不多说,直接上干货!
我的集群机器情况是 bigdatamaster(192.168.80.10)、bigdataslave1(192.168.80.11)和bigdataslave2(192.168.80.12)
然后,安装目录是在/home/hadoop/app下。
官方建议在master机器上安装Hue,我这里也不例外。安装在bigdatamaster机器上。
Hue版本:hue-3.9.0-cdh5.5.4
需要编译才能使用(联网)
说给大家的话:大家电脑的配置好的话,一定要安装cloudera manager。毕竟是一家人的。
同时,我也亲身经历过,会有部分组件版本出现问题安装起来要个大半天时间去排除,做好心里准备。废话不多说,因为我目前读研,自己笔记本电脑最大8G,只能玩手动来练手。
纯粹是为了给身边没高配且条件有限的学生党看的! 但我已经在实验室机器群里搭建好cloudera manager 以及 ambari都有。
大数据领域两大最主流集群管理工具Ambari和Cloudera Manger
Cloudera安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
Ambari安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
首先,在这里,先给大家普及知识。
对于hive的安装是有3种方式的:
1.本地derby
2.本地mysql (比如master、slave1、slave2集群。hive一般我是安装在master上)(也叫作hive单用户模式)
当然,你也来个master、slave1、slave2集群,外加client专门来安装hive、sqoop、azkaban这样的。
或者,你也来个master、slave1、slave2、slave3、slave4集群,hive一般我也是安装在master上。
3..远端mysql (在主从上配)(也叫作hive多用户模式)
(比如master、slave1、slave2集群。hive一般我是安装在master和slave1上)
或者,你也来个master、slave1、slave2、slave3、slave4集群,hive一般我也是安装在master和slave1上。
Hadoop Hive概念学习系列之hive三种方式区别和搭建、HiveServer2环境搭建、HWI环境搭建和beeline环境搭建(五)
https://www.cloudera.com/documentation/enterprise/latest/topics/cdh_ig_hue_config.html#concept_ezg_b2s_hl

首先,来看看官网提供的参考步骤
http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.5.0/manual.html
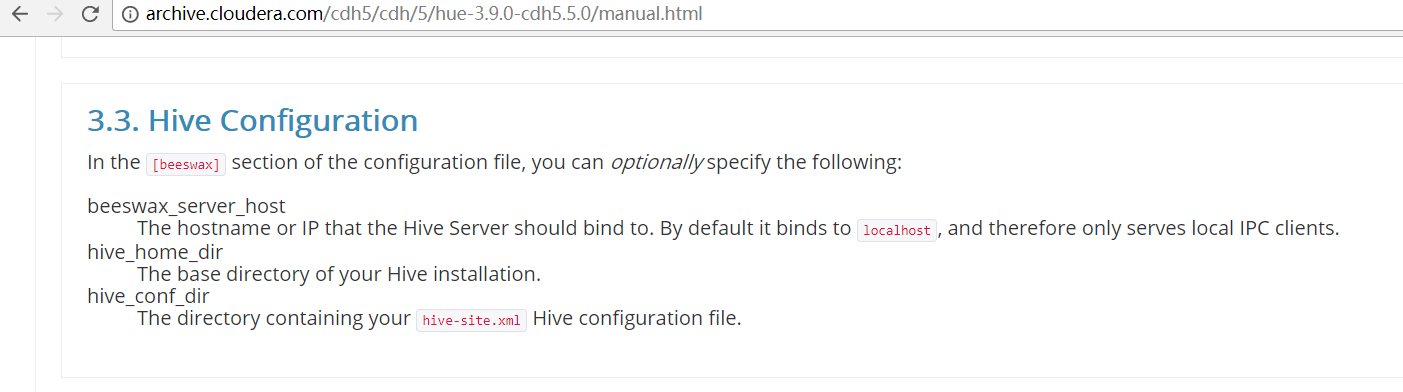
一、以下是默认的配置文件

########################################################################### # Settings to configure Beeswax with Hive ########################################################################### [beeswax] # Host where HiveServer2 is running. # If Kerberos security is enabled, use fully-qualified domain name (FQDN). ## hive_server_host=localhost # Port where HiveServer2 Thrift server runs on. ## hive_server_port=10000 # Hive configuration directory, where hive-site.xml is located ## hive_conf_dir=/etc/hive/conf # Timeout in seconds for thrift calls to Hive service ## server_conn_timeout=120 # Choose whether to use the old GetLog() thrift call from before Hive 0.14 to retrieve the logs. # If false, use the FetchResults() thrift call from Hive 1.0 or more instead. ## use_get_log_api=false # Set a LIMIT clause when browsing a partitioned table. # A positive value will be set as the LIMIT. If 0 or negative, do not set any limit. ## browse_partitioned_table_limit=250 # A limit to the number of rows that can be downloaded from a query. # A value of -1 means there will be no limit. # A maximum of 65,000 is applied to XLS downloads. ## download_row_limit=1000000 # Hue will try to close the Hive query when the user leaves the editor page. # This will free all the query resources in HiveServer2, but also make its results inaccessible. ## close_queries=false # Thrift version to use when communicating with HiveServer2. # New column format is from version 7. ## thrift_version=7
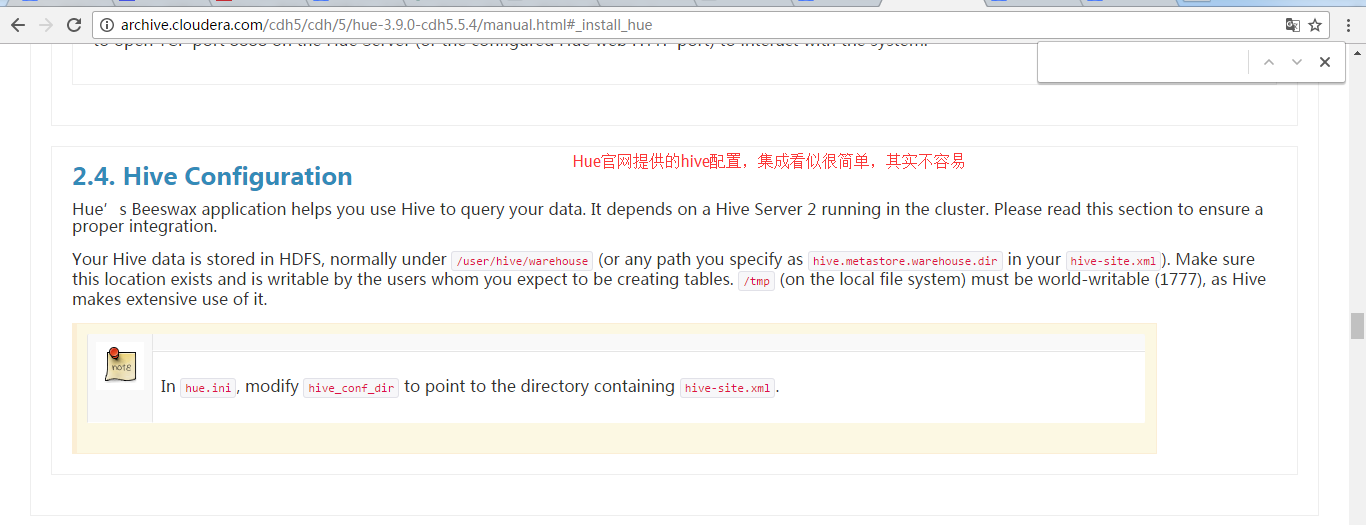
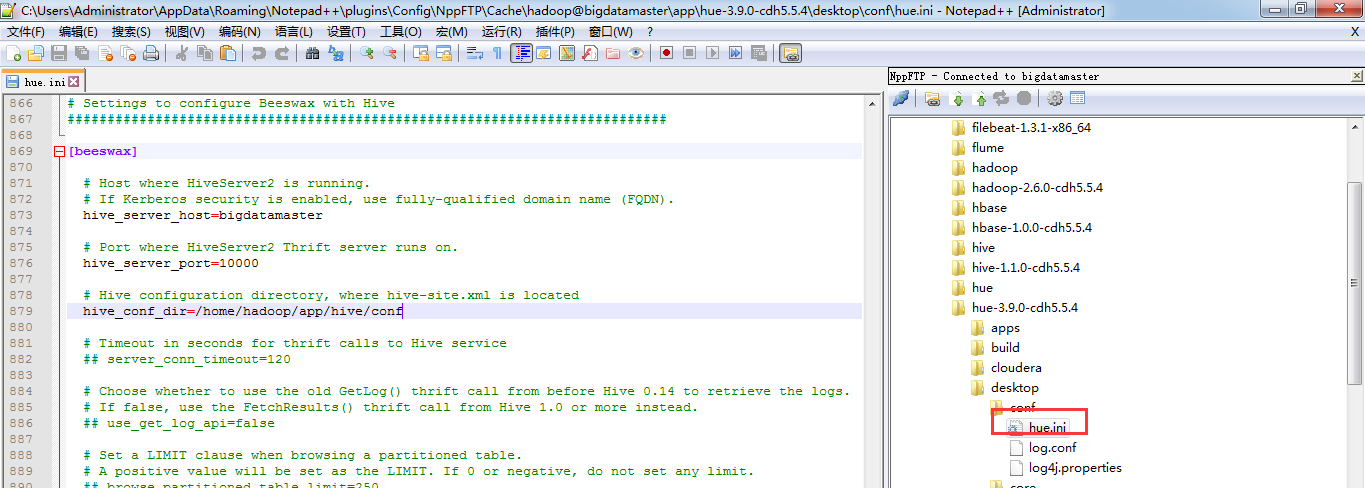
二、以下是跟我机器集群匹配的配置文件(非HA集群下怎么配置Hue的hive和beeswax模块)(本地mysql模式)
三、以下是跟我机器集群匹配的配置文件(非HA集群下怎么配置Hue的hive和beeswax模块)(本地mysql模式)
都是如下哈。因为hive说白了,是可以安装在集群之外,它就是一个客户端。
其实啊,目前Hue里的beeswax 和 hive模块是一起的。为什么叫[beeswax]而不是[hive]这是历史原因!!!

同时,是还要将hive-default.xml.template里的hive.server2.thrift.port默认属性 和 hive.server2.thrift.bind.host默认属性,
拷贝到hive-site.xml里进行修改。
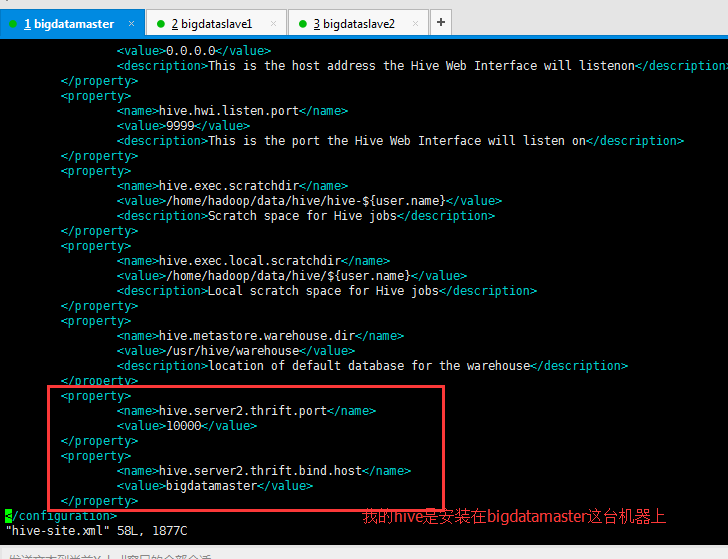
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>bigdatamaster</value>
</property>

########################################################################### # Settings to configure Beeswax with Hive ########################################################################### [beeswax] # Host where HiveServer2 is running. # If Kerberos security is enabled, use fully-qualified domain name (FQDN). hive_server_host=bigdatamaster # Port where HiveServer2 Thrift server runs on. hive_server_port=10000 # Hive configuration directory, where hive-site.xml is located hive_conf_dir=/home/hadoop/app/hive/conf # Timeout in seconds for thrift calls to Hive service ## server_conn_timeout=120 # Choose whether to use the old GetLog() thrift call from before Hive 0.14 to retrieve the logs. # If false, use the FetchResults() thrift call from Hive 1.0 or more instead. ## use_get_log_api=false # Set a LIMIT clause when browsing a partitioned table. # A positive value will be set as the LIMIT. If 0 or negative, do not set any limit. ## browse_partitioned_table_limit=250 # The maximum number of partitions that will be included in the SELECT * LIMIT sample query for partitioned tables. ## sample_table_max_partitions=10 # A limit to the number of rows that can be downloaded from a query. # A value of -1 means there will be no limit. # A maximum of 65,000 is applied to XLS downloads. ## download_row_limit=1000000 # Hue will try to close the Hive query when the user leaves the editor page. # This will free all the query resources in HiveServer2, but also make its results inaccessible. ## close_queries=false # Thrift version to use when communicating with HiveServer2. # New column format is from version 7. ## thrift_version=7
因为,Hue底层通过HiveServer2中JDBC/ODBC方式连接HIve,进行数据分析查询,需要先启动Hive中的HiveServer2服务。
所以,启动hive(在bigdatamaster节点)
$HIVE_HOME/bin/hive --service hiveserver2
或者
$HIVE_HOME/bin/hiveserver2
得到


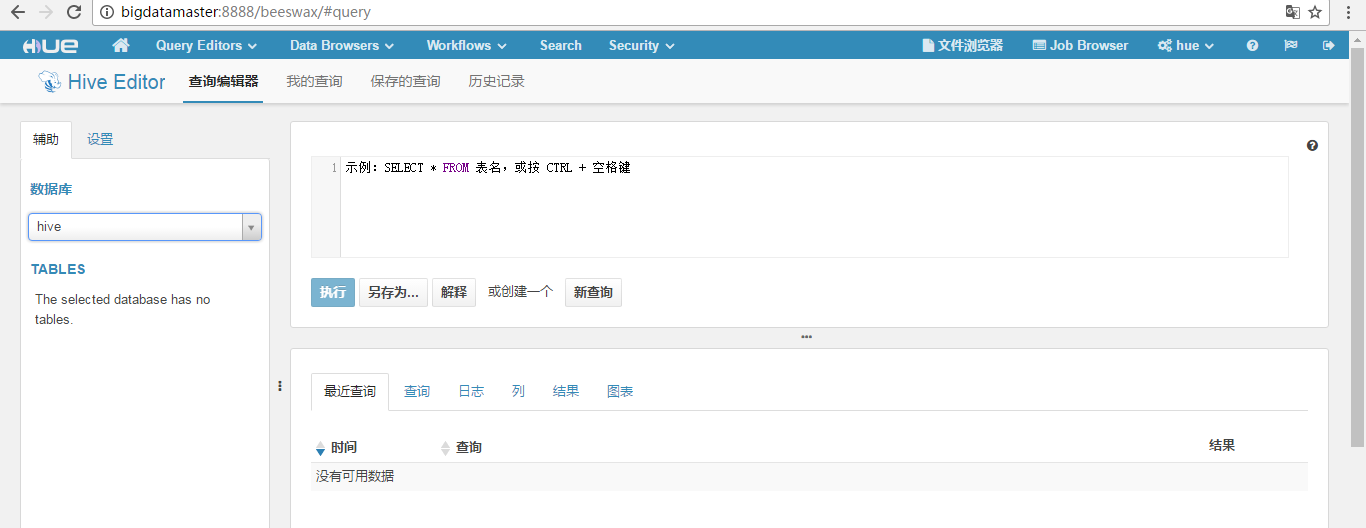
其他,不多赘述,大家自己去看自己机器!
四、以下是跟我机器集群匹配的配置文件(非HA集群下怎么配置Hue的hive和beeswax模块)(远端mysql模式)
五、以下是跟我机器集群匹配的配置文件(非HA集群下怎么配置Hue的hive和beeswax模块)(远端mysql模式)
都是如下哈。因为hive说白了,是可以安装在集群之外,它就是一个客户端。
其实啊,目前Hue里的beeswax 和 hive模块是一起的。
比如,我这里是master、slave1和slave2组成的集群,在master和slave1上搭建的是hive的Remote模式。
看hive的官方文档
http://hive.apache.org/
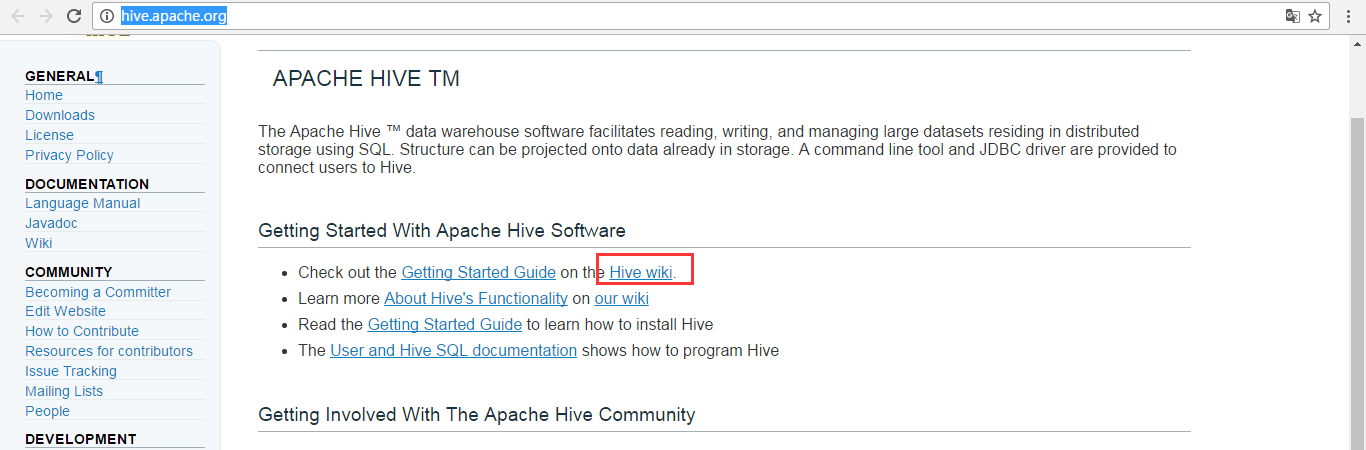
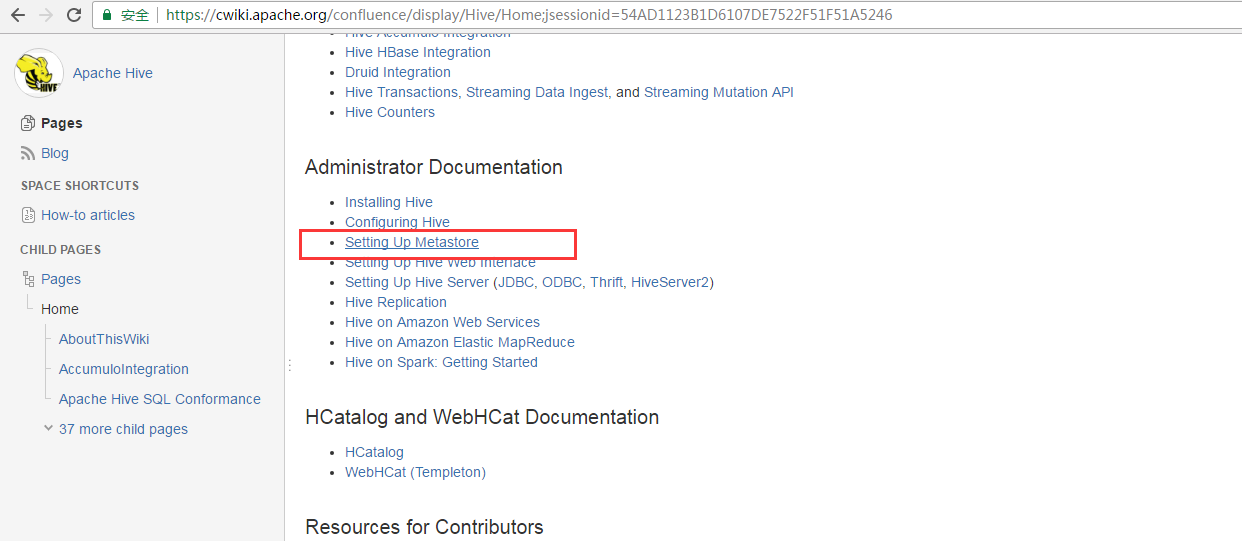
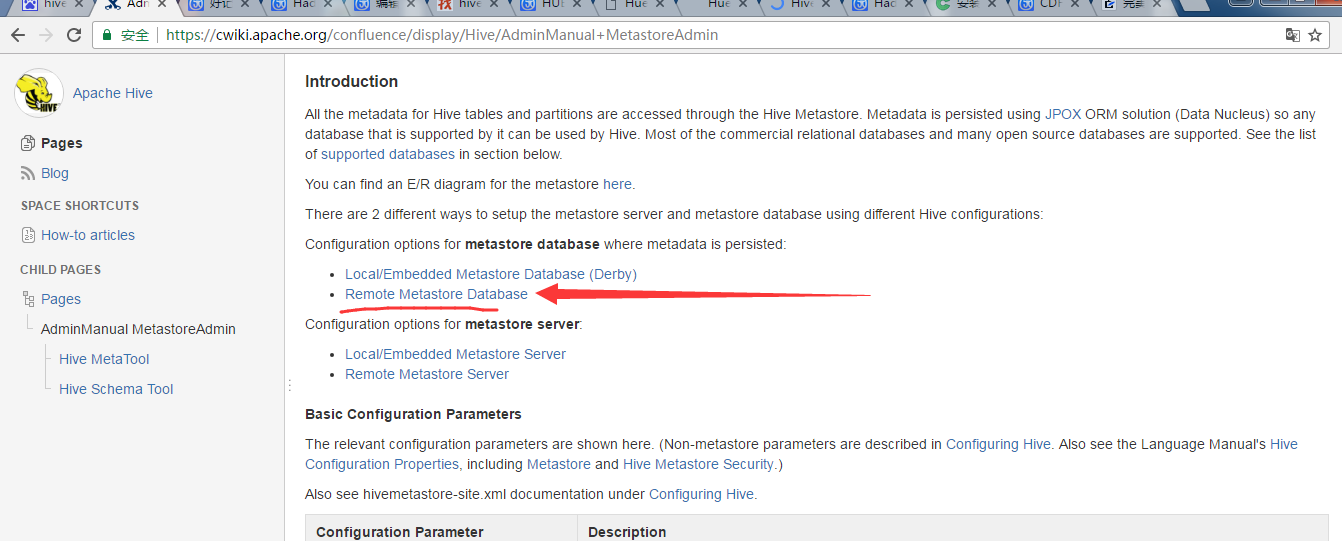
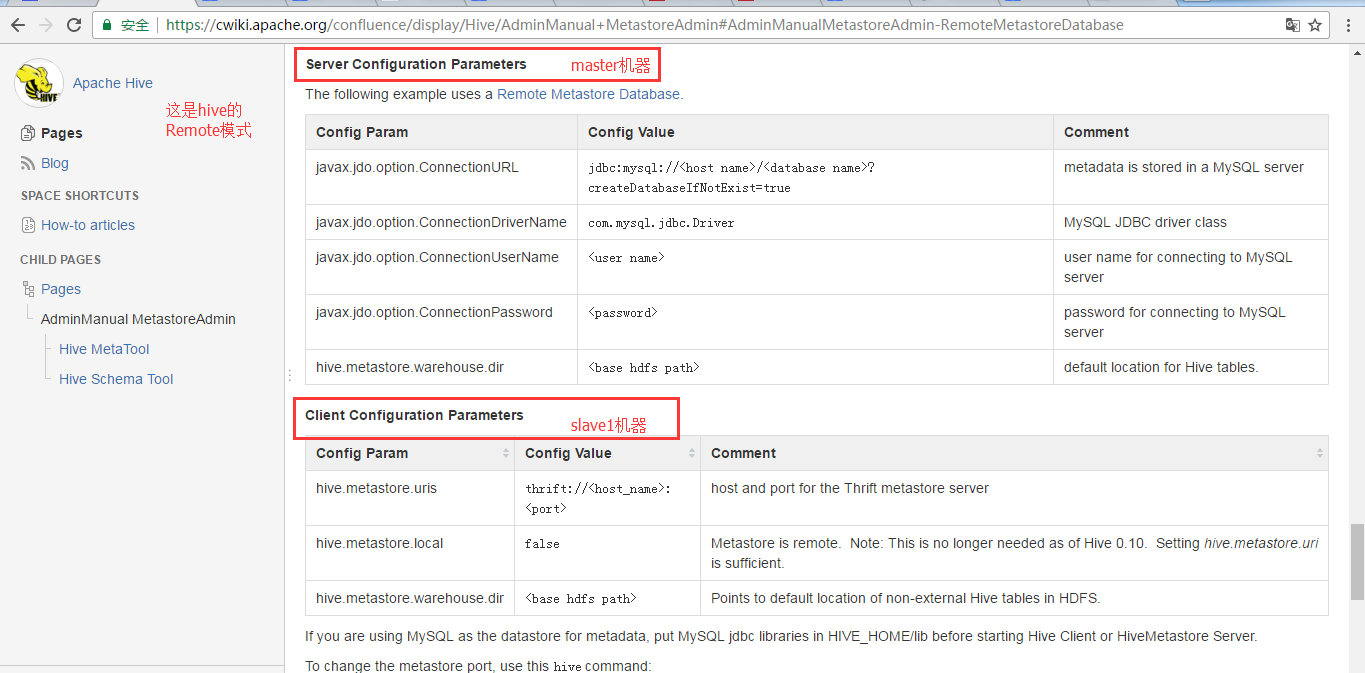
master机器上
将hive-site.xml配置文件拆为如下两部分 1)、服务端配置文件(比如在master) <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.80.10:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> </configuration>
slave1机器上
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.metastore.local</name> <value>false</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://192.168.80.11:9083</value> </property> </configuration>
注意,在客户端slave1,有个属性,hive.metastore.local为false。
在master节点上启动hive服务端程序
hive --service metastore
或者
hive --servie metastore -9083
注意啦,是还要将hive-default.xml.template里的hive.metastore.uris默认属性,
拷贝到hive-site.xml里进行修改。
hive.metastore.uris (在slave1机器上)
<property> <name>hive.metastore.uris</name> <value>thrift://192.168.80.11:9083</value> </property>
########################################################################### # Settings to configure Beeswax with Hive ########################################################################### [beeswax] # Host where HiveServer2 is running. # If Kerberos security is enabled, use fully-qualified domain name (FQDN). hive_server_host=bigdatamaster # Port where HiveServer2 Thrift server runs on. hive_server_port=10000 # Hive configuration directory, where hive-site.xml is located hive_conf_dir=/home/hadoop/app/hive/conf # Timeout in seconds for thrift calls to Hive service ## server_conn_timeout=120 # Choose whether to use the old GetLog() thrift call from before Hive 0.14 to retrieve the logs. # If false, use the FetchResults() thrift call from Hive 1.0 or more instead. ## use_get_log_api=false # Set a LIMIT clause when browsing a partitioned table. # A positive value will be set as the LIMIT. If 0 or negative, do not set any limit. ## browse_partitioned_table_limit=250 # The maximum number of partitions that will be included in the SELECT * LIMIT sample query for partitioned tables. ## sample_table_max_partitions=10 # A limit to the number of rows that can be downloaded from a query. # A value of -1 means there will be no limit. # A maximum of 65,000 is applied to XLS downloads. ## download_row_limit=1000000 # Hue will try to close the Hive query when the user leaves the editor page. # This will free all the query resources in HiveServer2, but also make its results inaccessible. ## close_queries=false # Thrift version to use when communicating with HiveServer2. # New column format is from version 7. ## thrift_version=7
最后的界面
以下是跟我机器集群匹配的配置文件(HA集群下怎么配置Hue的hive和beeswax模块)(本地和远端mysql模式)
如下:
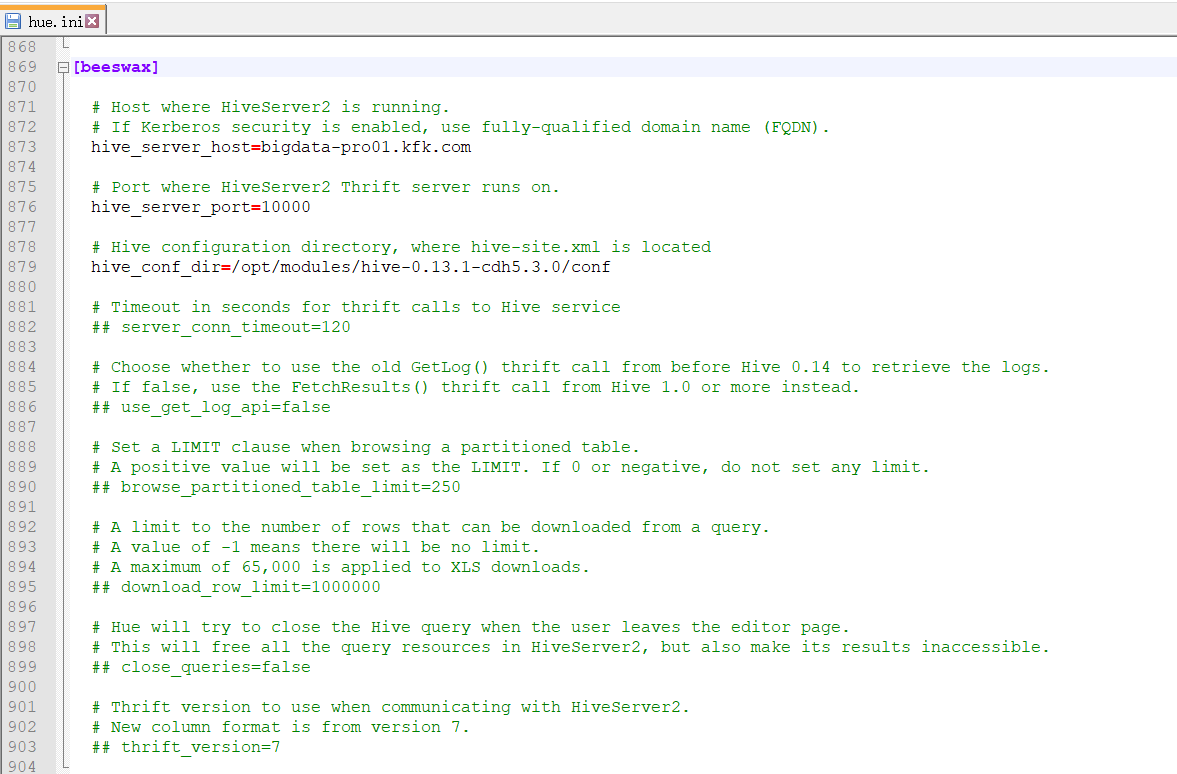
[beeswax] # Host where HiveServer2 is running. # If Kerberos security is enabled, use fully-qualified domain name (FQDN). hive_server_host=bigdata-pro01.kfk.com # Port where HiveServer2 Thrift server runs on. hive_server_port=10000 # Hive configuration directory, where hive-site.xml is located hive_conf_dir=/opt/modules/hive-0.13.1-cdh5.3.0/conf # Timeout in seconds for thrift calls to Hive service ## server_conn_timeout=120 # Choose whether to use the old GetLog() thrift call from before Hive 0.14 to retrieve the logs. # If false, use the FetchResults() thrift call from Hive 1.0 or more instead. ## use_get_log_api=false # Set a LIMIT clause when browsing a partitioned table. # A positive value will be set as the LIMIT. If 0 or negative, do not set any limit. ## browse_partitioned_table_limit=250 # A limit to the number of rows that can be downloaded from a query. # A value of -1 means there will be no limit. # A maximum of 65,000 is applied to XLS downloads. ## download_row_limit=1000000 # Hue will try to close the Hive query when the user leaves the editor page. # This will free all the query resources in HiveServer2, but also make its results inaccessible. ## close_queries=false # Thrift version to use when communicating with HiveServer2. # New column format is from version 7. ## thrift_version=7
先启动hivesever2

[kfk@bigdata-pro01 hive-0.13.1-cdh5.3.0]$ pwd /opt/modules/hive-0.13.1-cdh5.3.0 [kfk@bigdata-pro01 hive-0.13.1-cdh5.3.0]$ bin/hiveserver2 Starting HiveServer2 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/modules/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/modules/hbase-0.98.6-cdh5.3.0/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
停掉hue,再启动hue
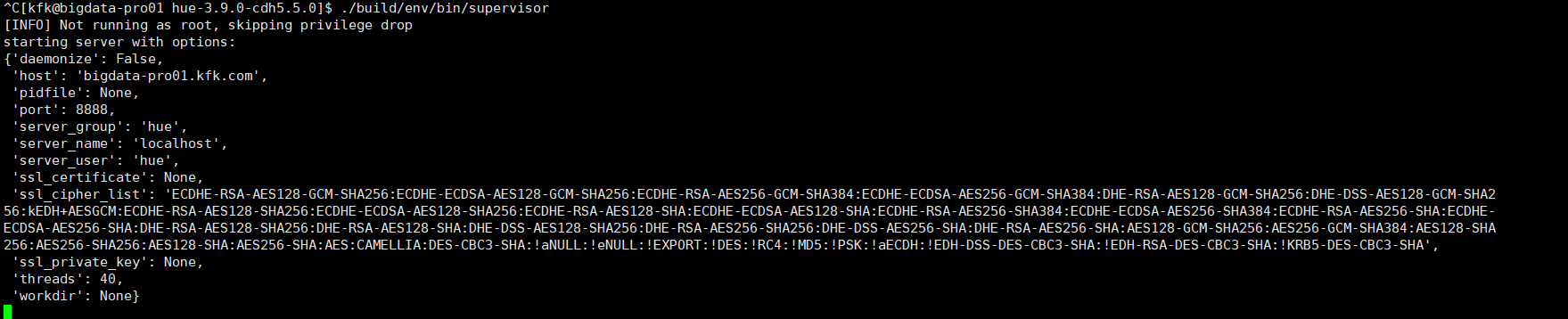
^C[kfk@bigdata-pro01 hue-3.9.0-cdh5.5.0]$ ./build/env/bin/supervisor [INFO] Not running as root, skipping privilege drop starting server with options: {'daemonize': False, 'host': 'bigdata-pro01.kfk.com', 'pidfile': None, 'port': 8888, 'server_group': 'hue', 'server_name': 'localhost', 'server_user': 'hue', 'ssl_certificate': None, 'ssl_cipher_list': 'ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA', 'ssl_private_key': None, 'threads': 40, 'workdir': None}
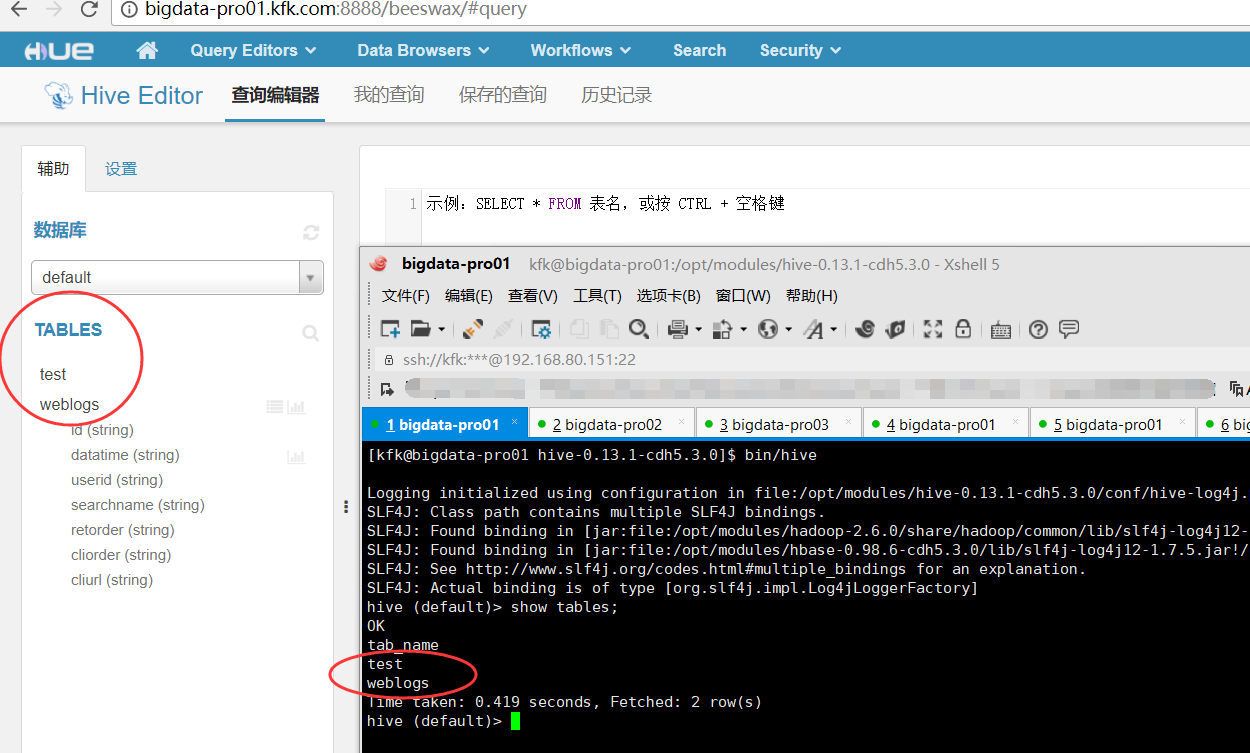
成功!
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()


