本文主要翻译自An Introduction to Gradient Descent and Linear Regression,原文写的通俗易懂,在文章最后还不忘推荐了一下吴恩达的机器学习课程。我不打算逐字逐句翻译,毕竟老外废话太多。
线性回归可以用最小二乘法直接求解。这里之所以选择线性回归的例子并用梯度下降求解,是为了阐明梯度下降算法的应用。
相关代码在这里。
简单来讲,线性回归的目的就是,对于一个给定的点集,找到一条直线对其进行拟合。考虑下图的数据:
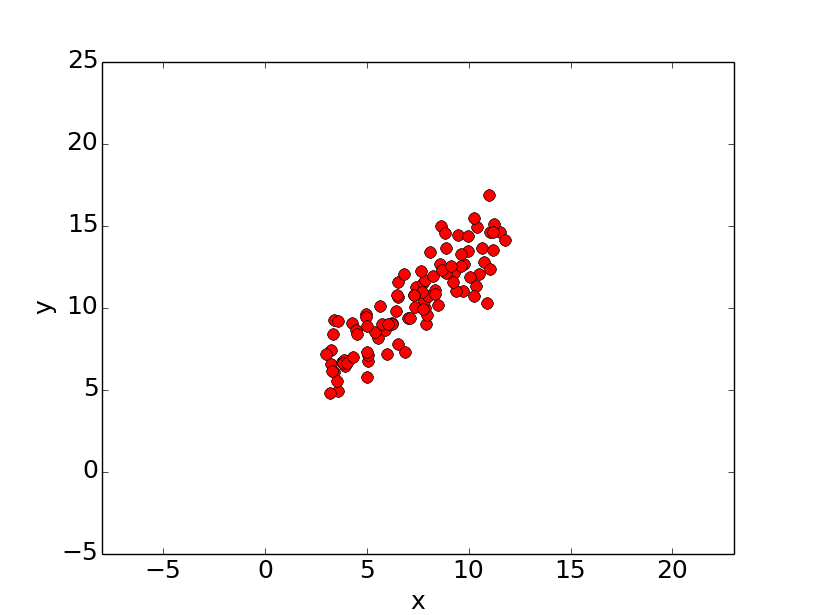
假设我们要使用一条直线对上述点集进行拟合。首先使用标准的直线方程y = mx + b,其中m是斜率,b是y轴截距。为了找到最好的直线,我们需要确定最合适的m和b。
该类问题的标准解法是定义一个误差函数(error function)来度量什么样的拟合直线比较好。常用的误差函数如下所示:

其中,m,b分别是给定直线的斜率和y轴截距,这是一个以(m,b)为自变量的二元函数。python实现如下:
# y = mx + b
# m is slope, b is y-intercept
def computeErrorForLineGivenPoints(b, m, points):
totalError = 0
for i in range(0, len(points)):
totalError += (points[i].y - (m * points[i].x + b)) ** 2
return totalError / float(len(points))
Error值越小,说明直线对数据集拟合程度越好。对该函数求最小值,就能得到最好的拟合直线。
既然误差函数是一个二元函数,我们可以将其视为二维曲面,如下图所示:
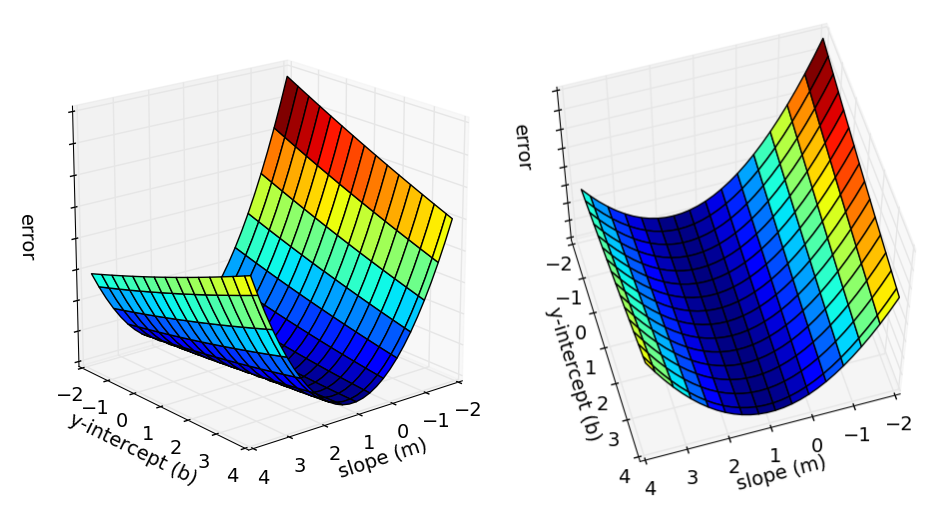
每一个点都表示一条直线,并且高就是误差。在执行梯度下降迭代时,我们从曲面上某一点开始,向下移动存在最小的误差。
我们首先要计算梯度,因为梯度是下降最快的方向。分别对m和b求偏导数:
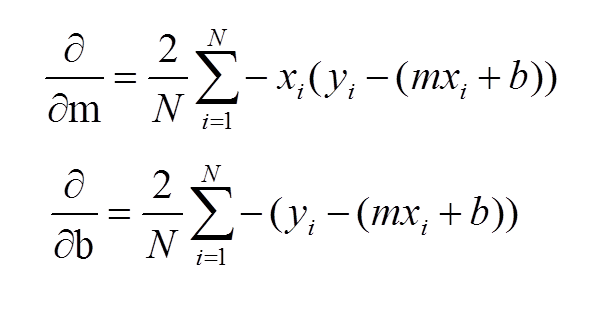
在迭代开始时,可以使用任意的m,b(误差函数是凸函数,求得的最小值一定是全局最小值)。每次迭代,都会重新计算偏导数(梯度)并更新m,b,得到一个比上次迭代更小的误差(如果学习率$alpha$过大,是有可能第i+1次迭代,误差高于第i次迭代的,不过第i+2次迭代,误差又会小于i+1次。总体上,误差还是越来越小的)。Python实现如下:
def stepGradient(b_current, m_current, points, learningRate):
# 求偏导数
b_gradient = 0
m_gradient = 0
N = float(len(points))
for i in range(0, len(points)):
b_gradient += -(2/N) * (points[i].y - ((m_current*points[i].x) + b_current))
m_gradient += -(2/N) * points[i].x * (points[i].y - ((m_current * points[i].x) + b_current))
# 更新m和b
new_b = b_current - (learningRate * b_gradient)
new_m = m_current - (learningRate * m_gradient)
return [new_b, new_m]
其中,learningRate是学习率$alpha$,也就是一次迭代的步长。
下图是2000次迭代的一些瞬间,我们从m = -1, b = 0开始。左侧展示了当前m和b的值(蓝点),以及经过的路径(黑线)。右侧是对应的拟合直线。
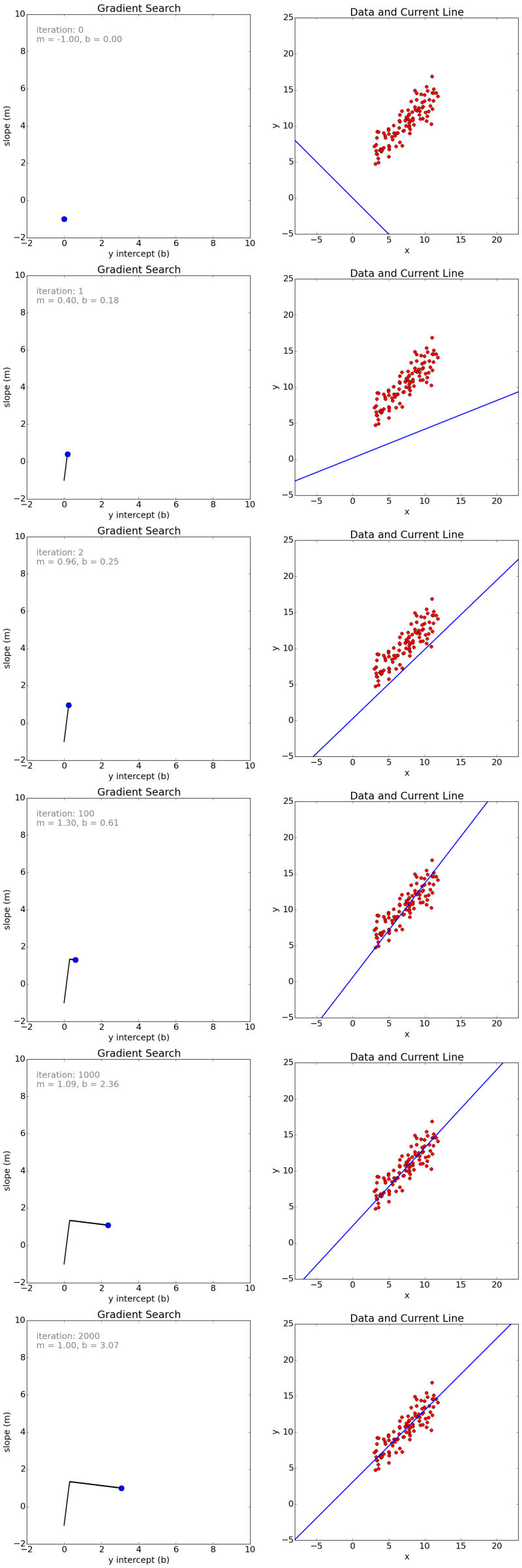
看了上图,有人也许会觉得奇怪。既然是从m = -1 b = 0开始的,那第一幅图的直线,为什么不经过原点(0,0)呢?事实上,图一的直线是经过原点的,只不过,图像的左下角不是我们习惯的原点,而是(-10,-5)点。我也不知道原作者为什么这么作图,反正这图看着有点考验智商。
我们也可以观察迭代次数和误差的关系,为确保梯度下降算法运行正确,我们可以确保每次迭代误差都是减小的。图像如下:

我们已经知道了怎么应用梯度下降求解线性回归问题。虽然在我们的例子中,模型是一条直线,但通过最小化误差函数来调整参数的思想,可以应用到高阶回归问题(regression problems that use higher order polynomials),或者机器学习的其他领域。
下面再介绍一些关于梯度下降的概念:
- 凸性(Convexity )——在我们上述的线性回归问题中,只有一个极小值。我们的误差曲面是凸面(convex)。不管从哪一点开始迭代,总能达到最小值。一般情况下,曲面可能存在多个极小值,导致梯度下降算法陷入局部极小值,无法得到全局最小值。有很多方法来缓解这一问题。(例如:stochastic gradient search)
- 性能(Performance)——我们使用批梯度下降(vanilla gradient descent,也就是普通的梯度下降,计算误差函数关于参数在整个数据集上的梯度。相对的,还存在随机梯度下降),设置学习率为0.0005并迭代2000次。这是一个线搜索(line search),可以减少迭代次数。
- 收敛(Convergence)——我们不讨论对少次迭代后可以得到一个可接受的结果。一般两次迭代得到的误差之差小于某一个很小的常数,就可以停止迭代(例如,梯度接近于0)。