hadoop是当之无愧的大型数据处理的主流方向,对于这么重型的技术当然值得学习。
废话不多说,入题:
这几天抽空整了hadoop基础环境配置工作,(总体感觉配置有点繁琐,不够智能,人性化),对于服务搭建有三种模式:
单机实例,
单机伪分布式
集群分布式
第一种模式搭建服务的工作很简单
第二种没搭建过,如果要做分布式那就多台机器吧。
我把自己搭建hadoop过程中遇到的问题记录下来,如果有人遇到同样的问题便于解决。
由于是体验用,所以用到3台机器:
xx.xx.xx.239
xx.xx.xx.142
xx.xx.xx.172
以xx.xx.xx.239上操作为例:
1,安装jdk
方式1:yum install jdk
方式2:源码(略)
2,下载hadoop(版本,我选择0.20.2)
方式:wget -c http://apache.etoak.com/hadoop/common/hadoop-0.20.2/hadoop-0.20.2.tar.gz
3,解压:
tar -zxf hadoop-0.20.2/hadoop-0.20.2.tar.gz
4,创建安装目录
三台机器创建一致的目录结构
makdir -p /usr/hadoopApp
5,把解压的hadoop包 拷贝到其他两台机器的hadoopApp目录中
6,修改 hadoop-0.20.2/conf下的 hadoop-env.sh
vim hadoop-0.20.2/conf/hadoop-env.sh
//设置jdk目录
export JAVA_HOME="jdk目录"
//修改日志目录
export HADOOP_LOG_DIR=${HADOOP_HOME}/../logs
7,注意三台机器上保持一致
8,设置ssh 密码登陆(先在root目录下建立.ssh吧)
cd .ssh
ssh-keygen (联系3次回车)
cd ..
scp -rp .ssh root@xx.xx.xx.142:~/.ssh
//输入密码
scp -rp .ssh root@xx.xx.xx.172:~/.ssh
//输入密码
在239上测试下
ssh xx.xx.xx.142
ssh xx.xx.xx.172
在142上测试下
ssh xx.xx.xx.239
在172上测试下
ssh xx.xx.xx.239
都Ok
如果出现任然要输入密码才能登陆的情况,请检查3台机器登录用户是不是一样的,配置三台机器的hosts文件
239 hosts
xx.xx.xx.239 node-01
142 hosts
xx.xx.xx.142 node-01
172 hosts
xx.xx.xx.172 node-01
9,重点来了,配置hadoop节点
A.我以239机器作为,namenode,因此在239机器上操作:
B.slave服务器配置预先创建好:hadoop.tmp.dir,dfs.name.dir,dfs.data.dir,mapred.system.dircd /usr/hadoopApp/hadoop-0.20.2/confvim core-site.xml内容:<property><name>fs.default.name</name><value>hdfs://xx.xx.xx.xx:9000</value></property><!--hadoop store dir , 2012.7.13--><property><name>hadoop.tmp.dir</name><value>/usr/hadoopApp/hadoop.tmp.dir</value></property><!--<property><name>dfs.replication</name><value>1</value></property>-->vim hds-site.xml内容:<property><name>dfs.name.dir</name><value>/usr/hadoopApp/dfs.name.dir</value></property><property><name>dfs.data.dir</name><value>/usr/hadoopApp/dfs.data.dir</value></property><property><!--是否对dfs进行权限控制--><name>dfs.permissions</name><value>false</value></property><property><name>dfs.replication</name><value>2</value></property>vim mapred-site.xml内容:<property><name>mapred.job.tracker</name><value>192.168.134.239:9001</value></property><property><name>mapred.system.dir</name><value>/usr/hadoopApp/mapred.system.dir</value></property><property><name>mapred.local.dir</name><value>/usr/hadoopApp/mapred.local.dir</value></property>vim masters内容:xx.xx.xx.239vim slaves内容:192.168.129.142192.168.129.172
C.执行格式化把core-site.xml,hdfs-site.xml, mapred-site.xml 拷贝到142,172上分别修改142,172 的 master文件 增加一行代码:192.168.134.239142,172上的slaves文件设置为空
D.启动在239,142.172上(进入到hadoop目录bin)执行 ./hadoop namenode -format
在239上(进入到hadoop目录bin)执行 ./start-all.shE.经验:在启动后如果日志报错,这样做:1,看看是不是具有文件权限,2,删除新建目录下的文件,再重新执行./hadoop namenode -format
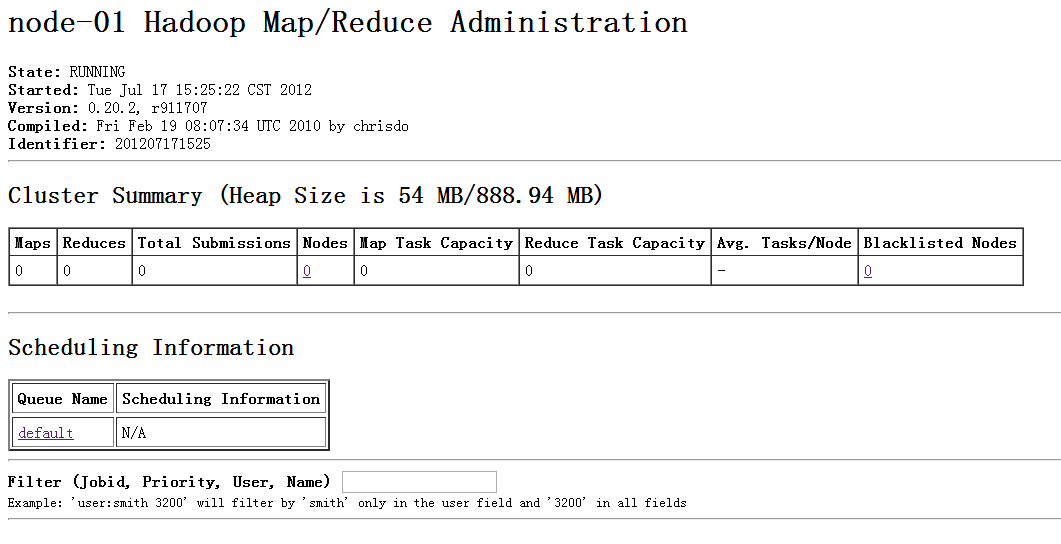
10.测试(看到下3张图,说明配置成功,并且可以在服务端上传文件操作了)
测试代码为:bin/hadoop dfs -put ~/libevent-2.0.19-stable.tar.gz ../dfs.data.dir_2


11.结语
这只是基本配置,对hadoop使用,架构还要花点时间来研究。