常用三种模块化规范
ES6 Module
import命令用于输入其他模块提供的功能;export命令用于规定模块的对外接口。
在 ES6 之前,社区制定了一些模块加载方案,最主要的有 CommonJS 和 AMD 两种。前者用于服务器,后者用于浏览器。ES6 在语言标准的层面上,实现了模块功能,而且实现得相当简单,完全可以取代 CommonJS 和 AMD 规范,成为浏览器和服务器通用的模块解决方案。
ES6 模块的设计思想是尽量的静态化,使得编译时就能确定模块的依赖关系,以及输入和输出的变量。CommonJS 和 AMD 模块,都只能在运行时确定这些东西。比如,CommonJS 模块就是对象,输入时必须查找对象属性。
// CommonJS模块
let { stat, exists, readFile } = require('fs');
// 等同于
let _fs = require('fs');
let stat = _fs.stat;
let exists = _fs.exists;
let readfile = _fs.readfile;
上面代码的实质是整体加载fs模块(即加载fs的所有方法),生成一个对象(_fs),然后再从这个对象上面读取 3 个方法。这种加载称为“运行时加载”,因为只有运行时才能得到这个对象,导致完全没办法在编译时做“静态优化”。
ES6 模块不是对象,而是通过export命令显式指定输出的代码,再通过import命令输入。
// ES6模块
import { stat, exists, readFile } from 'fs';
上面代码的实质是从fs模块加载 3 个方法,其他方法不加载。这种加载称为“编译时加载”或者静态加载,即 ES6 可以在编译时就完成模块加载,效率要比 CommonJS 模块的加载方式高。当然,这也导致了没法引用 ES6 模块本身,因为它不是对象。
由于 ES6 模块是编译时加载,使得静态分析成为可能。有了它,就能进一步拓宽 JavaScript 的语法,比如引入宏(macro)和类型检验(type system)这些只能靠静态分析实现的功能。
除了静态加载带来的各种好处,ES6 模块还有以下好处。
- 不再需要
UMD模块格式了,将来服务器和浏览器都会支持 ES6 模块格式。目前,通过各种工具库,其实已经做到了这一点。 - 将来浏览器的新 API 就能用模块格式提供,不再必须做成全局变量或者
navigator对象的属性。 - 不再需要对象作为命名空间(比如
Math对象),未来这些功能可以通过模块提供。
import 与 export
// 导出 a.js
/** 写法一 **/
var name = 'sheep'
function getSheep() {
name = 'hourse'
}
export {getSheep}
// 引入 b.js
import {getSheep} from './a.js'
/** 写法二 **/
var name = 'sheep'
export function getSheep() {
name = 'hourse'
}
// 引入 b.js
import {getSheep} from './a.js'
import 与 export defalut
export 可以有多个,export default 仅有一个
// 导出 a.js
let obj = {
name: 'hello',
getName: function (){
return this.name
}
export default obj
// 引入 b.js
import obj from './a.js'Commonjs
CommonJS是同步加载(常用于服务端 如node)。
require 在 ES6(bable将import转化为require) 和 CommonJS 中都支持
// 导出 a.js
let obj = {
name: 'hello',
getName: function (){
return this.name
}
module.exports = obj
// 引入 b.js
let obj = require('./a.js')
module.exports = ... : '只能输出一个,且后面的会覆盖上面的' ,
exports. ... : ' 可以输出多个',
AMD
AMD是异步加载(常用于浏览器)
require.config()指定引用路径等,用define()定义模块,用require()加载模块。// 定义math.js模块 define(function () { var basicNum = 0; var add = function (x, y) { return x + y; }; return { add: add, basicNum :basicNum }; }); // 定义一个依赖underscore.js的模块 define(['underscore'],function(_){ var classify = function(list){ _.countBy(list,function(num){ return num > 30 ? 'old' : 'young'; }) }; return { classify :classify }; }) // 引用模块,将模块放在[]内 require(['jquery', 'math'],function($, math){ var sum = math.add(10,20); $("#sum").html(sum); });
ES6模块和Commonjs差异
照抄阮大神的书
- CommonJS模块输出的是一个值的复制,ES6模块输出的是值的引用
- CommonJS模块是运行时加载,ES6模块是编译时输出接口
第二个差异是因为CommonJS加载的是一个对象,即module.export属性,该对象只有在脚本运行结束时才会生成。而ES6模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
下面重点解释第一个差异。
CommonJS模块输出的是值的复制,一旦输出这个值,模块内部的变化就影响不到这个值。
//lib.js 一个commonJS模块
var counter = 3
function incCounter() {
counter++
}
module.exports = {
counter : counter,
incCounter : incCounter,
}
//main.js 在这个函数里加载这个模块
var mod = require ('./lib')
console.log(mod.counter)
mod.incCounter()
console.log(mod.counter)
3
3
上面的代码说明,lib.js模块加载后,它的内部变化就影响不到输出的mod.counter 了。
这是因为mod.counter是一个原始类型,会被缓存。除非写成一个函数,否则得不到内部变动后的值。
//lib.js
var counter = 3
function incCounter() {
counter++
}
module.exports = {
get counter(){ //输出的counter属性实际上是个取值器函数。
return counter
},
incCounter: incCounter
}
main.js
var mod = require ('./lib')
console.log(mod.counter)
mod.incCounter()
console.log(mod.counter)//现在再执行就能正确读取内部变量counter的变动了。
3
4
ES6模块的运行机制与CommonJS不一样。JS引擎对脚本静态分析的时候,遇到模块加载命令import就会生成一个只读引用。等到脚本真正执行的时候,再根据这个只读引用到被加载的模块中取值。因此,ES6模块是动态引用,并且不会缓存值,模块里的变量绑定其所在的模块。
// lib.js
export let counter = 3
export function incCounter() {
counter++
}
//main.js
import { counter, incCounter } from './lib'
console.log(counter)
incCounter()
console.log(counter)
3
4
上面的代码说明,ES6模块输入的变量counter是活的,完全反应其所在模块lib.js内部的变化。
再如:
//m1.js
export var foo = 'bar'
setTimeout(()=>foo='baz',500)
//m2.js
import {foo} from './m1.js'
console.log(foo)
setTimeout(()=>console.log(foo),500)
bar
baz
上面的代码表明,ES6模块不会缓存运行结果,而是动态地去被加载的模块取值,并且变量总是绑定其所在的模块。
由于ES6输入的模块变量只是一个“符号连接”,所以这个变量是只读的,对它重新赋值会报错。
//lib.js
export let obj = {}
//main.js
import {obj} from './lib'
obj.prop=123 //OK
obj = {} //TypeError
main.js 从 lib.js 输入变量obj,可以对obj添加属性,但是重新赋值就会报错。因为变量obj指向的地址是只读的,不能重新赋值,这就好比main.js创造了一个名为obj的const变量。
//mod.js
function C(){
this.sum = 0
this.add = function(){
this.sum += 1
}
this.show = function(){
console.log(this.sum)
}
}
export let c = new C()
//x.js
import {c} from './mod'
c.add()
//y.js
import {c} from './mod'
c.show()
//main.js
import './x'
import './y'
1
这就证明了x.js和y.js加载都是C的同一实例
摘抄自:
阮一峰-ES6标准入门-第六章-Module的加载实现
一、模块化的理解
1.什么是模块?
- 将一个复杂的程序依据一定的规则(规范)封装成几个块(文件), 并进行组合在一起
- 块的内部数据与实现是私有的, 只是向外部暴露一些接口(方法)与外部其它模块通信
特定功能作用的集合,内部数据和方法私有,外部可通过接口访问
2.模块化的进化过程
- 1.全局function模式 : 将不同的功能封装成不同的全局函数
- 编码: 将不同的功能封装成不同的全局函数
- 问题: 污染全局命名空间, 容易引起命名冲突或数据不安全,而且模块成员之间看不出直接关系
function m1(){
//...
}
function m2(){
//...
}
- 2.namespace模式 : 简单对象封装
- 作用: 减少了全局变量,解决命名冲突
- 问题: 数据不安全(外部可以直接修改模块内部的数据)
let myModule = {
data: 'www.baidu.com',
foo() {
console.log(`foo() ${this.data}`)
},
bar() {
console.log(`bar() ${this.data}`)
}
}
myModule.data = 'other data' //能直接修改模块内部的数据
myModule.foo() // foo() other data
这样的写法会暴露所有模块成员,内部状态可以被外部改写。
- 3.IIFE模式:匿名函数自调用(闭包)
- 作用: 数据是私有的, 外部只能通过暴露的方法操作
- 编码: 将数据和行为封装到一个函数内部, 通过给window添加属性来向外暴露接口
- 问题: 如果当前这个模块依赖另一个模块怎么办?
// index.html文件 <script type="text/javascript" src="module.js"></script> <script type="text/javascript"> myModule.foo() myModule.bar() console.log(myModule.data) //undefined 不能访问模块内部数据 myModule.data = 'xxxx' //不是修改的模块内部的data myModule.foo() //没有改变</script>
// module.js文件
(function(window) {
let data = 'www.baidu.com'
//操作数据的函数
function foo() {
//用于暴露有函数
console.log(`foo() ${data}`)
}
function bar() {
//用于暴露有函数
console.log(`bar() ${data}`)
otherFun() //内部调用
}
function otherFun() {
//内部私有的函数
console.log('otherFun()')
}
//暴露行为
window.myModule = { foo, bar } //ES6写法
//完整写法 window,myModule={foo:foo,bar:bar}
})(window)
最后得到的结果:
- IIFE模式增强 : 引入依赖
这就是现代模块实现的基石
// module.js文件
(function(window, $) {
let data = 'www.baidu.com'
//操作数据的函数
function foo() {
//用于暴露有函数
console.log(`foo() ${data}`)
$('body').css('background', 'red')
}
function bar() {
//用于暴露有函数
console.log(`bar() ${data}`)
otherFun() //内部调用
}
function otherFun() {
//内部私有的函数
console.log('otherFun()')
}
//暴露行为
window.myModule = { foo, bar }
})(window, jQuery)
// index.html文件
<!-- 引入的js必须有一定顺序 -->
<script type="text/javascript" src="jquery-1.10.1.js"></script>
<script type="text/javascript" src="module.js"></script>
<script type="text/javascript">
myModule.foo()
</script>
上例子通过jquery方法将页面的背景颜色改成红色,所以必须先引入jQuery库,就把这个库当作参数传入。这样做除了保证模块的独立性,还使得模块之间的依赖关系变得明显。
3. 模块化的好处
- 避免命名冲突(减少命名空间污染)
- 更好的分离, 按需加载
- 更高复用性
- 高可维护性
4. 引入多个<script>后出现出现问题
- 请求过多
首先我们要依赖多个模块,那样就会发送多个请求,导致请求过多
- 依赖模糊
我们不知道他们的具体依赖关系是什么,也就是说很容易因为不了解他们之间的依赖关系导致加载先后顺序出错。
- 难以维护
以上两种原因就导致了很难维护,很可能出现牵一发而动全身的情况导致项目出现严重的问题。
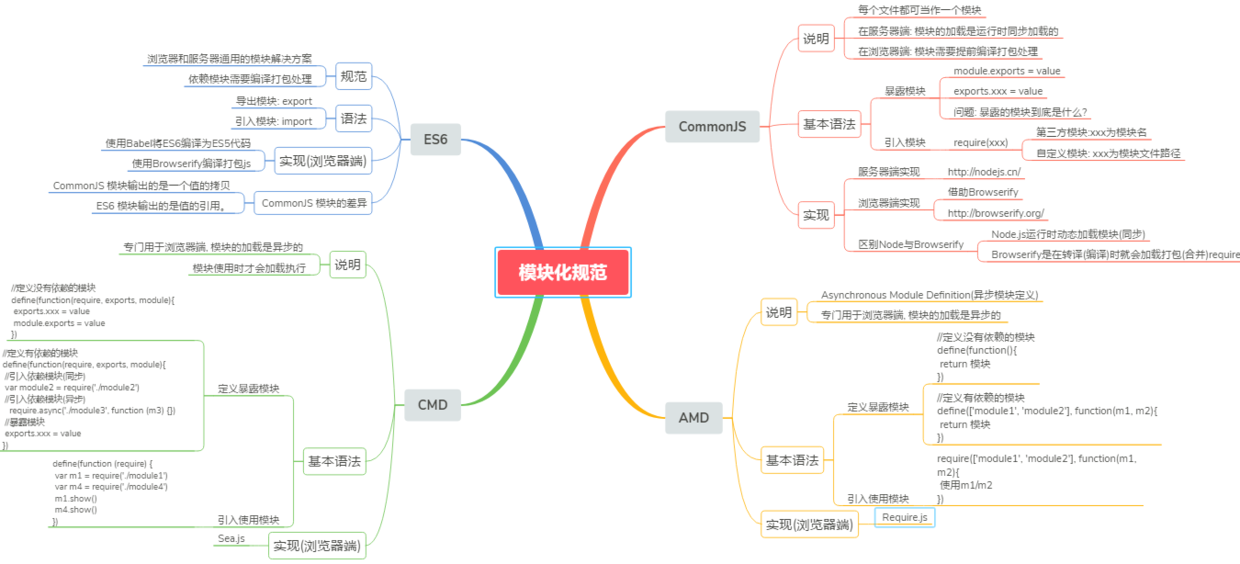
模块化固然有多个好处,然而一个页面需要引入多个js文件,就会出现以上这些问题。而这些问题可以通过模块化规范来解决,下面介绍开发中最流行的commonjs, AMD, ES6, CMD规范。
二、模块化规范
1.CommonJS
目前node使用的就是CommonJs 规范
(1)概述
Node 应用由模块组成,采用 CommonJS 模块规范。每个文件就是一个模块,有自己的作用域。在一个文件里面定义的变量、函数、类,都是私有的,对其他文件不可见。在服务器端,模块的加载是运行时同步加载的;在浏览器端,模块需要提前编译打包处理。
(2)特点
- 所有代码都运行在模块作用域,不会污染全局作用域。
- 模块可以多次加载,但是只会在第一次加载时运行一次,然后运行结果就被缓存了,以后再加载,就直接读取缓存结果。要想让模块再次运行,必须清除缓存。
- 模块加载的顺序,按照其在代码中出现的顺序。
(3)基本语法
- 暴露模块:
module.exports = value或exports.xxx = value - 引入模块:
require(xxx),如果是第三方模块,xxx为模块名;如果是自定义模块,xxx为模块文件路径
此处我们有个疑问:CommonJS暴露的模块到底是什么? CommonJS规范规定,每个模块内部,module变量代表当前模块。这个变量是一个对象,它的exports属性(即module.exports)是对外的接口。加载某个模块,其实是加载该模块的module.exports属性。
// example.js
var x = 5;
var addX = function (value) {
return value + x;
};
module.exports.x = x;
module.exports.addX = addX;
上面代码通过module.exports输出变量x和函数addX。
var example = require('./example.js');//如果参数字符串以“./”开头,则表示加载的是一个位于相对路径
console.log(example.x); // 5
console.log(example.addX(1)); // 6
require命令用于加载模块文件。require命令的基本功能是,读入并执行一个JavaScript文件,然后返回该模块的exports对象。如果没有发现指定模块,会报错。
(4)模块的加载机制
注意:CommonJS模块的加载机制是,输入的是被输出的值的拷贝。也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。这点与ES6模块化有重大差异(下文会介绍),请看下面这个例子:
// lib.js
var counter = 3;
function incCounter() {
counter++;
}
module.exports = {
counter: counter,
incCounter: incCounter,
};
上面代码输出内部变量counter和改写这个变量的内部方法incCounter。
// main.js
var counter = require('./lib').counter;
var incCounter = require('./lib').incCounter;
console.log(counter); // 3
incCounter();
console.log(counter); // 3
上面代码说明,counter输出以后,lib.js模块内部的变化就影响不到counter了。这是因为counter是一个原始类型的值,会被缓存。除非写成一个函数,才能得到内部变动后的值。
(5)服务器端实现
①下载安装node.js
②创建项目结构
注意:用npm init 自动生成package.json时,package name(包名)不能有中文和大写
|-modules
|-module1.js
|-module2.js
|-module3.js
|-app.js
|-package.json
{
"name": "commonJS-node",
"version": "1.0.0"
}
③下载第三方模块
npm install uniq --save // 用于数组去重
④定义模块代码
//module1.js
module.exports = {
msg: 'module1',
foo() {
console.log(this.msg)
}
}
//module2.js
module.exports = function() {
console.log('module2')
}
//module3.js
exports.foo = function() {
console.log('foo() module3')
}
exports.arr = [1, 2, 3, 3, 2]
// app.js文件
// 引入第三方库,应该放置在最前面
let uniq = require('uniq')
let module1 = require('./modules/module1')
let module2 = require('./modules/module2')
let module3 = require('./modules/module3')
module1.foo() //module1
module2() //module2
module3.foo() //foo() module3
console.log(uniq(module3.arr)) //[ 1, 2, 3 ]
⑤通过node运行app.js
命令行输入node app.js,运行JS文件
(6)浏览器端实现(借助Browserify)
Browserify是一个供浏览器环境使用的模块打包工具,像在node环境一样,也是通过require(‘modules‘)来组织模块之间的引用和依赖,既可以引用npm中的模块,也可以引用自己写的模块,然后打包成js文件,再在页面中通过<script>标签加载。
当然对于很多NodeJS模块,比如涉及到io操作的模块,就算通过browserify打包后肯定也无法运行在浏览器环境中,这种情况下就会用到为它们重写的支持浏览器端的分支模块,可以在browserify search搜索到这些模块。
①创建项目结构
|-js
|-dist //打包生成文件的目录
|-src //源码所在的目录
|-module1.js
|-module2.js
|-module3.js
|-app.js //应用主源文件
|-index.html //运行于浏览器上
|-package.json
{
"name": "browserify-test",
"version": "1.0.0"
}
②下载browserify
- 全局: npm install browserify -g
- 局部: npm install browserify --save-dev
③定义模块代码(同服务器端)
注意:index.html文件要运行在浏览器上,需要借助browserify将app.js文件打包编译,如果直接在index.html引入app.js就会报错!
④打包处理js
根目录下运行browserify js/src/app.js -o js/dist/bundle.js
或者browserify js/src/app.js > js/dist/bundle.js
⑤页面使用引入
在index.html文件中引入<script type="text/javascript" src="js/dist/bundle.js"></script>
2.AMD
CommonJS规范加载模块是同步的,也就是说,只有加载完成,才能执行后面的操作。AMD规范则是非同步加载模块,允许指定回调函数。由于Node.js主要用于服务器编程,模块文件一般都已经存在于本地硬盘,所以加载起来比较快,不用考虑非同步加载的方式,所以CommonJS规范比较适用。但是,如果是浏览器环境,要从服务器端加载模块,这时就必须采用非同步模式,因此浏览器端一般采用AMD规范。此外AMD规范比CommonJS规范在浏览器端实现要来着早。
(1)AMD规范基本语法
定义暴露模块:
//定义没有依赖的模块
define(function(){
return 模块
})
//定义有依赖的模块
define(['module1', 'module2'], function(m1, m2){
return 模块
})
引入使用模块:
require(['module1', 'module2'], function(m1, m2){
使用m1/m2
})
(2)未使用AMD规范与使用require.js
通过比较两者的实现方法,来说明使用AMD规范的好处。
- 未使用AMD规范
// dataService.js文件
(function (window) {
let msg = 'www.baidu.com'
function getMsg() {
return msg.toUpperCase()
}
window.dataService = {getMsg}
})(window)
// alerter.js文件
(function (window, dataService) {
let name = 'Tom'
function showMsg() {
alert(dataService.getMsg() + ', ' + name)
}
window.alerter = {showMsg}
})(window, dataService)
// main.js文件
(function (alerter) {
alerter.showMsg()
})(alerter)
// index.html文件
<div><h1>Modular Demo 1: 未使用AMD(require.js)</h1></div>
<script type="text/javascript" src="js/modules/dataService.js"></script>
<script type="text/javascript" src="js/modules/alerter.js"></script>
<script type="text/javascript" src="js/main.js"></script>
最后得到如下结果:
这种方式缺点很明显:首先会发送多个请求,其次引入的js文件顺序不能搞错,否则会报错!
- 使用require.js
RequireJS是一个工具库,主要用于客户端的模块管理。它的模块管理遵守AMD规范,RequireJS的基本思想是,通过define方法,将代码定义为模块;通过require方法,实现代码的模块加载。
接下来介绍AMD规范在浏览器实现的步骤:
①下载require.js, 并引入
- 官网:
http://www.requirejs.cn/ - github :
https://github.com/requirejs/requirejs
然后将require.js导入项目: js/libs/require.js
②创建项目结构
|-js
|-libs
|-require.js
|-modules
|-alerter.js
|-dataService.js
|-main.js
|-index.html
③定义require.js的模块代码
// dataService.js文件
// 定义没有依赖的模块
define(function() {
let msg = 'www.baidu.com'
function getMsg() {
return msg.toUpperCase()
}
return { getMsg } // 暴露模块
})
//alerter.js文件
// 定义有依赖的模块
define(['dataService'], function(dataService) {
let name = 'Tom'
function showMsg() {
alert(dataService.getMsg() + ', ' + name)
}
// 暴露模块
return { showMsg }
})
// main.js文件
(function() {
require.config({
baseUrl: 'js/', //基本路径 出发点在根目录下
paths: {
//映射: 模块标识名: 路径
alerter: './modules/alerter', //此处不能写成alerter.js,会报错
dataService: './modules/dataService'
}
})
require(['alerter'], function(alerter) {
alerter.showMsg()
})
})()
// index.html文件
<!DOCTYPE html>
<html>
<head>
<title>Modular Demo</title>
</head>
<body>
<!-- 引入require.js并指定js主文件的入口 -->
<script data-main="js/main" src="js/libs/require.js"></script>
</body>
</html>
④页面引入require.js模块:
在index.html引入 <script data-main="js/main" src="js/libs/require.js"></script>
**此外在项目中如何引入第三方库?**只需在上面代码的基础稍作修改:
// alerter.js文件
define(['dataService', 'jquery'], function(dataService, $) {
let name = 'Tom'
function showMsg() {
alert(dataService.getMsg() + ', ' + name)
}
$('body').css('background', 'green')
// 暴露模块
return { showMsg }
})
// main.js文件
(function() {
require.config({
baseUrl: 'js/', //基本路径 出发点在根目录下
paths: {
//自定义模块
alerter: './modules/alerter', //此处不能写成alerter.js,会报错
dataService: './modules/dataService',
// 第三方库模块
jquery: './libs/jquery-1.10.1' //注意:写成jQuery会报错
}
})
require(['alerter'], function(alerter) {
alerter.showMsg()
})
})()
上例是在alerter.js文件中引入jQuery第三方库,main.js文件也要有相应的路径配置。
小结:通过两者的比较,可以得出AMD模块定义的方法非常清晰,不会污染全局环境,能够清楚地显示依赖关系。AMD模式可以用于浏览器环境,并且允许非同步加载模块,也可以根据需要动态加载模块。
3.CMD
CMD规范专门用于浏览器端,模块的加载是异步的,模块使用时才会加载执行。CMD规范整合了CommonJS和AMD规范的特点。在 Sea.js 中,所有 JavaScript 模块都遵循 CMD模块定义规范。
(1)CMD规范基本语法
定义暴露模块:
//定义没有依赖的模块
define(function(require, exports, module){
exports.xxx = value
module.exports = value
})
//定义有依赖的模块
define(function(require, exports, module){
//引入依赖模块(同步)
var module2 = require('./module2')
//引入依赖模块(异步)
require.async('./module3', function (m3) {
})
//暴露模块
exports.xxx = value
})
引入使用模块:
define(function (require) {
var m1 = require('./module1')
var m4 = require('./module4')
m1.show()
m4.show()
})
(2)sea.js简单使用教程
①下载sea.js, 并引入
- 官网: http://seajs.org/
- github : https://github.com/seajs/seajs
然后将sea.js导入项目: js/libs/sea.js
②创建项目结构
|-js
|-libs
|-sea.js
|-modules
|-module1.js
|-module2.js
|-module3.js
|-module4.js
|-main.js
|-index.html
③定义sea.js的模块代码
// module1.js文件
define(function (require, exports, module) {
//内部变量数据
var data = 'atguigu.com'
//内部函数
function show() {
console.log('module1 show() ' + data)
}
//向外暴露
exports.show = show
})
// module2.js文件
define(function (require, exports, module) {
module.exports = {
msg: 'I Will Back'
}
})
// module3.js文件
define(function(require, exports, module) {
const API_KEY = 'abc123'
exports.API_KEY = API_KEY
})
// module4.js文件
define(function (require, exports, module) {
//引入依赖模块(同步)
var module2 = require('./module2')
function show() {
console.log('module4 show() ' + module2.msg)
}
exports.show = show
//引入依赖模块(异步)
require.async('./module3', function (m3) {
console.log('异步引入依赖模块3 ' + m3.API_KEY)
})
})
// main.js文件
define(function (require) {
var m1 = require('./module1')
var m4 = require('./module4')
m1.show()
m4.show()
})
④在index.html中引入
<script type="text/javascript" src="js/libs/sea.js"></script>
<script type="text/javascript">
seajs.use('./js/modules/main')
</script>
最后得到结果如下:
4.ES6模块化
ES6 模块的设计思想是尽量的静态化,使得编译时就能确定模块的依赖关系,以及输入和输出的变量。CommonJS 和 AMD 模块,都只能在运行时确定这些东西。比如,CommonJS 模块就是对象,输入时必须查找对象属性。
(1)ES6模块化语法
export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功能。
/** 定义模块 math.js **/
var basicNum = 0;
var add = function (a, b) {
return a + b;
};
export { basicNum, add };
/** 引用模块 **/
import { basicNum, add } from './math';
function test(ele) {
ele.textContent = add(99 + basicNum);
}
如上例所示,使用import命令的时候,用户需要知道所要加载的变量名或函数名,否则无法加载。为了给用户提供方便,让他们不用阅读文档就能加载模块,就要用到export default命令,为模块指定默认输出。
// export-default.js
export default function () {
console.log('foo');
}
// import-default.js
import customName from './export-default';
customName(); // 'foo'
模块默认输出, 其他模块加载该模块时,import命令可以为该匿名函数指定任意名字。
(2)ES6 模块与 CommonJS 模块的差异
它们有两个重大差异:
① CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
② CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
第二个差异是因为 CommonJS 加载的是一个对象(即module.exports属性),该对象只有在脚本运行完才会生成。而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
下面重点解释第一个差异,我们还是举上面那个CommonJS模块的加载机制例子:
// lib.js
export let counter = 3;
export function incCounter() {
counter++;
}
// main.js
import { counter, incCounter } from './lib';
console.log(counter); // 3
incCounter();
console.log(counter); // 4
ES6 模块的运行机制与 CommonJS 不一样。ES6 模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。
(3) ES6-Babel-Browserify使用教程
简单来说就一句话:使用Babel将ES6编译为ES5代码,使用Browserify编译打包js。
①定义package.json文件
{
"name" : "es6-babel-browserify",
"version" : "1.0.0"
}
②安装babel-cli, babel-preset-es2015和browserify
- npm install babel-cli browserify -g
- npm install babel-preset-es2015 --save-dev
- preset 预设(将es6转换成es5的所有插件打包)
③定义.babelrc文件
{
"presets": ["es2015"]
}
④定义模块代码
//module1.js文件
// 分别暴露
export function foo() {
console.log('foo() module1')
}
export function bar() {
console.log('bar() module1')
}
//module2.js文件
// 统一暴露
function fun1() {
console.log('fun1() module2')
}
function fun2() {
console.log('fun2() module2')
}
export { fun1, fun2 }
//module3.js文件
// 默认暴露 可以暴露任意数据类项,暴露什么数据,接收到就是什么数据
export default () => {
console.log('默认暴露')
}
// app.js文件
import { foo, bar } from './module1'
import { fun1, fun2 } from './module2'
import module3 from './module3'
foo()
bar()
fun1()
fun2()
module3()
⑤ 编译并在index.html中引入
- 使用Babel将ES6编译为ES5代码(但包含CommonJS语法) :
babel js/src -d js/lib - 使用Browserify编译js :
browserify js/lib/app.js -o js/lib/bundle.js
然后在index.html文件中引入
<script type="text/javascript" src="js/lib/bundle.js"></script>
最后得到如下结果:
此外第三方库(以jQuery为例)如何引入呢?
首先安装依赖npm install jquery@1
然后在app.js文件中引入
//app.js文件
import { foo, bar } from './module1'
import { fun1, fun2 } from './module2'
import module3 from './module3'
import $ from 'jquery'
foo()
bar()
fun1()
fun2()
module3()
$('body').css('background', 'green')
三、总结
- CommonJS规范主要用于服务端编程,加载模块是同步的,这并不适合在浏览器环境,因为同步意味着阻塞加载,浏览器资源是异步加载的,因此有了AMD CMD解决方案。
- AMD规范在浏览器环境中异步加载模块,而且可以并行加载多个模块。不过,AMD规范开发成本高,代码的阅读和书写比较困难,模块定义方式的语义不顺畅。
- CMD规范与AMD规范很相似,都用于浏览器编程,依赖就近,延迟执行,可以很容易在Node.js中运行。不过,依赖SPM 打包,模块的加载逻辑偏重
- ES6 在语言标准的层面上,实现了模块功能,而且实现得相当简单,完全可以取代 CommonJS 和 AMD 规范,成为浏览器和服务器通用的模块解决方案。
工作原理概括
基本概念
在了解 Webpack 原理前,需要掌握以下几个核心概念,以方便后面的理解:
Entry:入口,Webpack 执行构建的第一步将从 Entry 开始,可抽象成输入。Module:模块,在 Webpack 里一切皆模块,一个模块对应着一个文件。Webpack 会从配置的 Entry 开始递归找出所有依赖的模块。Chunk:代码块,一个 Chunk 由多个模块组合而成,用于代码合并与分割。Loader:模块转换器,用于把模块原内容按照需求转换成新内容。Plugin:扩展插件,在 Webpack 构建流程中的特定时机会广播出对应的事件,插件可以监听这些事件的发生,在特定时机做对应的事情。
流程概括
Webpack 的运行流程是一个串行的过程,从启动到结束会依次执行以下流程:
- 初始化参数:从配置文件和 Shell 语句中读取与合并参数,得出最终的参数;
- 开始编译:用上一步得到的参数初始化 Compiler 对象,加载所有配置的插件,执行对象的 run 方法开始执行编译;
- 确定入口:根据配置中的 entry 找出所有的入口文件;
- 编译模块:从入口文件出发,调用所有配置的 Loader 对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理;
- 完成模块编译:在经过第4步使用 Loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系;
- 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk,再把每个 Chunk 转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会;
- 输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。
在以上过程中,Webpack 会在特定的时间点广播出特定的事件,插件在监听到感兴趣的事件后会执行特定的逻辑,并且插件可以调用 Webpack 提供的 API 改变 Webpack 的运行结果。
流程细节
Webpack 的构建流程可以分为以下三大阶段:
- 初始化:启动构建,读取与合并配置参数,加载 Plugin,实例化 Compiler。
- 编译:从 Entry 发出,针对每个 Module 串行调用对应的 Loader 去翻译文件内容,再找到该 Module 依赖的 Module,递归地进行编译处理。
- 输出:对编译后的 Module 组合成 Chunk,把 Chunk 转换成文件,输出到文件系统。
如果只执行一次构建,以上阶段将会按照顺序各执行一次。但在开启监听模式下,流程将变为如下:

在每个大阶段中又会发生很多事件,Webpack 会把这些事件广播出来供给 Plugin 使用,下面来一一介绍。
初始化阶段
| 事件名 | 解释 |
|---|---|
| 初始化参数 | 从配置文件和 Shell 语句中读取与合并参数,得出最终的参数。 这个过程中还会执行配置文件中的插件实例化语句 new Plugin()。 |
实例化 Compiler |
用上一步得到的参数初始化 Compiler 实例,Compiler 负责文件监听和启动编译。Compiler 实例中包含了完整的 Webpack 配置,全局只有一个 Compiler 实例。 |
| 加载插件 | 依次调用插件的 apply 方法,让插件可以监听后续的所有事件节点。同时给插件传入 compiler 实例的引用,以方便插件通过 compiler 调用 Webpack 提供的 API。 |
environment |
开始应用 Node.js 风格的文件系统到 compiler 对象,以方便后续的文件寻找和读取。 |
entry-option |
读取配置的 Entrys,为每个 Entry 实例化一个对应的 EntryPlugin,为后面该 Entry 的递归解析工作做准备。 |
after-plugins |
调用完所有内置的和配置的插件的 apply 方法。 |
after-resolvers |
根据配置初始化完 resolver,resolver 负责在文件系统中寻找指定路径的文件。 |
| 空格 | 空格 |
| 空格 | 空格 |
| 空格 | 空格 |
编译阶段
| 事件名 | 解释 |
|---|---|
run |
启动一次新的编译。 |
watch-run |
和 run 类似,区别在于它是在监听模式下启动的编译,在这个事件中可以获取到是哪些文件发生了变化导致重新启动一次新的编译。 |
compile |
该事件是为了告诉插件一次新的编译将要启动,同时会给插件带上 compiler 对象。 |
compilation |
当 Webpack 以开发模式运行时,每当检测到文件变化,一次新的 Compilation 将被创建。一个 Compilation 对象包含了当前的模块资源、编译生成资源、变化的文件等。Compilation 对象也提供了很多事件回调供插件做扩展。 |
make |
一个新的 Compilation 创建完毕,即将从 Entry 开始读取文件,根据文件类型和配置的 Loader 对文件进行编译,编译完后再找出该文件依赖的文件,递归的编译和解析。 |
after-compile |
一次 Compilation 执行完成。 |
invalid |
当遇到文件不存在、文件编译错误等异常时会触发该事件,该事件不会导致 Webpack 退出。 |
| 空格 | 空格 |
| 空格 | 空格 |
在编译阶段中,最重要的要数 compilation 事件了,因为在 compilation 阶段调用了 Loader 完成了每个模块的转换操作,在 compilation 阶段又包括很多小的事件,它们分别是:
| 事件名 | 解释 |
|---|---|
build-module |
使用对应的 Loader 去转换一个模块。 |
normal-module-loader |
在用 Loader 对一个模块转换完后,使用 acorn 解析转换后的内容,输出对应的抽象语法树(AST),以方便 Webpack 后面对代码的分析。 |
program |
从配置的入口模块开始,分析其 AST,当遇到 require 等导入其它模块语句时,便将其加入到依赖的模块列表,同时对新找出的依赖模块递归分析,最终搞清所有模块的依赖关系。 |
seal |
所有模块及其依赖的模块都通过 Loader 转换完成后,根据依赖关系开始生成 Chunk。 |
输出阶段
| 事件名 | 解释 |
|---|---|
should-emit |
所有需要输出的文件已经生成好,询问插件哪些文件需要输出,哪些不需要。 |
emit |
确定好要输出哪些文件后,执行文件输出,可以在这里获取和修改输出内容。 |
after-emit |
文件输出完毕。 |
done |
成功完成一次完成的编译和输出流程。 |
failed |
如果在编译和输出流程中遇到异常导致 Webpack 退出时,就会直接跳转到本步骤,插件可以在本事件中获取到具体的错误原因。 |
在输出阶段已经得到了各个模块经过转换后的结果和其依赖关系,并且把相关模块组合在一起形成一个个 Chunk。 在输出阶段会根据 Chunk 的类型,使用对应的模版生成最终要要输出的文件内容。
输出文件分析
虽然在前面的章节中你学会了如何使用 Webpack ,也大致知道其工作原理,可是你想过 Webpack 输出的 bundle.js 是什么样子的吗? 为什么原来一个个的模块文件被合并成了一个单独的文件?为什么 bundle.js 能直接运行在浏览器中? 本节将解释清楚以上问题。
先来看看由 安装与使用 中最简单的项目构建出的 bundle.js 文件内容,代码如下:
<p data-height="565" data-theme-id="0" data-slug-hash="NMQzxz" data-default-tab="js" data-user="whjin" data-embed-version="2" data-pen-title="bundle.js" class="codepen">See the Pen bundle.js by whjin (@whjin) on CodePen.</p>
<script async src="https://static.codepen.io/ass...;></script>
以上看上去复杂的代码其实是一个立即执行函数,可以简写为如下:
(function(modules) {
// 模拟 require 语句
function __webpack_require__() {
}
// 执行存放所有模块数组中的第0个模块
__webpack_require__(0);
})([/*存放所有模块的数组*/])
webpack打包后生成bundle.js 能直接运行在浏览器中的原因在于输出的文件中通过 __webpack_require__ 函数定义了一个可以在浏览器中执行的加载函数来模拟 Node.js 中的 require 语句。
(因为require只在node的commonjs规范才能执行,webpack打包后是在浏览器环境下,所有需要自定义__webpack_require__方法来实现require功能)
原来一个个独立的模块文件被合并到了一个单独的 bundle.js 的原因在于浏览器不能像 Node.js 那样快速地去本地加载一个个模块文件,而必须通过网络请求去加载还未得到的文件。 如果模块数量很多,加载时间会很长,因此把所有模块都存放在了数组中,执行一次网络加载。
如果仔细分析 __webpack_require__ 函数的实现,你还有发现 Webpack 做了缓存优化: 执行加载过的模块不会再执行第二次,执行结果会缓存在内存中,当某个模块第二次被访问时会直接去内存中读取被缓存的返回值。
分割代码时的输出
例如把源码中的 main.js 修改为如下:
把require改为使用import异步加载
// 异步加载 show.js
import('./show').then((show) => {
// 执行 show 函数
show('Webpack');
});
重新构建后会输出两个文件,分别是执行入口文件 bundle.js 和 异步加载文件 0.bundle.js。
其中 0.bundle.js 内容如下:
// 加载在本文件(0.bundle.js)中包含的模块
webpackJsonp(
// 在其它文件中存放着的模块的 ID
[0],
// 本文件所包含的模块
[
// show.js 所对应的模块
(function (module, exports) {
function show(content) {
window.document.getElementById('app').innerText = 'Hello,' + content;
}
module.exports = show;
})
]
);
bundle.js 内容如下:
<p data-height="565" data-theme-id="0" data-slug-hash="yjmRyG" data-default-tab="js" data-user="whjin" data-embed-version="2" data-pen-title="bundle.js" class="codepen">See the Pen bundle.js by whjin (@whjin) on CodePen.</p>
<script async src="https://static.codepen.io/ass...;></script>
这里的 bundle.js 和上面所讲的 bundle.js 非常相似,区别在于:
- 多了一个
__webpack_require__.e用于加载被分割出去的,需要异步加载的 Chunk 对应的文件; - 多了一个
webpackJsonp函数用于从异步加载的文件中安装模块。(使用Jsonp异步加载js)
在使用了 CommonsChunkPlugin 去提取公共代码时输出的文件和使用了异步加载时输出的文件是一样的,都会有 __webpack_require__.e 和 webpackJsonp。 原因在于提取公共代码和异步加载本质上都是代码分割。
编写 Loader
Loader 就像是一个翻译员,能把源文件经过转化后输出新的结果,并且一个文件还可以链式的经过多个翻译员翻译。
以处理 SCSS 文件为例:
- SCSS 源代码会先交给
sass-loader把 SCSS 转换成 CSS; - 把
sass-loader输出的 CSS 交给css-loader处理,找出 CSS 中依赖的资源、压缩 CSS 等; - 把
css-loader输出的 CSS 交给style-loader处理,转换成通过脚本加载的 JavaScript 代码;
可以看出以上的处理过程需要有顺序的链式执行,先 sass-loader 再 css-loader 再 style-loader。 以上处理的 Webpack 相关配置如下:
<p data-height="365" data-theme-id="0" data-slug-hash="YLmbeQ" data-default-tab="js" data-user="whjin" data-embed-version="2" data-pen-title="编写 Loader" class="codepen">See the Pen 编写 Loader by whjin (@whjin) on CodePen.</p>
<script async src="https://static.codepen.io/ass...;></script>
Loader 的职责
由上面的例子可以看出:一个 Loader 的职责是单一的,只需要完成一种转换。 如果一个源文件需要经历多步转换才能正常使用,就通过多个 Loader 去转换。 在调用多个 Loader 去转换一个文件时,每个 Loader 会链式的顺序执行, 第一个 Loader 将会拿到需处理的原内容,上一个 Loader 处理后的结果会传给下一个接着处理,最后的 Loader 将处理后的最终结果返回给 Webpack。
所以,在你开发一个 Loader 时,请保持其职责的单一性,你只需关心输入和输出。
Loader 基础
由于 Webpack 是运行在 Node.js 之上的,一个 Loader 其实就是一个 Node.js 模块,这个模块需要导出一个函数。 这个导出的函数的工作就是获得处理前的原内容,对原内容执行处理后,返回处理后的内容。
一个最简单的 Loader 的源码如下:
module.exports = function(source) {
// source 为 compiler 传递给 Loader 的一个文件的原内容
// 该函数需要返回处理后的内容,这里简单起见,直接把原内容返回了,相当于该 Loader 没有做任何转换
return source;
};
由于 Loader 运行在 Node.js 中,你可以调用任何 Node.js 自带的 API,或者安装第三方模块进行调用:
const sass = require('node-sass');
module.exports = function(source) {
return sass(source);
};
Loader 进阶
以上只是个最简单的 Loader,Webpack 还提供一些 API 供 Loader 调用,下面来一一介绍。
获得 Loader 的 options
在最上面处理 SCSS 文件的 Webpack 配置中,给 css-loader 传了 options 参数,以控制 css-loader。 如何在自己编写的 Loader 中获取到用户传入的 options 呢?需要这样做:
const loaderUtils = require('loader-utils');
module.exports = function(source) {
// 获取到用户给当前 Loader 传入的 options
const options = loaderUtils.getOptions(this);
return source;
};
返回其它结果
上面的 Loader 都只是返回了原内容转换后的内容,但有些场景下还需要返回除了内容之外的东西。
例如以用 babel-loader 转换 ES6 代码为例,它还需要输出转换后的 ES5 代码对应的 Source Map,以方便调试源码。 为了把 Source Map 也一起随着 ES5 代码返回给 Webpack,可以这样写:
module.exports = function(source) {
// 通过 this.callback 告诉 Webpack 返回的结果
this.callback(null, source, sourceMaps);
// 当你使用 this.callback 返回内容时,该 Loader 必须返回 undefined,
// 以让 Webpack 知道该 Loader 返回的结果在 this.callback 中,而不是 return 中
return;
};
其中的 this.callback 是 Webpack 给 Loader 注入的 API,以方便 Loader 和 Webpack 之间通信。 this.callback 的详细使用方法如下:
this.callback(
// 当无法转换原内容时,给 Webpack 返回一个 Error
err: Error | null,
// 原内容转换后的内容
content: string | Buffer,
// 用于把转换后的内容得出原内容的 Source Map,方便调试
sourceMap?: SourceMap,
// 如果本次转换为原内容生成了 AST 语法树,可以把这个 AST 返回,
// 以方便之后需要 AST 的 Loader 复用该 AST,以避免重复生成 AST,提升性能
abstractSyntaxTree?: AST
);
Source Map 的生成很耗时,通常在开发环境下才会生成 Source Map,其它环境下不用生成,以加速构建。 为此 Webpack 为 Loader 提供了 this.sourceMap API 去告诉 Loader 当前构建环境下用户是否需要 Source Map。 如果你编写的 Loader 会生成 Source Map,请考虑到这点。
同步与异步
Loader 有同步和异步之分,上面介绍的 Loader 都是同步的 Loader,因为它们的转换流程都是同步的,转换完成后再返回结果。 但在有些场景下转换的步骤只能是异步完成的,例如你需要通过网络请求才能得出结果,如果采用同步的方式网络请求就会阻塞整个构建,导致构建非常缓慢。
在转换步骤是异步时,你可以这样:
module.exports = function(source) {
// 告诉 Webpack 本次转换是异步的,Loader 会在 callback 中回调结果
var callback = this.async();
someAsyncOperation(source, function(err, result, sourceMaps, ast) {
// 通过 callback 返回异步执行后的结果
callback(err, result, sourceMaps, ast);
});
};
处理二进制数据
在默认的情况下,Webpack 传给 Loader 的原内容都是 UTF-8 格式编码的字符串。 但有些场景下 Loader 不是处理文本文件,而是处理二进制文件,例如 file-loader,就需要 Webpack 给 Loader 传入二进制格式的数据。 为此,你需要这样编写 Loader:
module.exports = function(source) {
// 在 exports.raw === true 时,Webpack 传给 Loader 的 source 是 Buffer 类型的
source instanceof Buffer === true;
// Loader 返回的类型也可以是 Buffer 类型的
// 在 exports.raw !== true 时,Loader 也可以返回 Buffer 类型的结果
return source;
};
// 通过 exports.raw 属性告诉 Webpack 该 Loader 是否需要二进制数据
module.exports.raw = true;
以上代码中最关键的代码是最后一行 module.exports.raw = true;,没有该行 Loader 只能拿到字符串。
缓存加速
在有些情况下,有些转换操作需要大量计算非常耗时,如果每次构建都重新执行重复的转换操作,构建将会变得非常缓慢。 为此,Webpack 会默认缓存所有 Loader 的处理结果,也就是说在需要被处理的文件或者其依赖的文件没有发生变化时, 是不会重新调用对应的 Loader 去执行转换操作的。
如果你想让 Webpack 不缓存该 Loader 的处理结果,可以这样:
module.exports = function(source) {
// 关闭该 Loader 的缓存功能
this.cacheable(false);
return source;
};
其它 Loader API
除了以上提到的在 Loader 中能调用的 Webpack API 外,还存在以下常用 API:
this.context:当前处理文件的所在目录,假如当前 Loader 处理的文件是/src/main.js,则this.context就等于/src。this.resource:当前处理文件的完整请求路径,包括querystring,例如/src/main.js?name=1。this.resourcePath:当前处理文件的路径,例如/src/main.js。this.resourceQuery:当前处理文件的querystring。this.target:等于 Webpack 配置中的 Target。this.loadModule:但 Loader 在处理一个文件时,如果依赖其它文件的处理结果才能得出当前文件的结果时, 就可以通过this.loadModule(request: string, callback: function(err, source, sourceMap, module))去获得request对应文件的处理结果。this.resolve:像require语句一样获得指定文件的完整路径,使用方法为resolve(context: string, request: string, callback: function(err, result: string))。this.addDependency:给当前处理文件添加其依赖的文件,以便再其依赖的文件发生变化时,会重新调用 Loader 处理该文件。使用方法为addDependency(file: string)。this.addContextDependency:和addDependency类似,但addContextDependency是把整个目录加入到当前正在处理文件的依赖中。使用方法为addContextDependency(directory: string)。this.clearDependencies:清除当前正在处理文件的所有依赖,使用方法为clearDependencies()。this.emitFile:输出一个文件,使用方法为emitFile(name: string, content: Buffer|string, sourceMap: {...})。
加载本地 Loader
在开发 Loader 的过程中,为了测试编写的 Loader 是否能正常工作,需要把它配置到 Webpack 中后,才可能会调用该 Loader。 在前面的章节中,使用的 Loader 都是通过 Npm 安装的,要使用 Loader 时会直接使用 Loader 的名称,代码如下:
module.exports = {
module: {
rules: [
{
test: /.css/,
use: ['style-loader'],
},
]
},
};
如果还采取以上的方法去使用本地开发的 Loader 将会很麻烦,因为你需要确保编写的 Loader 的源码是在 node_modules目录下。 为此你需要先把编写的 Loader 发布到 Npm 仓库后再安装到本地项目使用。
解决以上问题的便捷方法有两种,分别如下:
Npm link
Npm link 专门用于开发和调试本地 Npm 模块,能做到在不发布模块的情况下,把本地的一个正在开发的模块的源码链接到项目的 node_modules 目录下,让项目可以直接使用本地的 Npm 模块。 由于是通过软链接的方式实现的,编辑了本地的 Npm 模块代码,在项目中也能使用到编辑后的代码。
完成 Npm link 的步骤如下:
- 确保正在开发的本地 Npm 模块(也就是正在开发的 Loader)的
package.json已经正确配置好; - 在本地 Npm 模块根目录下执行
npm link,把本地模块注册到全局; - 在项目根目录下执行
npm link loader-name,把第2步注册到全局的本地 Npm 模块链接到项目的node_moduels下,其中的loader-name是指在第1步中的package.json文件中配置的模块名称。
链接好 Loader 到项目后你就可以像使用一个真正的 Npm 模块一样使用本地的 Loader 了。
ResolveLoader
ResolveLoader 用于配置 Webpack 如何寻找 Loader。 默认情况下只会去 node_modules 目录下寻找,为了让 Webpack 加载放在本地项目中的 Loader 需要修改 resolveLoader.modules。
假如本地的 Loader 在项目目录中的 ./loaders/loader-name 中,则需要如下配置:
module.exports = {
resolveLoader:{
// 去哪些目录下寻找 Loader,有先后顺序之分
modules: ['node_modules','./loaders/'],
}
}
加上以上配置后, Webpack 会先去 node_modules 项目下寻找 Loader,如果找不到,会再去 ./loaders/ 目录下寻找。
实战
上面讲了许多理论,接下来从实际出发,来编写一个解决实际问题的 Loader。
该 Loader 名叫 comment-require-loader,作用是把 JavaScript 代码中的注释语法:
// @require '../style/index.css'
转换成:
require('../style/index.css');
该 Loader 的使用场景是去正确加载针对 Fis3 编写的 JavaScript,这些 JavaScript 中存在通过注释的方式加载依赖的 CSS 文件。
该 Loader 的使用方法如下:
module.exports = {
module: {
rules: [
{
test: /.js$/,
use: ['comment-require-loader'],
// 针对采用了 fis3 CSS 导入语法的 JavaScript 文件通过 comment-require-loader 去转换
include: [path.resolve(__dirname, 'node_modules/imui')]
}
]
}
};
该 Loader 的实现非常简单,完整代码如下:
function replace(source) {
// 使用正则把 // @require '../style/index.css' 转换成 require('../style/index.css');
return source.replace(/(// *@require) +(('|").+('|")).*/, 'require($2);');
}
module.exports = function (content) {
return replace(content);
};
编写 Plugin
Webpack 通过 Plugin 机制让其更加灵活,以适应各种应用场景。 在 Webpack 运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果。
一个最基础的 Plugin 的代码是这样的:
class BasicPlugin{
// 在构造函数中获取用户给该插件传入的配置
constructor(options){
}
// Webpack 会调用 BasicPlugin 实例的 apply 方法给插件实例传入 compiler 对象
apply(compiler){
compiler.plugin('compilation',function(compilation) {
})
}
}
// 导出 Plugin
module.exports = BasicPlugin;
在使用这个 Plugin 时,相关配置代码如下:
const BasicPlugin = require('./BasicPlugin.js');
module.export = {
plugins:[
new BasicPlugin(options),
]
}
Webpack 启动后,在读取配置的过程中会先执行 new BasicPlugin(options) 初始化一个 BasicPlugin 获得其实例。 在初始化 compiler 对象后,再调用 basicPlugin.apply(compiler) 给插件实例传入 compiler 对象。 插件实例在获取到 compiler 对象后,就可以通过 compiler.plugin(事件名称, 回调函数) 监听到 Webpack 广播出来的事件。 并且可以通过 compiler 对象去操作 Webpack。
通过以上最简单的 Plugin 相信你大概明白了 Plugin 的工作原理,但实际开发中还有很多细节需要注意,下面来详细介绍。
Compiler 和 Compilation
在开发 Plugin 时最常用的两个对象就是 Compiler 和 Compilation,它们是 Plugin 和 Webpack 之间的桥梁。 Compiler 和 Compilation 的含义如下:
- Compiler 对象包含了 Webpack 环境所有的的配置信息,包含
options,loaders,plugins这些信息,这个对象在 Webpack 启动时候被实例化,它是全局唯一的,可以简单地把它理解为 Webpack 实例; - Compilation 对象包含了当前的模块资源、编译生成资源、变化的文件等。当 Webpack 以开发模式运行时,每当检测到一个文件变化,一次新的 Compilation 将被创建。Compilation 对象也提供了很多事件回调供插件做扩展。通过 Compilation 也能读取到 Compiler 对象。
Compiler 和 Compilation 的区别在于:Compiler 代表了整个 Webpack 从启动到关闭的生命周期,而 Compilation 只是代表了一次新的编译。
事件流
Webpack 就像一条生产线,要经过一系列处理流程后才能将源文件转换成输出结果。 这条生产线上的每个处理流程的职责都是单一的,多个流程之间有存在依赖关系,只有完成当前处理后才能交给下一个流程去处理。 插件就像是一个插入到生产线中的一个功能,在特定的时机对生产线上的资源做处理。
Webpack 通过 Tapable 来组织这条复杂的生产线。 Webpack 在运行过程中会广播事件,插件只需要监听它所关心的事件,就能加入到这条生产线中,去改变生产线的运作。 Webpack 的事件流机制保证了插件的有序性,使得整个系统扩展性很好。
Webpack 的事件流机制应用了观察者模式,和 Node.js 中的 EventEmitter 非常相似。Compiler 和 Compilation 都继承自 Tapable,可以直接在 Compiler 和 Compilation 对象上广播和监听事件,方法如下:
/**
* 广播出事件
* event-name 为事件名称,注意不要和现有的事件重名
* params 为附带的参数
*/
compiler.apply('event-name',params);
/**
* 监听名称为 event-name 的事件,当 event-name 事件发生时,函数就会被执行。
* 同时函数中的 params 参数为广播事件时附带的参数。
*/
compiler.plugin('event-name',function(params) {
});
同理,compilation.apply 和 compilation.plugin 使用方法和上面一致。
在开发插件时,你可能会不知道该如何下手,因为你不知道该监听哪个事件才能完成任务。
在开发插件时,还需要注意以下两点:
- 只要能拿到 Compiler 或 Compilation 对象,就能广播出新的事件,所以在新开发的插件中也能广播出事件,给其它插件监听使用。
- 传给每个插件的 Compiler 和 Compilation 对象都是同一个引用。也就是说在一个插件中修改了 Compiler 或 Compilation 对象上的属性,会影响到后面的插件。
- 有些事件是异步的,这些异步的事件会附带两个参数,第二个参数为回调函数,在插件处理完任务时需要调用回调函数通知 Webpack,才会进入下一处理流程。例如:
compiler.plugin('emit',function(compilation, callback) {
// 支持处理逻辑
// 处理完毕后执行 callback 以通知 Webpack
// 如果不执行 callback,运行流程将会一直卡在这不往下执行
callback();
});常用 API
插件可以用来修改输出文件、增加输出文件、甚至可以提升 Webpack 性能、等等,总之插件通过调用 Webpack 提供的 API 能完成很多事情。 由于 Webpack 提供的 API 非常多,有很多 API 很少用的上,又加上篇幅有限,下面来介绍一些常用的 API。
读取输出资源、代码块、模块及其依赖
有些插件可能需要读取 Webpack 的处理结果,例如输出资源、代码块、模块及其依赖,以便做下一步处理。
在 emit 事件发生时,代表源文件的转换和组装已经完成,在这里可以读取到最终将输出的资源、代码块、模块及其依赖,并且可以修改输出资源的内容。 插件代码如下:
<p data-height="585" data-theme-id="0" data-slug-hash="RJwjPj" data-default-tab="js" data-user="whjin" data-embed-version="2" data-pen-title="emit" class="codepen">See the Pen emit by whjin (@whjin) on CodePen.</p>
<script async src="https://static.codepen.io/ass...;></script>
监听文件变化
Webpack 会从配置的入口模块出发,依次找出所有的依赖模块,当入口模块或者其依赖的模块发生变化时, 就会触发一次新的 Compilation。
在开发插件时经常需要知道是哪个文件发生变化导致了新的 Compilation,为此可以使用如下代码:
<p data-height="255" data-theme-id="0" data-slug-hash="jKOabJ" data-default-tab="js" data-user="whjin" data-embed-version="2" data-pen-title="Compilation" class="codepen">See the Pen Compilation by whjin (@whjin) on CodePen.</p>
<script async src="https://static.codepen.io/ass...;></script>
默认情况下 Webpack 只会监视入口和其依赖的模块是否发生变化,在有些情况下项目可能需要引入新的文件,例如引入一个 HTML 文件。 由于 JavaScript 文件不会去导入 HTML 文件,Webpack 就不会监听 HTML 文件的变化,编辑 HTML 文件时就不会重新触发新的 Compilation。 为了监听 HTML 文件的变化,我们需要把 HTML 文件加入到依赖列表中,为此可以使用如下代码:
compiler.plugin('after-compile', (compilation, callback) => {
// 把 HTML 文件添加到文件依赖列表,好让 Webpack 去监听 HTML 模块文件,在 HTML 模版文件发生变化时重新启动一次编译
compilation.fileDependencies.push(filePath);
callback();
});
修改输出资源
有些场景下插件需要修改、增加、删除输出的资源,要做到这点需要监听 emit 事件,因为发生 emit 事件时所有模块的转换和代码块对应的文件已经生成好, 需要输出的资源即将输出,因此 emit 事件是修改 Webpack 输出资源的最后时机。
所有需要输出的资源会存放在 compilation.assets 中,compilation.assets 是一个键值对,键为需要输出的文件名称,值为文件对应的内容。
设置 compilation.assets 的代码如下:
compiler.plugin('emit', (compilation, callback) => {
// 设置名称为 fileName 的输出资源
compilation.assets[fileName] = {
// 返回文件内容
source: () => {
// fileContent 既可以是代表文本文件的字符串,也可以是代表二进制文件的 Buffer
return fileContent;
},
// 返回文件大小
size: () => {
return Buffer.byteLength(fileContent, 'utf8');
}
};
callback();
});
读取 compilation.assets 的代码如下:
compiler.plugin('emit', (compilation, callback) => {
// 读取名称为 fileName 的输出资源
const asset = compilation.assets[fileName];
// 获取输出资源的内容
asset.source();
// 获取输出资源的文件大小
asset.size();
callback();
});
判断 Webpack 使用了哪些插件
在开发一个插件时可能需要根据当前配置是否使用了其它某个插件而做下一步决定,因此需要读取 Webpack 当前的插件配置情况。 以判断当前是否使用了 ExtractTextPlugin 为例,可以使用如下代码:
// 判断当前配置使用使用了 ExtractTextPlugin,
// compiler 参数即为 Webpack 在 apply(compiler) 中传入的参数
function hasExtractTextPlugin(compiler) {
// 当前配置所有使用的插件列表
const plugins = compiler.options.plugins;
// 去 plugins 中寻找有没有 ExtractTextPlugin 的实例
return plugins.find(plugin=>plugin.__proto__.constructor === ExtractTextPlugin) != null;
}
实战
下面我们举一个实际的例子,带你一步步去实现一个插件。
该插件的名称取名叫 EndWebpackPlugin,作用是在 Webpack 即将退出时再附加一些额外的操作,例如在 Webpack 成功编译和输出了文件后执行发布操作把输出的文件上传到服务器。 同时该插件还能区分 Webpack 构建是否执行成功。使用该插件时方法如下:
module.exports = {
plugins:[
// 在初始化 EndWebpackPlugin 时传入了两个参数,分别是在成功时的回调函数和失败时的回调函数;
new EndWebpackPlugin(() => {
// Webpack 构建成功,并且文件输出了后会执行到这里,在这里可以做发布文件操作
}, (err) => {
// Webpack 构建失败,err 是导致错误的原因
console.error(err);
})
]
}
要实现该插件,需要借助两个事件:
done:在成功构建并且输出了文件后,Webpack 即将退出时发生;failed:在构建出现异常导致构建失败,Webpack 即将退出时发生;
实现该插件非常简单,完整代码如下:
class EndWebpackPlugin {
constructor(doneCallback, failCallback) {
// 存下在构造函数中传入的回调函数
this.doneCallback = doneCallback;
this.failCallback = failCallback;
}
apply(compiler) {
compiler.plugin('done', (stats) => {
// 在 done 事件中回调 doneCallback
this.doneCallback(stats);
});
compiler.plugin('failed', (err) => {
// 在 failed 事件中回调 failCallback
this.failCallback(err);
});
}
}
// 导出插件
module.exports = EndWebpackPlugin;
从开发这个插件可以看出,找到合适的事件点去完成功能在开发插件时显得尤为重要。 在 工作原理概括 中详细介绍过 Webpack 在运行过程中广播出常用事件,你可以从中找到你需要的事件。
调试 Webpack
在编写 Webpack 的 Plugin 和 Loader 时,可能执行结果会和你预期的不一样,就和你平时写代码遇到了奇怪的 Bug 一样。 对于无法一眼看出问题的 Bug,通常需要调试程序源码才能找出问题所在。
虽然可以通过 console.log 的方式完成调试,但这种方法非常不方便也不优雅,本节将教你如何断点调试 工作原理概括 中的插件代码。 由于 Webpack 运行在 Node.js 之上,调试 Webpack 就相对于调试 Node.js 程序。
在 Webstorm 中调试
Webstorm 集成了 Node.js 的调试工具,因此使用 Webstorm 调试 Webpack 非常简单。
1. 设置断点
在你认为可能出现问题的地方设下断点,点击编辑区代码左侧出现红点表示设置了断点。
2. 配置执行入口
告诉 Webstorm 如何启动 Webpack,由于 Webpack 实际上就是一个 Node.js 应用,因此需要新建一个 Node.js 类型的执行入口。
以上配置中有三点需要注意:
Name设置成了debug webpack,就像设置了一个别名,方便记忆和区分;Working directory设置为需要调试的插件所在的项目的根目录;JavaScript file即 Node.js 的执行入口文件,设置为 Webpack 的执行入口文件node_modules/webpack/bin/webpack.js。
3. 启动调试
经过以上两步,准备工作已经完成,下面启动调试,启动时选中前面设置的 debug webpack。
4. 执行到断点
启动后程序就会停在断点所在的位置,在这里你可以方便的查看变量当前的状态,找出问题。
原理总结
Webpack 是一个庞大的 Node.js 应用,如果你阅读过它的源码,你会发现实现一个完整的 Webpack 需要编写非常多的代码。 但你无需了解所有的细节,只需了解其整体架构和部分细节即可。
对 Webpack 的使用者来说,它是一个简单强大的工具; 对 Webpack 的开发者来说,它是一个扩展性的高系统。
Webpack 之所以能成功,在于它把复杂的实现隐藏了起来,给用户暴露出的只是一个简单的工具,让用户能快速达成目的。 同时整体架构设计合理,扩展性高,开发扩展难度不高,通过社区补足了大量缺失的功能,让 Webpack 几乎能胜任任何场景。
通过本章的学习,希望你不仅能学会如何编写 Webpack 扩展,也能从中领悟到如何设计好的系统架构。
补充:更加具体的初始化——》编译——》输出阶段
已知,Webpack 源码是一个插件的架构,很多功能都是通过诸多的内置插件实现的。Webpack为此专门自己写一个插件系统,叫 Tapable 主要提供了注册和调用插件的功能。 一起研究之前,希望你对 tapable 有所了解~
基本架构
先通过一张大图整体梳理一下webpack的主体流程,再细节一点的稍后再介绍
- 解析
config与shell中的配置项 webpack初始化过程,首先会根据第一步的options生成compiler对象,然后初始化webpack的内置插件及options配置run代表编译的开始,会构建compilation对象,用于存储这一次编译过程的所有数据make执行真正的编译构建过程,从入口文件开始,构建模块,直到所有模块创建结束seal生成chunks,对chunks进行一系列的优化操作,并生成要输出的代码seal结束后,Compilation实例的所有工作到此也全部结束,意味着一次构建过程已经结束emit被触发之后,webpack会遍历compilation.assets, 生成所有文件,然后触发任务点done,结束构建流程
构建流程
webpack准备阶段
webpack启动入口,webpack-cli/bin/cli.js
const webpack = require("webpack");
// 使用yargs来解析命令行参数并合并配置文件中的参数(options),
// 然后调用lib/webpack.js实例化compile 并返回
let compiler;
try {
compiler = webpack(options);
} catch (err) {}
复制代码// lib/webpack.js
const webpack = (options, callback) => {
// 首先会检查配置参数是否合法
// 创建Compiler
let compiler;
compiler = new Compiler(options.context);
compiler.options = new WebpackOptionsApply().process(options, compiler);
...
if (options.watch === true || ..) {
...
return compiler.watch(watchOptions, callback);
}
compiler.run(callback);
}
复制代码创建Compiler
创建了 compiler 对象,compiler 可以理解为 webpack 编译的调度中心,是一个编译器实例,在 compiler 对象记录了完整的 webpack 环境信息,在 webpack 的每个进程中,compiler 只会生成一次。
class Compiler extends Tapable {
constructor(context) {
super();
this.hooks = {
beforeCompile: new AsyncSeriesHook(["params"]),
compile: new SyncHook(["params"]),
afterCompile: new AsyncSeriesHook(["compilation"]),
make: new AsyncParallelHook(["compilation"]),
entryOption: new SyncBailHook(["context", "entry"])
// 定义了很多不同类型的钩子
};
// ...
}
}
复制代码可以看到 Compiler 对象继承自 Tapable,初始化时定义了很多钩子。
初始化默认插件和Options配置
WebpackOptionsApply 类中会根据配置注册对应的插件,其中有个比较重要的插件
new EntryOptionPlugin().apply(compiler);
compiler.hooks.entryOption.call(options.context, options.entry);
复制代码EntryOptionPlugin插件中订阅了compiler的entryOption钩子,并依赖SingleEntryPlugin插件
module.exports = class EntryOptionPlugin {
apply(compiler) {
compiler.hooks.entryOption.tap("EntryOptionPlugin", (context, entry) => {
return new SingleEntryPlugin(context, item, name);
});
}
};
复制代码SingleEntryPlugin 插件中订阅了 compiler 的 make 钩子,并在回调中等待执行 addEntry,但此时 make 钩子还并没有被触发哦
apply(compiler) {
compiler.plugin("compilation", (compilation, params) => {
const normalModuleFactory = params.normalModuleFactory;
// 这里记录了 SingleEntryDependency 对应的工厂对象是 NormalModuleFactory
compilation.dependencyFactories.set(SingleEntryDependency, normalModuleFactory);
});
compiler.hooks.make.tapAsync(
"SingleEntryPlugin",
(compilation, callback) => {
const { entry, name, context } = this;
// 创建单入口依赖
const dep = SingleEntryPlugin.createDependency(entry, name);
// 正式进入构建阶段
compilation.addEntry(context, dep, name, callback);
}
);
}
复制代码run
初始化 compiler 后,根据 options 的 watch 判断是否启动了 watch,如果启动 watch 了就调用 compiler.watch 来监控构建文件,否则启动 compiler.run 来构建文件,compiler.run 就是我们此次编译的入口方法,代表着要开始编译了。
构建编译阶段
调用 compiler.run 方法来启动构建
run(callback) {
const onCompiled = (err, compilation) => {
this.hooks.done.callAsync(stats, err => {
return finalCallback(null, stats);
});
};
// 执行订阅了compiler.beforeRun钩子插件的回调
this.hooks.beforeRun.callAsync(this, err => {
// 执行订阅了compiler.run钩子插件的回调
this.hooks.run.callAsync(this, err => {
this.compile(onCompiled);
});
});
}
复制代码compiler.compile 开始真正执行我们的构建流程,核心代码如下
compile(callback) {
// 实例化核心工厂对象
const params = this.newCompilationParams();
// 执行订阅了compiler.beforeCompile钩子插件的回调
this.hooks.beforeCompile.callAsync(params, err => {
// 执行订阅了compiler.compile钩子插件的回调
this.hooks.compile.call(params);
// 创建此次编译的Compilation对象
const compilation = this.newCompilation(params);
// 执行订阅了compiler.make钩子插件的回调
this.hooks.make.callAsync(compilation, err => {
compilation.finish(err => {
compilation.seal(err => {
this.hooks.afterCompile.callAsync(compilation, err => {
return callback(null, compilation);
});
})
})
})
})
}
复制代码在compile阶段,Compiler 对象会开始实例化两个核心的工厂对象,分别是 NormalModuleFactory 和 ContextModuleFactory。工厂对象顾名思义就是用来创建实例的,它们后续用来创建 module 实例的,包括 NormalModule 以及 ContextModule 实例。
Compilation
创建此次编译的 Compilation 对象,核心代码如下:
newCompilation(params) {
// 实例化Compilation对象
const compilation = new Compilation(this);
this.hooks.thisCompilation.call(compilation, params);
// 调用this.hooks.compilation通知感兴趣的插件
this.hooks.compilation.call(compilation, params);
return compilation;
}
复制代码Compilation 对象是后续构建流程中最核心最重要的对象,它包含了一次构建过程中所有的数据。也就是说一次构建过程对应一个 Compilation 实例。在创建 Compilation 实例时会触发钩子 compilaiion 和 thisCompilation。
在Compilation对象中:
- modules 记录了所有解析后的模块
- chunks 记录了所有chunk
- assets记录了所有要生成的文件
上面这三个属性已经包含了 Compilation 对象中大部分的信息,但目前也只是有个大致的概念,特别是 modules 中每个模块实例到底是什么东西,并不太清楚。先不纠结,毕竟此时 Compilation 对象刚刚生成。
make
当 Compilation 实例创建完成之后,webpack 的准备阶段已经完成,下一步将开始 modules 的生成阶段。
this.hooks.make.callAsync() 执行订阅了 make 钩子的插件的回调函数。回到上文,在初始化默认插件过程中(WebpackOptionsApply类),SingleEntryPlugin 插件中订阅了 compiler 的 make 钩子,并在回调中等待执行 compilation.addEntry 方法。
生成modules
compilation.addEntry 方法会触发第一批 module 的解析,即我们在 entry 中配置的入口文件 index.js。在深入 modules 的构建流程之前,我们先对模块实例 module 的概念有个了解。
modules
Dependency,可以理解为还未被解析成模块实例的依赖对象。比如配置中的入口模块,或者一个模块依赖的其他模块,都会先生成一个Dependency对象。每个Dependency都会有对应的工厂对象,比如我们这次debuger的代码,入口文件index.js首先生成SingleEntryDependency, 对应的工厂对象是NormalModuleFactory。(前文说到SingleEntryPlugin插件时有放代码,有疑惑的同学可以往前翻翻看)
// 创建单入口依赖
const dep = SingleEntryPlugin.createDependency(entry, name);
// 正式进入构建阶段
compilation.addEntry(context, dep, name, callback);
复制代码SingleEntryPlugin插件订阅的make事件,将创建的单入口依赖传入compilation.addEntry方法,addEntry主要执行_addModuleChain()
_addModuleChain
_addModuleChain(context, dependency, onModule, callback) {
...
// 根据依赖查找对应的工厂函数
const Dep = /** @type {DepConstructor} */ (dependency.constructor);
const moduleFactory = this.dependencyFactories.get(Dep);
// 调用工厂函数NormalModuleFactory的create来生成一个空的NormalModule对象
moduleFactory.create({
dependencies: [dependency]
...
}, (err, module) => {
...
const afterBuild = () => {
this.processModuleDependencies(module, err => {
if (err) return callback(err);
callback(null, module);
});
};
this.buildModule(module, false, null, null, err => {
...
afterBuild();
})
})
}
复制代码_addModuleChain中接收参数dependency传入的入口依赖,使用对应的工厂函数NormalModuleFactory.create方法生成一个空的module对象,回调中会把此module存入compilation.modules对象和dependencies.module对象中,由于是入口文件,也会存入compilation.entries中。随后执行buildModule进入真正的构建module内容的过程。
buildModule
buildModule方法主要执行module.build(),对应的是NormalModule.build()
// NormalModule.js
build(options, compilation, resolver, fs, callback) {
return this.doBuild(options, compilation, resolver, fs, err => {
...
// 一会儿讲
}
}
复制代码先来看看doBuild中做了什么
doBuild(options, compilation, resolver, fs, callback) {
...
runLoaders(
{
resource: this.resource, // /src/index.js
loaders: this.loaders, // `babel-loader`
context: loaderContext,
readResource: fs.readFile.bind(fs)
},
(err, result) => {
...
const source = result.result[0];
this._source = this.createSource(
this.binary ? asBuffer(source) : asString(source),
resourceBuffer,
sourceMap
);
}
)
}
复制代码一句话说,doBuild 调用了相应的 loaders ,把我们的模块转成标准的JS模块。这里,使用babel-loader 来编译 index.js ,source就是 babel-loader 编译后的代码。
// source
"debugger; import { helloWorld } from './helloworld.js';document.write(helloWorld());”
复制代码同时,还会生成this._source对象,有name和value两个字段,name就是我们的文件路径,value就是编译后的JS代码。模块源码最终是保存在 _source 属性中,可以通过 _source.source() 来得到。回到刚刚的NormalModule中的build方法
build(options, compilation, resolver, fs, callback) {
...
return this.doBuild(options, compilation, resolver, fs, err => {
const result = this.parser.parse(
this._source.source(),
{
current: this,
module: this,
compilation: compilation,
options: options
},
(err, result) => {
}
);
}
}
复制代码经过 doBuild 之后,我们的任何模块都被转成了标准的JS模块。接下来就是调用Parser.parse方法,将JS解析为AST。
// Parser.js
const acorn = require("acorn");
const acornParser = acorn.Parser;
static parse(code, options) {
...
let ast = acornParser.parse(code, parserOptions);
return ast;
}
复制代码生成的AST结果如下:
import { helloWorld } from './helloworld.js' 或const xxx = require('XXX')的模块引入语句,webpack会记录下这些依赖项,并记录在module.dependencies数组中。到这里,入口module的解析过程就完成了,解析后的module大家有兴趣可以打印出来看下,这里我只截图了module.dependencies数组。Compilation例对象的succeedModule钩子,订阅这个钩子获取到刚解析完的 module 对象。 随后,webpack会遍历module.dependencies数组,递归解析它的依赖模块生成module,最终我们会得到项目所依赖的所有 modules。遍历的逻辑在afterBuild() -> processModuleDependencies() -> addModuleDependencies() -> factory.create()。make阶段到此结束,接下去会触发compilation.seal方法,进入下一个阶段。
生成chunks
compilation.seal 方法主要生成chunks,对chunks进行一系列的优化操作,并生成要输出的代码。webpack 中的 chunk ,可以理解为配置在 entry 中的模块,或者是动态引入的模块。
chunk内部的主要属性是_modules,用来记录包含的所有模块对象。所以要生成一个chunk,就先要找到它包含的所有modules。下面简述一下chunk的生成过程:
- 先把
entry中对应的每个module都生成一个新的chunk - 遍历
module.dependencies,将其依赖的模块也加入到上一步生成的chunk中 - 若某个module是动态引入的,为其创建一个新的chunk,接着遍历依赖
下图是我们此次demo生成的this.chunks,_modules中有两个模块,分别是入口index模块,与其依赖helloworld模块。
compilation.seal 方法中,有大量的钩子执行的代码。
this.hooks.optimizeModulesBasic.call(this.modules);
this.hooks.optimizeModules.call(this.modules);
this.hooks.optimizeModulesAdvanced.call(this.modules);
this.hooks.optimizeChunksBasic.call(this.chunks, this.chunkGroups);
this.hooks.optimizeChunks.call(this.chunks, this.chunkGroups);
this.hooks.optimizeChunksAdvanced.call(this.chunks, this.chunkGroups);
...
复制代码例如,插件SplitChunksPlugin订阅了compilation的optimizeChunksAdvanced钩子。至此,我们的modules和chunks都生成了,该去生成文件了。
生成文件
首先需要生成最终的代码,主要在compilation.seal 中调用了 compilation.createChunkAssets方法。
for (let i = 0; i < this.chunks.length; i++) {
const chunk = this.chunks[i];
const template = chunk.hasRuntime()
? this.mainTemplate
: this.chunkTemplate;
const manifest = template.getRenderManifest({
...
})
...
for (const fileManifest of manifest) {
source = fileManifest.render();
}
...
this.emitAsset(file, source, assetInfo);
}
复制代码createChunkAssets方法会遍历chunks,来渲染每一个chunk生成代码。其实,compilation对象在实例化时,同时还会实例化三个对象,分别是MainTemplate, ChunkTemplate和ModuleTemplate。这三个对象是用来渲染chunk,得到最终代码模板的。它们之间的不同在于,MainTemplate用来渲染入口 chunk,ChunkTemplate用来渲染非入口 chunk,ModuleTemplate用来渲染 chunk 中的模块。
这里, MainTemplate 和 ChunkTemplate 的 render 方法是用来生成不同的"包装代码"的,MainTemplate 对应的入口 chunk 需要带有 webpack 的启动代码,所以会有一些函数的声明和启动。而包装代码中,每个模块的代码是通过 ModuleTemplate 来渲染的,不过同样只是生成”包装代码”来封装真正的模块代码,而真正的模块代码,是通过模块实例的 source 方法来提供。这么说可能不是很好理解,直接看看最终生成文件中的代码,如下:
emitAsset 将其存在 compilation.assets 中。当所有的 chunk 都渲染完成之后,assets 就是最终更要生成的文件列表。至此,compilation 的 seal 方法结束,也代表着 compilation 实例的所有工作到此也全部结束,意味着一次构建过程已经结束,接下来只有文件生成的步骤了。
emit
在 Compiler 开始生成文件前,钩子 emit 会被执行,这是我们修改最终文件的最后一个机会,生成的在此之后,我们的文件就不能改动了。
this.hooks.emit.callAsync(compilation, err => {
if (err) return callback(err);
outputPath = compilation.getPath(this.outputPath);
this.outputFileSystem.mkdirp(outputPath, emitFiles);
});
复制代码webpack 会直接遍历 compilation.assets 生成所有文件,然后触发钩子done,结束构建流程。
总结
我们将webpack核心的构建流程都过了一遍,希望在阅读完全文之后,对大家了解 webpack原理有所帮助~
本片文章代码都是经过删减更改处理的,都是为了能更好的理解。能力有限,如果有不正确的地方欢迎大家指正,一起交流学习。