Bellman-Ford
Bellman-Ford算法,是单源最短路算法的一种。
与之前的 Dijkstra算法 最大的不同是:Dijkstra算法无法判断含负权边的图的最短路,而Bellman-Ford算法可以处理 存在负权边 的最短路径。
由于Bellman-Ford算法简单地对所有边进行松弛操作,共|V|-1次。所以这个算法的时间效率较低,也正是它的不足之处。
Bellman-Ford的时间复杂度: O(V*E) (V,E分别是点数 与 边数)
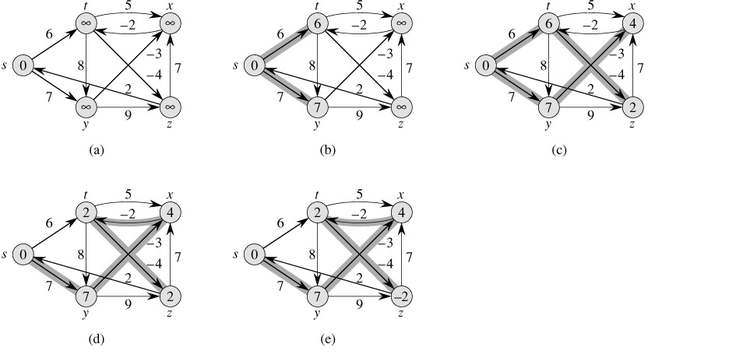
图解样例(来源《算法导论》):
伪代码:
INIT(G,s);
for i=1 to |G.V|-1
for each edge(u,v)∈G.E
RELAX(u,v,w)
for each edge(u,v)∈G.E
if v.d>u.d+w(u,v)
return FLASE
return TRUE
代码如下(邻接矩阵):
#include <bits/stdc++.h>
#define INF 0x3f3f3f3f
#define MAXN 1010
int n,m,ori;
//点,边,起点
struct Edge{ int from,to,cost; }edge[MAXN];
//邻接矩阵
int dis[MAXN];
bool Bellman_Ford()
{
for(int i=1;i<=n;++i) dis[i]=(i==ori ? 0 : INF); //初始化
for(int i=1;i<=n-1;++i) //n-1
for(int j=1;j<=m;++j)
{
int u=edge[j].from,v=edge[j].to;
if(dis[v]>dis[u]+edge[j].cost)
dis[v]=dis[u]+edge[j].cost;
}
bool flag=1; //判断是否含有负环
//原理:负权环可以无限制的降低总权值,所以如果发现第 n次操作仍可降低总权值,就一定存在负权环。
for(int i=1;i<=m;++i)
{
int u=edge[i].from,v=edge[i].to;
if(dis[v]>dis[u] + edge[i].cost)
{flag = 0;break;}
}
return flag;
}
int main()
{
std::scanf("%d%d%d",&n,&m,&ori);
for(int i=1;i<=m;++i)
std::scanf("%d%d%d",&edge[i].from,&edge[i].to,&edge[i].cost);
if(Bellman_Ford()) //先判断是否有负环 //这里也可以再加一句判断是否连通,依题而定
std::printf("%d", dis[n]);
else
std::printf("have negative circle
");
return 0;
}
SPFA(Shortest Path Faster Algorithm):
Dijkstra有队列优化,Bellman-Ford也有。SPFA是Bellman-Ford的队列优化,减少了不必要的冗余计算。
算法流程:用一个队列来进行维护。初始时将源加入队列。每次从队列中取出一个元素,并对所有与他相邻的点进行松弛,若某个相邻的点松弛成功,则将其入队。直到队列为空时算法结束。
代码如下(邻接表):
#include <bits/stdc++.h>
#define INF 0x3f3f3f3f
#define MAXN 1010
int n,m,ori;
//点,边,起点
struct EDGE{int to,val,nxt;}e[MAXN];
//邻接表
int adj[MAXN],dis[MAXN],cnt=0,num[MAXN];//计数器
bool vis[MAXN]={0};
//判断是否在队列
std::queue < int > q;
void addedge(int u,int v,int w) //链式前向星
{
e[++cnt].val=w; e[cnt].to=v; e[cnt].nxt=adj[u]; adj[u]=cnt;
}
bool SPFA(int ori)
{
for(int i=1;i<=n;++i) dis[i]=(i==ori ? 0 : INF);
q.push(ori); vis[ori]=1; ++num[ori];//起点入队列时记得+1
while(!q.empty())
{
int u=q.front(); q.pop(); vis[u]=0;
for(int i=adj[u];i;i=e[i].nxt)
{
int v=e[i].to;
if(dis[v]>dis[u]+e[i].val)
{
dis[v]=dis[u]+e[i].val;
if(!vis[v])
{
vis[v]=1;q.push(v);
++num[v];//记录加入次数
if(num[v]>n) return 0;
//如果这个点加入超过n次,说明存在负环,直接返回
}
}
}
}
return 1;
}
int main()
{
std::scanf("%d%d%d",&n,&m,&ori);
for(int i=1;i<=m;++i)
{
int u,v,w; std::scanf("%d%d%d",&u,&v,&w);
addedge(u,v,w);
}
if(SPFA(ori)); std::printf("%d", dis[n]);
return 0;
}
把负环的判断放在外面会更快一点。(但依然不能避免被卡负环)
(所以并没有什么用) 当一个习惯写吧。
bool SPFA()
{
for(int i=1;i<=n;++i)dis[i]=INF;
q.push(0); dis[0]=0; vis[0]=1; ++num[0];
while(!q.empty())
{
int u=q.front(); q.pop(); vis[u]=0;
if(num[u]>=n) return 0;
++num[u];//faster
for(int i=adj[u];i;i=e[i].nxt)
{
int v=e[i].to;
if(dis[v]>dis[u]+e[i].val)
{
dis[v]=dis[u]+e[i].val;
if(!vis[v])
{vis[v]=1; q.push(v);}
}
}
}
return 1;
}
代码风格其实和Dijkstra算法很像(代码思想类似BFS)。唯一的区别就是SPFA中需要有计算器来判断是否存在负环。
对于随机数据而言,时间复杂度:O(kE)(k为一个较小系数)
但SPFA可以人为的造数据,卡负环,导致其性能变得非常低。(时间复杂度达到指数级)
所以,如果题目中不存在负权边,用Dijkstra算法最为保险。
SPFA_DFS
SPFA_DFS,用DFS来优化SPFA。就不怕卡负环啦
算法思路:当DFS的过程中第二次搜到某一节点。
就说明这个图中存在一个环。
优缺点:代码简单效率高;但因为递归,空间会大。
代码如下:
void SPFA(int u)
{
if(flag) return;
vis[u]=1;
for(int i=adj[u];i;i=e[i].nxt)
{
int v=e[i].to;
if(dis[v]>dis[u]+e[i].val)
{
dis[v]=dis[u]+e[i].val;
if(vis[v]){flag=1;break;}
else SPFA(v);
}
}
vis[u]=0;
}
做题感悟:
- 可以运用在最长路中。(将一开始所有边的权值都改为负数,这样就所求出来的就是最长路)
- SPFA,Bellman-Ford都可以用来判断图中是否存在负环,属于判断负环的模板。
- 可以用来实现 差分约束算法