浏览器驱动镜像下载地址:http://npm.taobao.org/
chromedriver的版本问题:如果出现版本不匹配,可以尝试换一个版本的chromedriver;
web自动化的元素定位--8大元素定位
6种元素:
- id:---id是唯一的,这时候可以用id定位
- name:---用户交互有关系,例如有input、select、textarea
- class_name:---定位的元素一定不能有空格,如果class_name很长,里面有空格,这时候可以只截取部分进行定位;如果复制整个class_name,就会报错
- link_text:---定位超链接文本
- partial_link_text:---定位超链接文本,部分匹配去查找
- tagname:---爬虫喜欢用
通过源码,可以知道:6大元素定位,最终都是通过css选择器定位;所以大体上来说只有css和xpath两种元素定位。
2种路径
xpath:---xml 路径语言,使用xpath分为绝对路径和相对路径,建议用相对路径
css:
xpath
写xpath表达式之前先去浏览器写,确定表达式没错,再写到Python中
语法介绍:https://www.w3schools.com/xml/xpath_intro.asp or https://www.w3school.com.cn/xpath/xpath_functions.asp
-
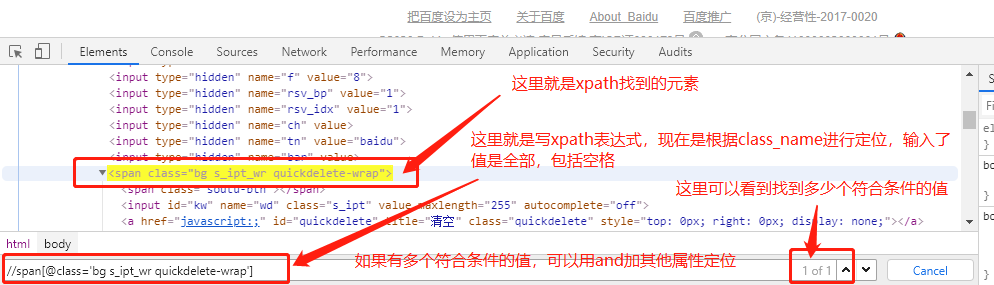
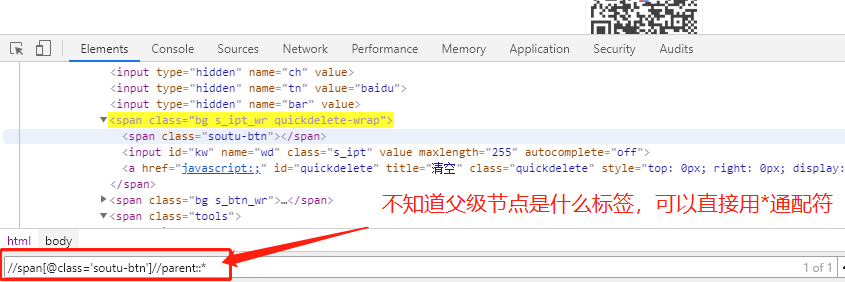
xpath相对路径://span[@class='bg s_ipt_wr quickdelete-wrap'] ---span是你要定位的标签名,然后[],里面以@开头,跟着元素值;
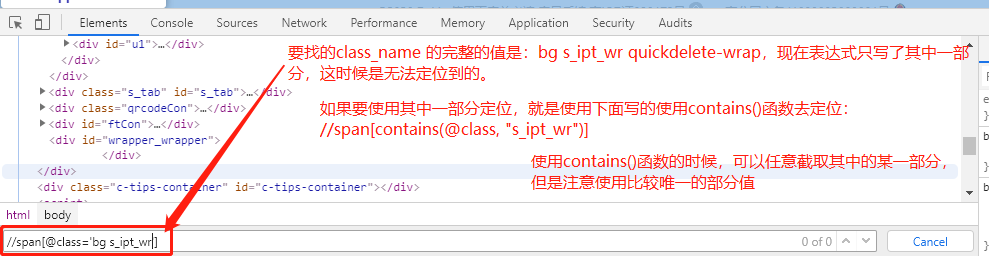
----注意:前面说使用class_name定位的时候,值不能有空格;但是当我们用xpath定位的时候,class_name需要复制全部值,包括空格,不然无法找到该元素
-
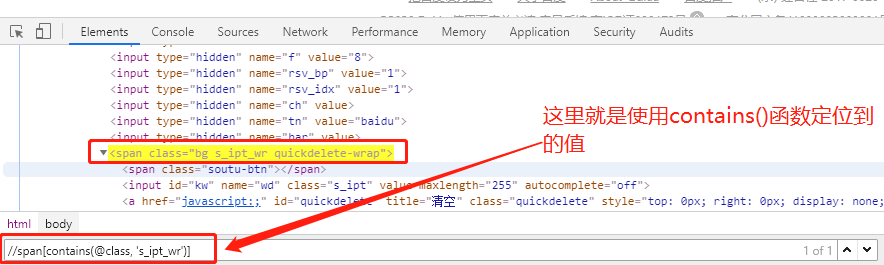
contain函数:当属性值很长的时候,可以使用contain函数,只写值的某一部分://span[contains(@class, 's_ipt_wr')]
----只有class_name里面包含了's_ipt_wr'就符合条件
-
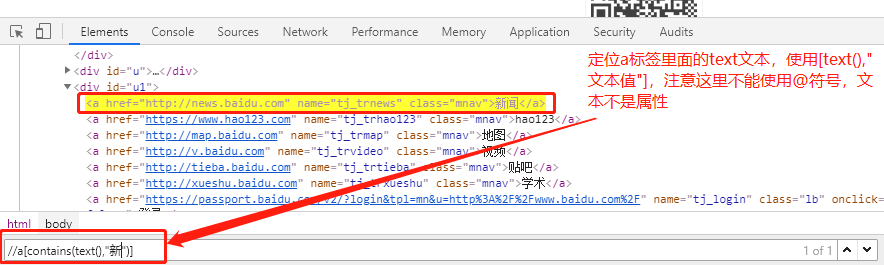
text文本在web自动化里面不是元素属性,不能用@符号去表示;直接写成: 标签名[text(),值],例如--//a[contains(text(),"新")]
-
xpath的索引是从1开始的。
----坑:一般不用,因为索引有时候会变;索引的优先级非常高,如果非要用索引定位,就需要手工提高其他部分的优先级,最后才用索引。例如:(//a[contains(text(),"新")])[1] -
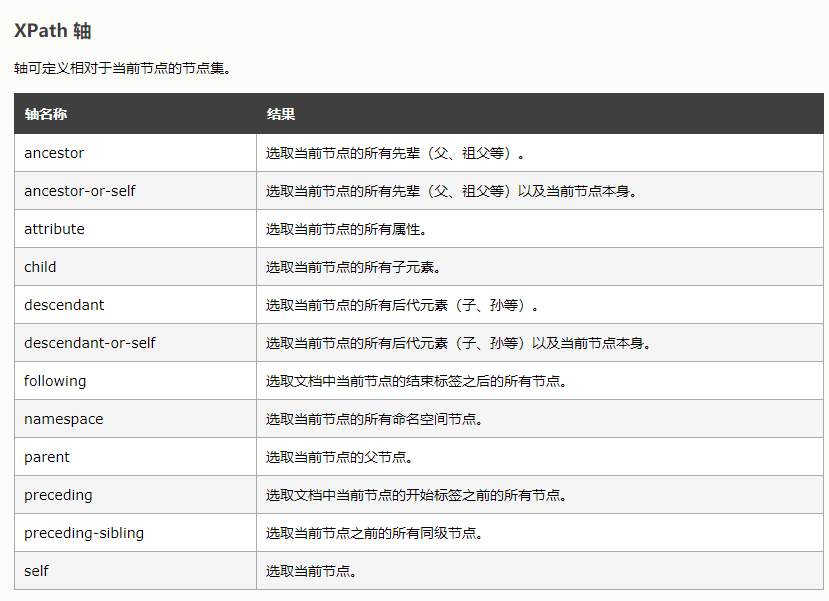
xpath轴定位:--面试常问需要记住轴定位的一些表达,根据上面的语法介绍链接学习
5.1 传统组合上下级关系,/和//,在两个元素之间:
---/表示父子关系://span[contains(@class, 's_ipt_wr')]/span[@class='soutu-btn']
---//表示祖先和孙子关系://form[@id='form']//span[@class='soutu-btn']
5.2 轴定位表示:
通过span去找form,就是定位到当前节点,通过当前节点找祖辈(当前节点名//ancestor::祖辈标签名):---//span[@class='soutu-btn']//ancestor::form[@id='form']

xpath总结点
- 什么时候使用xpath定位:
1.1 没有明显特征的元素,或者说明显特性元素找出来的值有很多个(例如id/name/class_name)
1.2 id/name/class_name不是唯一的时候 - 杜绝直接copy浏览器中的xpath,一个是因为copy出来的是绝对路径;另一个是copy的路径并不智能。并且在初学xpath的时候,不推荐使用xpath插件,工作中可以使用去提高效率---面试的时候xpath必考,需要自己可以熟练熟悉xpath表达式。
- 表示关系
3.1 . 或者..
3.2 /或者 // 只能从父级元素到子级元素
3.3 轴运算, //span[@class='soutu-btn']//parent::span 可以从子级找父级,只要记住关系名称、当前节点名称;
** 如果不知道要找的父级节点名称,可以用通配符* 代替 *----就是//span[@class='soutu-btn']//parent::
拓展:css选择器---可以自己看语法介绍
- input#kw: #代表了id
- input.soutu-btn: .代表了class_name
面试题
css和xpath的优劣势:
- css更加简洁
- xpath的功能更加强大,对于简单元素,使用css更加方便;对于复杂元素,使用xpath更合适;
- xpath可以通过文本进行定位,但是css不行;
- 效率。css的解析效率更快一定,xpath的效率比css低;
text()文本定位
- 在web自动化中,使用selenium有没有通过text文本进行定位的方法??
A:有,可以通过xpath对text文本进行定位。 - 在web自动化中,使用selenium有没有直接通过text文本进行定位的方式?
A:没有,selenium没有直接封装text定位的方式