设置标准I/O函数缓冲区的主要目的是为了提高性能。但套接字中的缓冲主要是为了实现TCP协议而设立的。例如,TCP传输中丢失数据时将再次传递,而再次发送数据则意味着在某地保存了数据。存在什么地方呢?套接字的输出缓冲中。与之相反,使用标准I/O函数缓冲的主要目的是为了提高性能。
实际上,缓冲并非在所有的情况下都能带来卓越的性能,但需要传输的数据越多,有无缓冲带来的性能差异越大。
缓冲区主要从如下两个方面带来性能提升:
1.传输的数据量
2.数据向输出缓冲移动的次数
比较一个字节的数据发送10次(10个数据包)的情况和累计10个字节发送1次的情况。发送数据时使用的数据包中含有头信息。头信息与数据大小无关,是按照一定格式填入的。即使假设该头信息占用40个字节(实际更大),需要传输的数据量也存在较大差别。
1个字节发送10次: 40 x 10 = 400字节
10个字节发送一次:40 x 1 = 40字节

另外,为了发送数据,向套接字输出缓冲移动数据也会消耗不少时间。但这同样与与移动次数有关。一个字节数据共移动10次花费的时间将近10个字节数据移动1次花费时间的10倍。
补充:
可以使用标准I/O函数收发数据。使用标准I/O函数主要有两个好处:
1.标准I/O函数具有良好的移植性。
2.标准I/O函数可以利用缓冲提高性能。
使用标准I/O函数传输数据时需要经过两个缓冲区。
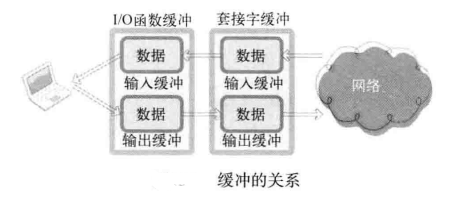
例如,通过fputs()函数传输字符串“hello”时,首先将数据传递到标准I/O函数的缓冲区。然后数据将移动到套接字输出缓冲,最后将字符串发送到对方主机。
