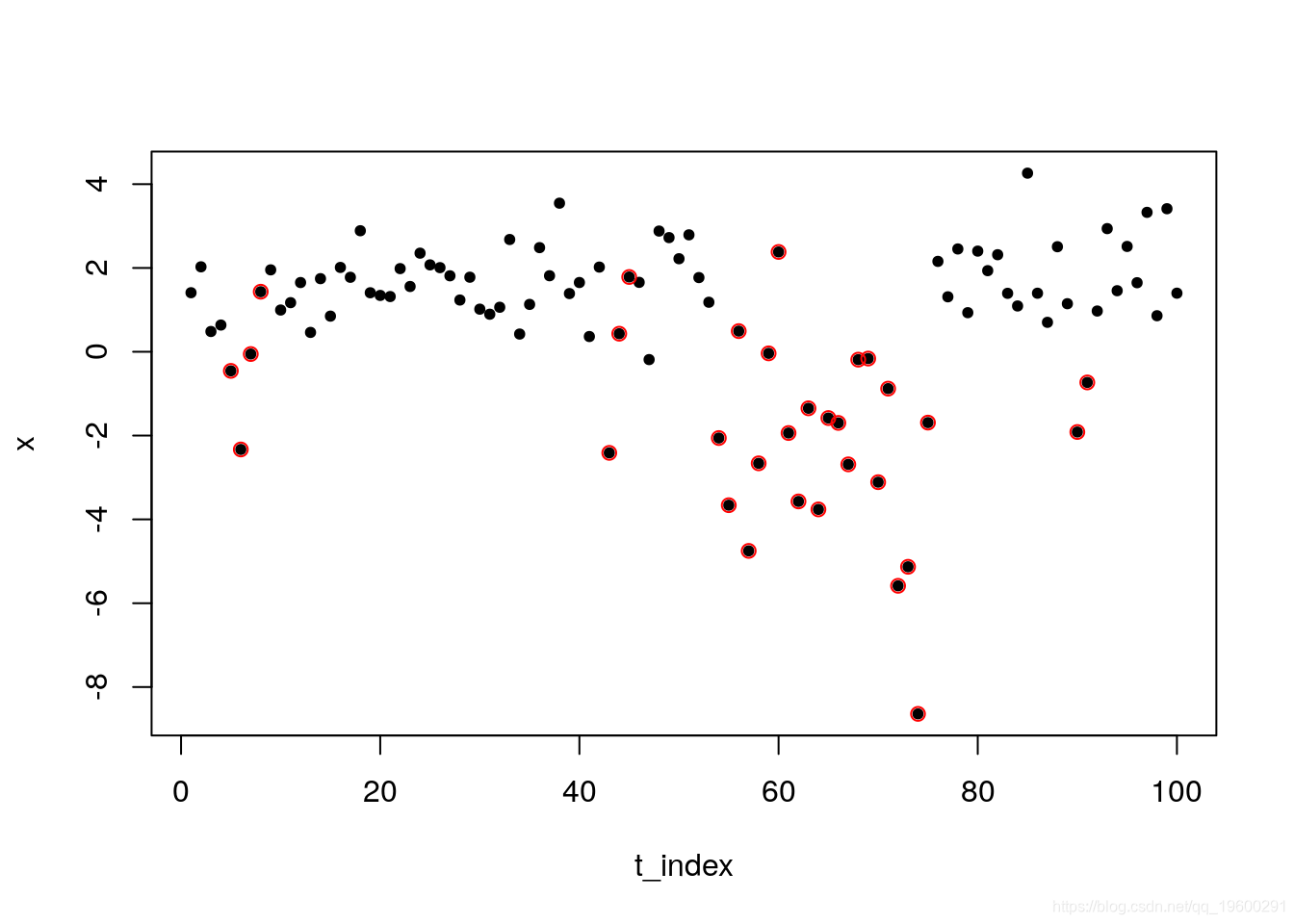
![]()
虽然总体而言时间序列看起来是平稳的,但我们观察到一些周期(以红色突出显示)显示出较高的波动。有人可能会建议说,数据存在结构性中断,或者体制发生了变化,过程(x_t )变得越来越大,带有更多的负值。虽然如此,事后解释总是比较容易的。主要的挑战是识别这种情况。
估计参数
在本节中,我将使用R软件手动(从头开始)和非手动进行统计分解。在前者中,我将演示如何构造似然函数,然后使用约束优化问题来估计参数。我将说明如何在不经历解析推导的情况下进行复制。
似然函数-数值部分
首先,我们需要创建一个以( Theta )向量为主要输入的函数。其次,我们需要设置一个返回MLE的优化问题。
在优化似然函数之前。让我们看一下工作原理。假设我们知道参数( Theta )的向量,并且我们有兴趣使用(x_t )上的数据评估隐藏状态随时间的变化。
| (t ) | ( xi_ {t mid t,1} ) | ( xi_ {t mid t,2} ) |
|---|---|---|
| 1 | 0.878 | 0.122 |
| 2 | 0.982 | 0.018 |
| 3 | 0.887 | 0.113 |
| 4 | 0.875 | 0.125 |
| 5 | 0.318 | 0.682 |
| 6 | 0.000 | 1.000 |
显然,这两种状态的每次过滤器的总和应为1。看起来,我们可以处于状态1或状态2。
all(round(apply(Filter[,-1],1,sum),9) == 1)## [1] TRUE由于我们设计了此数据,因此我们知道状态2的时期。
plot(Filter[,3]~t_index, type = "l", ylab = expression(xi[2]))
points(Filter[s==2,3]~t_index[s==2],pch = 20, col = 2)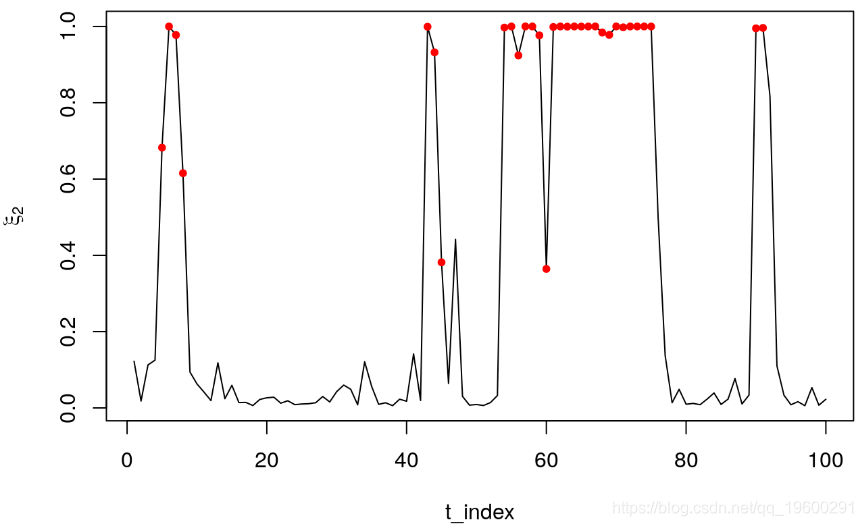
![]()
过滤器背后的优点是仅使用(x_t )上的信息来识别潜在状态。我们观察到,状态2的过滤器主要在状态2发生时增加。这可以通过发出红点的概率增加来证明,红点表示状态2发生的时间段。尽管如此,上述还是存在一些重大问题。首先,它假定我们知道参数( Theta ),而实际上我们需要对此进行估计,然后在此基础上进行推断。其次,所有这些都是在样本中构造的。从实际的角度来看,决策者对预测的概率及其对未来投资的影响感兴趣。
手动估算
为了优化上面定义的 HMM_Lik 功能,我将需要执行两个附加步骤。首先是建立一个初始估计值,作为搜索算法的起点。其次,我们需要设置约束条件以验证估计的参数是否一致,即非负波动性和介于0和1之间的概率值。
第一步,我使用样本创建初始参数向量( Theta_0 )
在第二步中,我为估算制定了约束
请注意,参数的初始向量应满足约束条件
all(A%*%theta0 >= B)## [1] TRUE最后,回想一下,通过构建大多数优化算法都可以搜索最小点。因此,我们需要将似然函数的输出更改为负值。
## $par
## [1] 1.7119528 -1.9981224 0.8345350 2.2183230 0.9365507 0.8487511
##
## $value
## [1] 174.7445
##
## $counts
## function gradient
## 1002 NA
##
## $convergence
## [1] 0
##
## $message
## NULL
##
## $outer.iterations
## [1] 3
##
## $barrier.value
## [1] 6.538295e-05为了检查MLE值是否与真实参数一致,我们绘制估计值与真实值的关系图:
plot(opt$par ~ theta_known,pch = 20,cex=2,ylab="MLE",xlab = "True")
abline(a=0,b=1,lty=2) 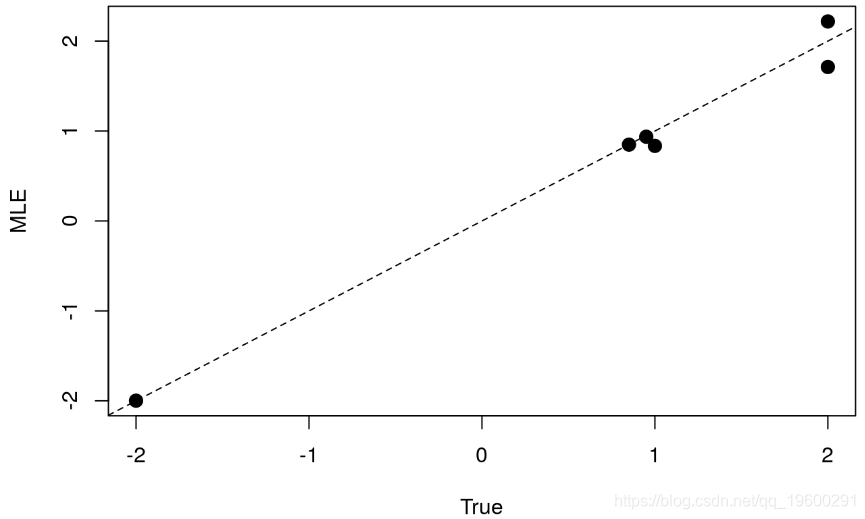
![]()
总体而言,我们观察到估计值非常一致,由于MLE的一致性属性,这不足为奇。
估算
我将在下面演示如何使用r软件复制人工估算的结果 。
如果我们要忽略过程中的任何体制转换,我们可以简单地将参数( mu )和( sigma )估计为
kable(mod_est, "html", booktabs = F,escape = F) %>%
kable_styling(position = "center")| ( hat { mu} ) | ( hat { sigma} ) |
|---|---|
| 0.6244574 | 2.198929 |
平均而言,我们应该期望过程平均值约为1,即(0.75 times 2 + 0.25 times(-1)= 1 )。这是由总期望属性定律得出的,其中我们知道 [ begin {equation} mathbb {E} [x] = sum _ { forall s} mathbb {E} left [x mid s 右] mathbb {P}(s)= sum _ { forall s} mu_ {s} pi_ {s} end {equation} ]
这样
EX <- 0.75*2 + 0.25*-2
EX## [1] 1对于波动率,适用相同的逻辑。
EX2 <- (2^2 + 1^2)*0.75 + ((-2)^2 + 2^2)*0.25
VX <- EX2 - EX^2
sqrt(VX)## [1] 2.179449我们注意到,回归估计值与波动率的一致性高于均值。这主要是由于估算第一时刻与第二时刻的工作比较繁琐。
上面的观点是,估计值并未涵盖数据的真实性质。如果我们假设数据是固定的,那么我们错误地估计过程的平均值为62%。但是,与此同时,我们通过构造知道该过程表现出两个平均结果-一个正面和一个负面。波动性也是如此。
为了揭示这些模式,我们在下面演示如何使用上面的线性模型部署状态切换模型:
主要输入是拟合模型, mod我们将其归纳为适应切换状态。第二个 k是制度的数量。由于我们知道我们要处理两个状态,因此将其设置为2。但是,实际上,需要参考一种信息标准来确定最佳状态数。根据定义,我们有两个参数,均值( mu_s )和波动率( sigma_s )。因此,我们添加一个true / false向量来指示正在切换的参数。在上面的命令中,我们允许两个参数都切换。最后,我们可以指定估计过程是否正在使用并行计算进行。
要了解模型的输出,让我们看一下
## Markov Switching Model
##
##
## AIC BIC logLik
## 352.2843 366.705 -174.1422
##
## Coefficients:
## (Intercept)(S) Std(S)
## Model 1 1.711693 0.8346013
## Model 2 -2.004137 2.2155742
##
## Transition probabilities:
## Regime 1 Regime 2
## Regime 1 0.93767719 0.1510052
## Regime 2 0.06232281 0.8489948上面的输出主要报告我们尝试手动估算的六个估算参数。首先,系数表报告了每个状态的均值和波幅。模型1的平均值为1.71,波动率接近1。模型2的平均值为-2,波动率约为2。显然,该模型针对数据确定了两种具有不同均值和波动率的不同状态。其次,在输出的底部,拟合的模型报告过渡概率。
plot(opt$par ~ theta_known,pch = 20,cex=2,ylab="MLE",xlab = "True")
points(theta_mswm~theta_known,pch = 1,col = 2, cex = 2,lwd = 2)
abline(a=0,b=1,lty=2)
legend("topleft",c("Manual","MSwM"), pch = c(20,1), col = 1:2)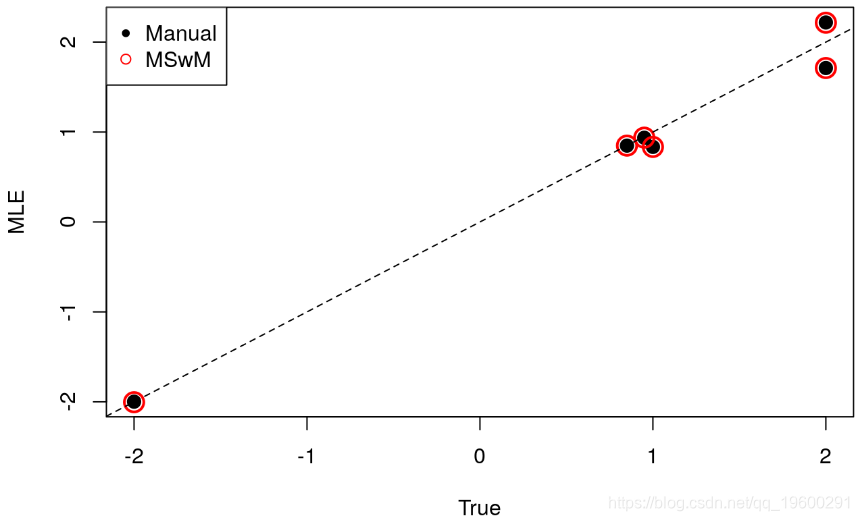
![]()
有趣的是,就每种状态的过滤器而言,我们将从包中检索到的状态与手动提取的状态进行比较。根据定义,可以使用mod.mswm 对象上的图函数 来了解平滑概率以及确定的方案。
par(mar = 2*c(1,1,1,1),mfrow = c(2,1))
plotProb(mod.mswm,2) 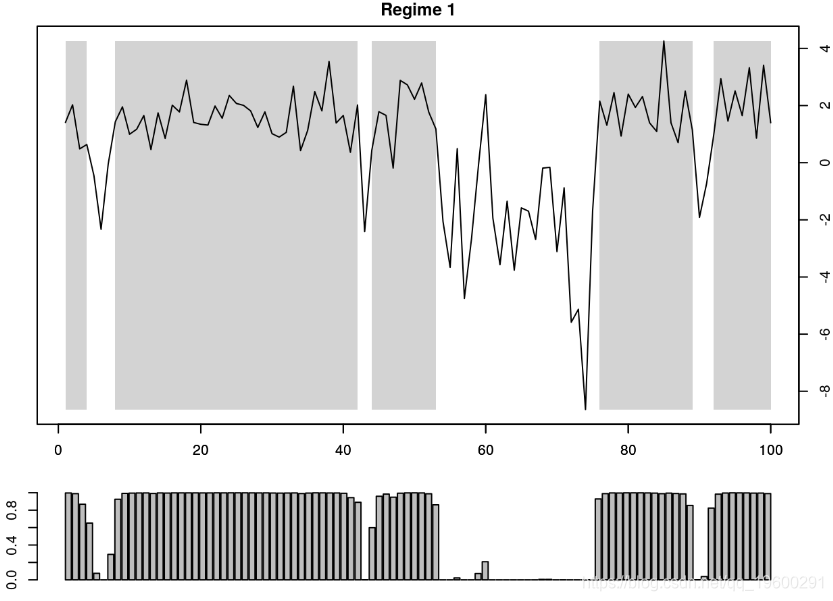
![]()
顶部的图表示随时间变化的过程(x_t ),其中灰色阴影区域表示( hat { xi} _ {T mid t,1}> 0.5 )的时间段。换句话说,灰色区域表示状态1占优势的时间段。
plot(x~t_index,type ="l",col = 0,xlim=c(1,100))
rect(xx-1,-10,xx,10,col = "lightgray",lty = 0)
lines(x~t_index)
points(x[s==2] ~ t_index[s==2],col = 1,pch = 20) 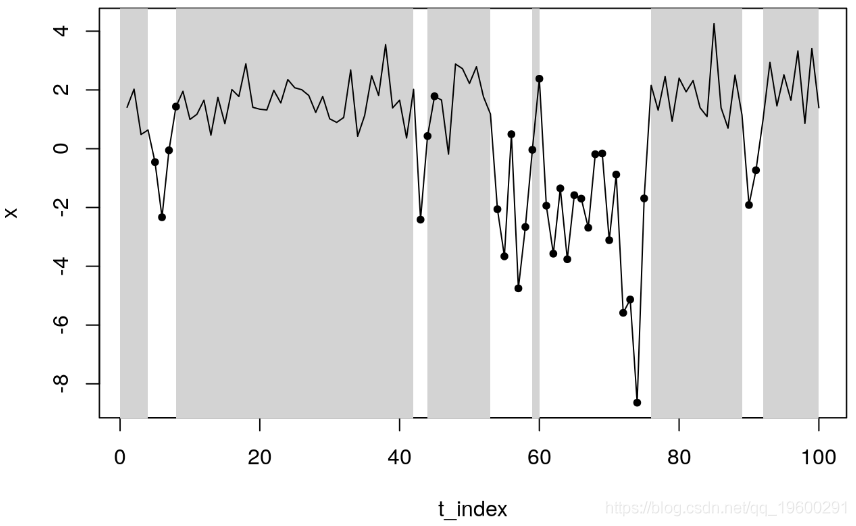
![]()
过滤器会在一个周期内检测到第二种状态。发生这种情况是因为 plotProb 在这种情况下,返回的是平滑概率,即在实现整个样本(T )后处于每种状态的概率,即( hat { xi} _ {t mid T,1} )。另一方面,来自手动估计的一个对应于推断概率( hat { xi} _ {t mid t,1} )。
无论如何,由于我们知道状态的真实值,因此可以确定我们是否处于真实状态。我们在上面的图中使用黑点突出显示状态2。总的来说,我们观察到模型在检测数据状态方面表现非常出色。唯一的例外是第60天,其中推断概率大于50%。要查看推理概率多长时间正确一次,我们运行以下命令
mean(Filter$Regime_1 == (s==1)*1)## [1] 0.96结束语
此过程似乎运行良好。然而,在实际数据实现方面仍然存在许多挑战。首先,我们不具备有关数据生成过程的知识。其次,状态不一定实现。因此,这两个问题可能会破坏状态切换模式的可靠性。在应用方面,通常部署此类模型以评估经济或市场状况。从决策上来说,这也可以为策略分配提供有趣的应用。