DeepWalk[1]这篇文章挺有意思的, 主要是讲怎么用Deep Learning的方法学图结构, 学出每个节点的隐含表示(比较像LSA、LDA、word2vec那种)。 发在了14年的KDD上, 咱们看到的是预览版本。
github地址作者也放出来了, github地址
下面大致讲一下文章是怎么弄得, 是个阅读笔记。
一、 介绍,优点
先说概念, 学出来什么样。 图a是输入图, 图b是输出。
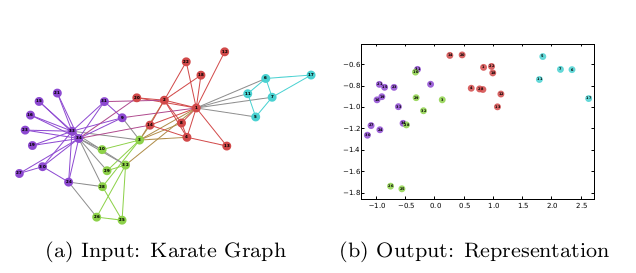
例子是将一个输入的图转化成了2维表示。 输入是图和图的自身结构,输出是二维表示。 例子应该是做的比较好的, 基本将本来是cluster的弄得也比较近, 不过这点比较容易。
优点:1) 与传统cluster、降维方法比, 这个方法的优点是可以调试, 也就代表着这东西可以堆数据, 因而在知识图谱,在社交网络上是有应用的。
2) 与传统cluster比能学到维度,能进一步利用。
3) 与降维比, 其实没什么优点, 但是图结构本身没有什么比较正常、有可以大规模使用的降维方法。
应用: 1. 社交网络学习特征;2. 知识图谱学习表示;3. 推荐系统学习低维度关联性。
二、 随机游走和语言模型
1. 随机游走
假设节点$v_i$处的随机游走是$W_{v_i}$,则全过程表示为$W_{v_i}^1,W_{v_i}^2,W_{v_i}^3,cdots,W_{v_i}^k$。
为什么要用随机游走:增加随机性,加速,可调,之类的。
2. zipfs law
这篇文章主要是说用word2vec的思想学图的, 所以一个非常重要的问题是, 词和图的节点像不像, 对于社交网络或者知识图谱来说,是没问题的, 见下图。
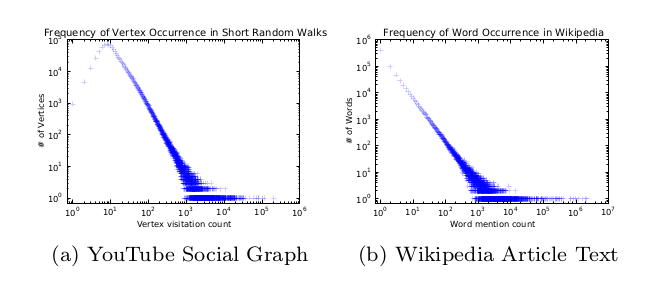
这说明词频和社交网络大致相等, 主要是要有那个比较剧烈的曲线。 这玩意也被叫做zipf 定律, 可以看统计自然语言处理,上面有详细说明。
3. 语言模型
语言模型主要是学词序列。词序列为:$W_1^n = (w_0,w_1,cdots ,w_n)$。
学的时候主要是学$Pr(w_n | w_0,w_1,cdots, w_{n-1})$ , 最常见的方法当然是n-gram, 现在新兴的是word2vec。
对于word2vec这样的模型来说, 既然是词向量, 那么学的也是概率表示,即:
$$ Pr(w_n | Phi(w_0), Phi(w_1),cdots, Phi(w_{n-1})) $$
随着路径长度增加, 学习难度会变困难。 一个比较好的(这段平心而论,我没看懂)方式是,用一个词去预测整个文章,且忽略词顺序。 优化问题如下
$$min(Phi) -log Pr ({w_{i-w},cdots, v_{i-1},v_{i+1} , cdots, v_{i+w} } | Phi(v_i) )$$
由于顺序被忽略了, 所以比较适合图学习, 因而有了这篇论文。 其实还是得感谢Minklov, 呵呵。
三、 训练方法
将图节点表示为词表(V)。
算法分两部分:1. 随机游走;2.更新过程
随机游走, 对图G,随机采样1节点$v_i$, 作为根节点$W_{v_i}$, 然后一直向周围采样,直到达到最大路径长度t。 算法如下:

其中3-9行是核心, 用skip-gram去更新。 skip-gram算法图如下:

这玩意也就是通常说的随机梯度。 后面还加了个层次softmax,用于加速。
核心流程: 1. 随机游走, 2. 用sgd学向量。 我倒是感觉其实最有意思的是随机游走那段。
四、 代码赏析
talk is cheap, show me the code。
文件基本上没几个, 非常少, __init__ 没啥用, main主要是调参数的, 这个没啥讲的, 自己看好了。

先看random walk怎么写的, 这是graph类的一个函数, graph就是封装了一个字典。 这个好水, 就是直接随了n个点。 然后加进去。
然后是skip-gram,如下:
就是封装了一下gensim的word2vec类,自己连动手都没。
核心训练过程,就下面这句

五、整体评价、实验结果
实验还行, 这玩意主要的有点是能学出结构, 实验不是特别搓就行。
评价: 从技术的层面上,没啥,random walk倒是用的很新颖。 没有跟spreading activation比较过。
参考文献:
[1] Perozzi B, Al-Rfou R, Skiena S. DeepWalk: Online Learning of Social Representations[J]. arXiv preprint arXiv:1403.6652, 2014.