【实验项目名称】
手写数字特征提取方法与实现
【实验目的】
通过手写数字特征的提取,了解数字的特征提取方法,掌握特征匹配准则。
【实验原理】
读取标准化后的数字0~9,二值化,对每个数字进行等分区域分割,统计每个区域内的黑色像素点的个数,即为特征初值。采用欧式距离的模板匹配法判断数字。
【实验要求】
给定数字0-9的原始样本集合,每个数字都有100个大小为28*28的样本图像。要求如下:
1、将上述图像切分成标准图像库,存储为文件。
2、对每个数字进行等分区间分割。
3、给出统计结果:每个区域内的黑色像素点个数值以及占总量的百分比,显示出计算结果。
4、采用欧氏距离模板匹配法,给出识别结果。
5、从统计意义上,给出每个数字的识别率。
1.Python库的相关配置:OpenCV
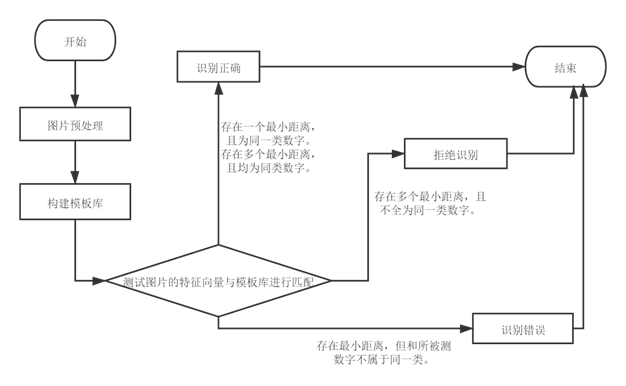
2.实验流程图:
3.实验步骤分析(包含有train图片集、test图片集):
1.图片预处理,该实验使用图片均已做过预处理,均为二值化的图像(0 和 255),黑底白字,28*28大小,如下图所示;









2.对所有train图片进行数据压缩,设计为28*28->7*7,也就是,每一个小方块中含有4*4=16个像素点,通过统计小方块中的像素值,分别给小方块标记为0或1(其中当白点超过16/2 = 8 个时,记该小方块为1,反之,记为0。可以知道,每一张图片可以被49个0_1字符串刻画。
3.对train图片集中所有图片进行上述处理,并将其字符串数据进行存储(可以设计为存储在一个txt文档,,称为模板库)。然后对test图片集中的每一张图片进行字符串转化,同样可以得到49个字符串的0_1数据,然后将其与模板库中的字符串数据进行对比,其中,欧氏距离最小的即认为是和该测试图片是同一类数字。以此分辨手写数字图片。
4.关于各种统计率的计算:[正确率]--(最小距离唯一,且两个图片数字属于同一类)或者(存在多个最小距离,但是均属于同一类数字);
[拒绝识别率]--(存在多个最小距离,并且不全部属于同一类数字,无法正常分类);
[错误率]--(最小距离唯一,并且两个图片不属于同一类数字);
5.为了更好地判断两个图片是否属于同一类数字,故一般在其49个字符数据前加上一些标记符号,用来表示该字符串属于哪个数字。
4.Python实现(其中路径绝对方式给出):
one_test.py文件:(该文件中代码复杂主要在于三种识别率的计算,其中关于每类识别得统计判断有点繁杂,需耐心)
Function.Image_Compression(root_dir) -------图像压缩,返回压缩数据流
Function.Distance(test_str, train_str)--------计算样本间距


1 # 基于模板的手写数字识别 2 import os 3 import cv2 4 import Function # 关于该实验中需要调用的函数 5 # 1.样本特征,不需预处理 6 # 2.图像压缩表示,28*28——7*7,存储于(E:PatternRecognitionpicture7_7.txt) 7 root_dir = "E:/train-images" # 训练数据集 8 file7_7 = open("E:/PatternRecognition/picture7_7.txt", 'w') # 覆盖写模式 9 for fl in os.listdir(root_dir): # 循环处理所有train图片 10 img_str = fl[0:-4] + ":" + Function.Image_Compression(root_dir + '/' + fl) # 图像压缩,返回压缩数据流 11 file7_7.write(img_str + ' ') # 压缩后的图像数据写入文本存储 12 file7_7.close() 13 # 3.待测样本的相似性比较,根据最近距离判断 14 # 4.根据相似性比较给出识别结果,并给出统计意义上的正确率,错误率,拒绝识别率 15 file7_7 = open("E:/PatternRecognition/picture7_7.txt", 'r') # 只读模式 16 root_dir = "E:/test-images" # 测试test-images数据集 17 Correct_rate = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] 18 Error_rate = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] 19 Rejection_rate = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] 20 ############ 21 for fl in os.listdir(root_dir): # 循环处理所有test图片 22 # 一些必备的基础数据变量 23 Same_dist_number = 0 # 用于记录最小距离时,是否存在多个标准样本,并标记个数 24 Same_class = -1 # 当有多个相同距离时,如果他们均为同一类别,则标记为该类别;-1表示可直接判断。 25 min_dist = 7 # 用于存储判断最小距离 26 dist_img = "" # 用于标记当前最小距离时,属于哪个数字图片 27 # 开始处理test图片的匹配识别 28 test_img_str = Function.Image_Compression(root_dir + '/' + fl) # test图片数据 29 while True: 30 line = file7_7.readline() 31 if not line: # 已读完整个文档,光标返回开头,结束此次匹配 32 file7_7.seek(0) 33 break 34 train_str = line[-50:-1] # train图片数据 35 temp_dist = Function.Distance(test_img_str, train_str) # 计算样本间距 36 if temp_dist < min_dist: # 更新min_dist/dist_img/Same_dist_number 37 min_dist = temp_dist 38 dist_img = line[0:-51] # 提取最小距离的图片名称,即属于哪个数字 39 Same_dist_number = 0 # 出现最小距离,个数归零 40 Same_class = -1 # 出现最小距离,不需要类别判断 41 elif temp_dist == min_dist: 42 Same_dist_number += 1 # 表示具有相同距离的数字 43 if dist_img[0:1] == line[0:1]: # 样本间距相等,同时是同一类的样本 44 Same_class = eval(line[0:1]) # 记录同一类别 45 else: 46 Same_class = -1 # 表明,同时具有不同类的数字样本与测试数字距离相等 47 # 识别结果 以及 识别结果的数据统计 48 # a.Same_dist_number = 0 ,表明可以直接识别出来,但不保证正确率 49 # b.Same_dist_number != 0 and Same_class = -1 ,拒绝识别,同时有不同数字与其距离相等 50 # c.Same_dist_number != 0 and Same_class ,可以识别,表示同一类数字中多个样本与其距离相等 51 if Same_dist_number == 0: # 该数字可以识别 52 print("测试数字:", fl[0:-4], " -- 识别出来的结果:", dist_img) # 数字的识别结果 53 if fl[0] == dist_img[0]: 54 Correct_rate[eval(fl[0])] += 1 # 正确识别 55 else: 56 Error_rate[eval(fl[0])] += 1 # 识别错误 57 elif Same_class == -1: # 拒绝识别 58 print("测试数字:", fl[0:-4], " -- 该数字拒绝识别!") 59 Rejection_rate[eval(fl[0])] += 1 # 拒绝识别 60 else: # 同一类数字中多个样本与其距离相等 61 print("测试数字:", fl[0:-4], " -- 识别出来的结果(类):", Same_class) 62 if eval(fl[0]) == Same_class: 63 Correct_rate[eval(fl[0])] += 1 # 正确识别 64 else: 65 Error_rate[eval(fl[0])] += 1 # 识别错误 66 file7_7.close() 67 print("------------------------------------------------") 68 for i in range(10): 69 print("数字 {:d} 识别的正确率 = {:.2f}% ,错误率 = {:.2f}% ,拒绝识别率 = {:.2f}%".format(i, Correct_rate[i]*5, Error_rate[i]*5, Rejection_rate[i]*5)) 70 print("success!")
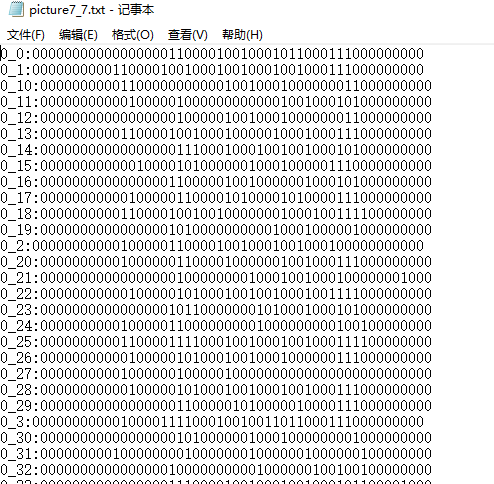 <<----------------------数据流显示
<<----------------------数据流显示
5.两个函数:
Function.py文件:(包含两个需要常调用的函数)
Image_Compression(img_path)
1 import cv2 2 3 ####################### 4 # 实现图像压缩,28*28——7*7,并以49数据流返回,img_path--图片路径 5 # 划分为4*4的像素矩阵,其中八个及以上的像素点超过127即记为1,反之为0 6 # 参数img_path,必须为完成的图片路径 7 ####################### 8 def Image_Compression(img_path): 9 # 数据按行存储 10 img_str = "" # 存数据流 11 img = cv2.imread(img_path) 12 # print("图像的形状,返回一个图像的(行数,列数,通道数):", img.shape) 13 x = y = 0 # img像素点坐标表示img[x][y] 14 for k in range(1, 50): # k的范围1-49 15 totle_img = 0 # 统计满足要求的像素点数目 16 for i in range(4): 17 for j in range(4): 18 if img[x + i - 1][y + j - 1][0] > 127: 19 totle_img += 1 20 y = (y + 4) % 28 21 # 一个矩形阵中包含16个像素点,其中像素值大于127的点超过八个记为1,反之记为0 22 if totle_img >= 8: 23 img_str += '1' 24 else: 25 img_str += '0' 26 if k % 7 == 0: # 控制x,y的变化 27 x = x + 4 28 y = 0 29 return img_str
Distance(test_str, train_str)
1 ####################### 2 # 计算测试样本与标准样本之间的距离,返回以距离,test_str--测试,train_str--标准 3 # 其中test_str,train_str均必须保证为49个字符串形式的数字 4 # 返回一个double类型的数据 5 ####################### 6 def Distance(test_str, train_str): 7 len_str = len(train_str) # 数据长度 8 dist = 0.0 9 for i in range(len_str): # 计算距离 10 dist += (eval(test_str[i:i+1]) - eval(train_str[i:i+1]))**2 11 dist **= 0.5 12 return dist
6.1匹配结果:(test是从train里面提取出来的若干图片合集)

数字 0 识别的正确率 = 100.00% ,错误率 = 0.00% ,拒绝识别率 = 0.00%
数字 1 识别的正确率 = 45.00% ,错误率 = 0.00% ,拒绝识别率 = 55.00%
数字 2 识别的正确率 = 85.00% ,错误率 = 0.00% ,拒绝识别率 = 15.00%
数字 3 识别的正确率 = 80.00% ,错误率 = 0.00% ,拒绝识别率 = 20.00%
数字 4 识别的正确率 = 90.00% ,错误率 = 0.00% ,拒绝识别率 = 10.00%
数字 5 识别的正确率 = 80.00% ,错误率 = 0.00% ,拒绝识别率 = 20.00%
数字 6 识别的正确率 = 90.00% ,错误率 = 0.00% ,拒绝识别率 = 10.00%
数字 7 识别的正确率 = 95.00% ,错误率 = 0.00% ,拒绝识别率 = 5.00%
数字 8 识别的正确率 = 100.00% ,错误率 = 0.00% ,拒绝识别率 = 0.00%
数字 9 识别的正确率 = 85.00% ,错误率 = 0.00% ,拒绝识别率 = 15.00%
6.2匹配结果:(其他方式构建的图片)
暂无
7.总结:
实验可以通过特征压缩的方式来适当减少特征值的数量,然后再进行模板匹配,需要注意的是,特征值得压缩需要处于适当的范围。特征值过多会导致计算数据多大,匹配速度较慢,反之,特征值过少,对数据的判别存在较大的误差。总的来说,对于模板匹配识别方式,计算量较大,匹配速度较慢。
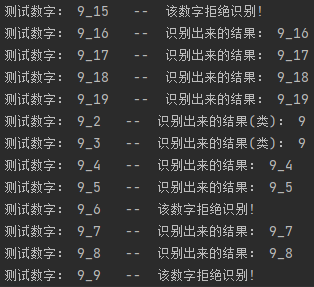
2021-04-29