1.问题描述
事故起止时间:
第一次 2019年03月05日 20时30分~ 21时20分
第二次 2019年03月06日 17时43分~ 18时21分
第三次 2019年03月10日 17时43分~ 03月11日10时21分
事故影响:客户端生产消费不可用,机器学习训练暂停
负责人:xxx、xxx、xxx
2.处理过程
第一次
机器学习小组发现客户端程序生产消费报错,查看cloud manager上kafka green集群运行状态,发现有几个kafka服务进程退出,接着查看集群各个kafka服务状态,发现kafka服务创建的文件描述符数量超过阀值,从而导致进程退出了。通过cloud manager管理平台修改文件描述符和jvm heap内存大小配置,重启kafka服务,逐步恢复客户端生产消费
报错内容如下:

修改配置如下:
文件描述符修改为:6553510 默认32767
jvm heap大小为:32G 默认1G

第二次
机器学习小组发现客户端程序生产消费报错,查看cloud manager上kafka green集群运行状态,发现有几个kafka服务进程退出,接着查看集群各个kafka服务状态,发现kafka服务创建的文件描述符数量超过阀值,从而导致进程退出了。根据 centos系统参数优化 修改,然后重启kafka服务,逐步恢复客户端生产消费
第三次
机器学习小组发现客户端程序生产消费异常,查看cloud manager上kafka green集群运行状态,发现有几个kafka服务进程还在,但是客户端生产/消费/副本复制都报错。通过cloud manager配置,将文件描述符数值从6553510改小到655350,重启生效。
3.定位分析

第一次 用cloud manager修改nofile文件描述符数量为6553500,重启服务
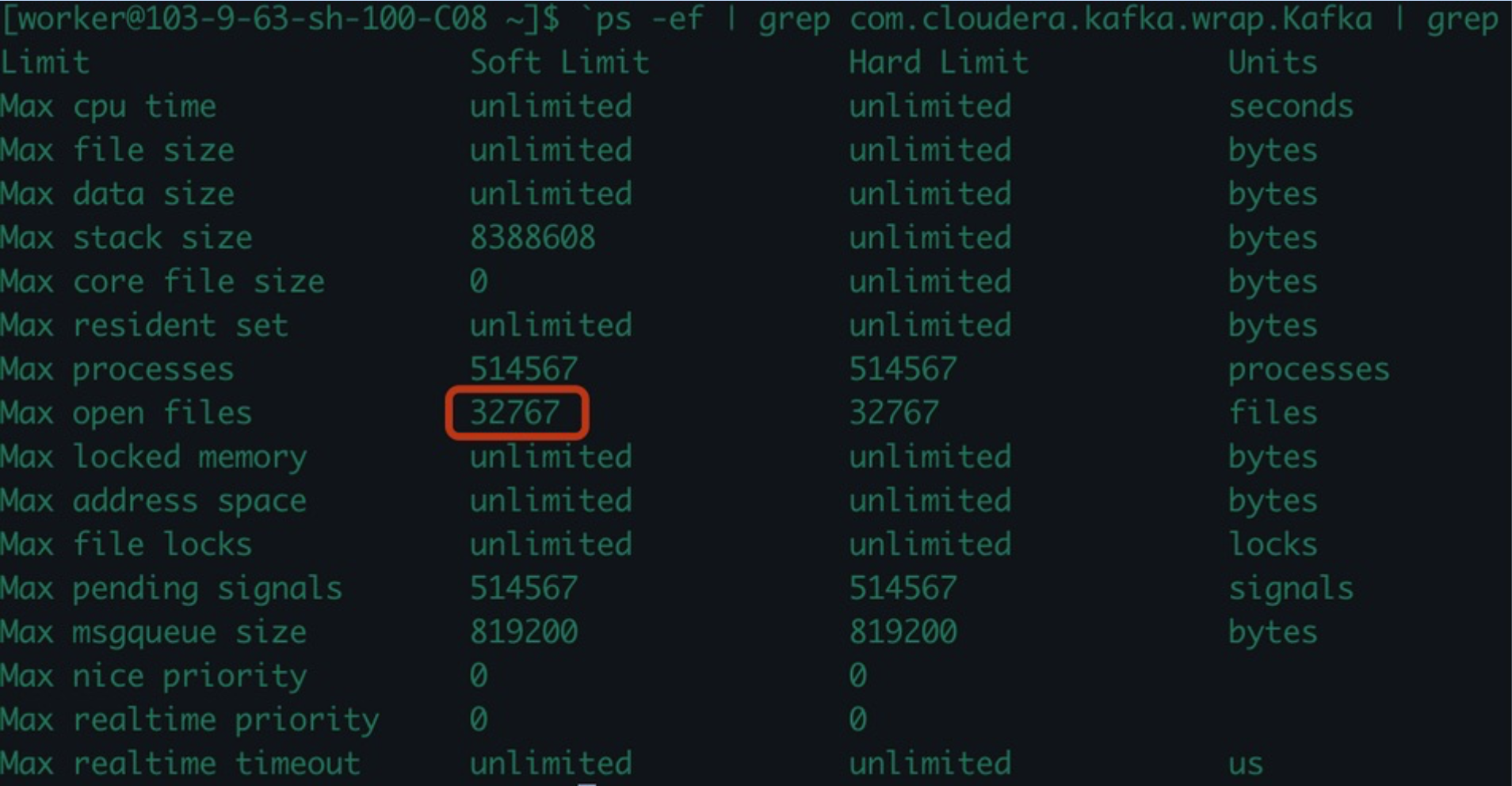
第二次 发现第一次修改文件描述未生效

通过cloud manager修改文件描述符分别为6553500、4553500、3553500、2553500服务重启重试,发现都无效,最后考虑通过修改虚拟文件系统参数和limits.conf配置文件的方式临时解决green集群问题。
随后通过命令 prlimit --pid [pid] --nofile=655350 修改虚拟文件系统数值,临时生效,但是重启无效