郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

PLOS COMPUTATIONAL BIOLOGY, (2011)
Abstract
计算神经科学领域的一个开放问题是如何将突触可塑性与系统级学习联系起来。在这种情况下,一个有前途的框架是时序差分(TD)学习。支持哺乳动物大脑执行时序差分学习假设的实验证据包括中脑多巴胺能神经元的阶段性活动与TD误差的相似性以及皮质纹状体突触可塑性受多巴胺调节的发现。然而,由于相位多巴胺能信号不能复现理论TD误差的所有特性,因此尚不清楚它是否能够在复杂任务中驱动行为适应。在此,我们提出了一个基于actor-critic架构的脉冲时序差分学习模型。该模型动态生成具有真实发放率的多巴胺能信号,并利用该信号作为第三个因素调节突触的可塑性。我们提出的可塑性动力学的预测与多巴胺、突触前和突触后活动的实验结果非常一致。从我们提出的可塑性动力学参数到经典离散时间TD算法的参数的分析映射表明,多巴胺能信号的生物约束需要改进的TD算法,该算法具有自适应学习参数和自适应偏移量。我们表明,神经元网络能够像相应的经典离散时间TD算法一样快速地学习具有稀疏正奖励的任务。然而,与传统算法相比,神经元网络在正负奖励任务上的表现受到损害,并且在纯负奖励任务上完全崩溃。我们的模型表明,当学习由正奖励驱动时,现实多巴胺能信号的不对称性使TD学习成为可能,但在负奖励驱动时则不然。
Author Summary
当我们解决问题或学习新技能时,大脑会发生哪些生理变化?通常认为行为适应是通过突触功效的变化在微观层面上实现的。然而,由于难以识别相关突触并在行为任务期间长期监测它们,这很难通过实验验证。为了在计算上解决这个问题,我们开发了一个actor-critic时序差分学习的脉冲神经网络模型,这是一种强化学习的变体,其神经相关性已经部分建立。该网络通过内部生成的奖励信号来学习一项复杂的任务,该奖励信号受多巴胺能系统最近发现的约束。我们的模型结合了自上而下和自下而上的建模方法,以弥合突触可塑性和系统级学习之间的差距。它为进一步研究多巴胺能系统在健康大脑和帕金森病等病理条件下的奖励学习铺平了道路,并可用作基于大脑规模电路的功能模型的模块。
Introduction
(略)
最近,我们提出了第一个脉冲神经网络模型来实现具有预测和控制的完整TD(0)实现,并证明它能够解决具有稀疏奖励的非平凡任务[34]。然而,在该模型中,每个突触都执行自己的TD误差近似,而不是像实验证据[2,3]所建议的那样以神经调节信号的形式接收它。我们现在提出第一个actor-critic TD学习智能体的脉冲神经元模型,它根据网络本身动态生成的多巴胺能信号调整其行为。我们结合自上而下和自下而上的方法开发模型。这些项可以用几种不同的方式来解释;参见[35]进行分析。我们的解释如下:自上而下的方法构建一个系统来实现所需的功能。在我们的案例中,我们设计了映射到时序差分学习的更新规则的突触可塑性规则,同时遵守对突触可用信息的合理生物学约束。相反,自下而上的神经元建模方法整合了来自实验分析的信息,以生成更复杂的系统。在此,我们将已知的多巴胺能活动动力学特征与皮质纹状体突触对多巴胺存在的敏感性相结合。
我们表明,依赖于具有真实发放率的多巴胺能信号的多巴胺依赖可塑性确实可以实现TD学习。我们的可塑性模型取决于全局多巴胺能信号以及突触前和突触后脉冲的时间。尽管突触可塑性的动力学是使用自上而下的方法构建的,以重现TD学习的行为修改更新的关键特征,但我们发现我们的可塑性模型的预测与皮质纹状体突触的实验结果之间存在很好的一致性。具有真实发放率的多巴胺能信号与TD误差之间的差异导致了略微修改的TD学习算法,该算法具有自适应学习参数和自适应偏移量。我们提出的突触可塑性模型的参数可以分段解析映射到TD算法的经典离散时间实现的参数,用于TD误差的正值和小负值。我们表明,尽管进行了这些修改,神经元网络仍能够像相应的算法实现一样快速且稳定地解决具有稀疏正奖励的非平凡网格世界任务。突触权重在学习过程中发展,以反映状态相对于其奖励接近度的值以及最大化奖励的最佳策略。我们展示了修改学习算法对悬崖行走任务的影响。当外部奖励完全为负时,神经网络无法学习任务。如果任务包括正奖励和负奖励,神经元网络仍然可以学习它,但比相应的经典离散时间算法慢,并且平衡性能更差。我们的结果支持负奖励是由不同的解剖结构和神经调节系统介导的假设。
Temporal-difference learning in the actor-critic architecture
在本文中,我们关注TD学习的一个特定变体:由actor-critic架构[36]实现的TD(0)算法。在此,我们总结了基本原理; 完整的介绍可以在[1]中找到。
与每个强化学习智能体一样,TD学习智能体的目标是最大化它随着时间的推移获得的累积奖励。actor-critic架构(见图1)通过使用两个模块,actor和critic来实现这一目标。actor模块学习了一个策略π(s,a),它给出了在状态 s 中选择动作 a 的概率。Gibbs softmax分布给出了定义策略的常用方法:
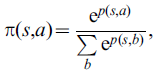
其中p(s,a)被称为状态 s 中动作 a 的偏好,索引 b 遍历状态 s 中所有可能的动作。
critic评估actor模块选择的动作相对于价值函数的后果。一旦学习达到平衡,价值函数Vπ(s)是从状态 s 开始并遵循策略 π 时的期望总和折扣未来奖励。在学习过程中,只有实际价值函数的估计V(s)可用。通过对策略和价值函数进行连续更新,可以提高智能体在任务上的性能。这些更新通常是在假设时间和空间离散化的情况下制定的:误差项 δ 是根据从一个离散状态sn移动到下一个离散状态sn+1时价值函数估计的差异计算得出的:
![]()
其中rn+1是智能体在进入状态sn+1时收到的奖励,γ ∈ [0,1]是折扣因子。这个误差信号 σ,称为TD误差,如果奖励大于V(sn)和V(sn+1)之间的预期折扣差,则为正,表明需要增加 V(sn)的估计。相反,如果奖励小于预期的折扣差,则 σ 为负,表明需要降低对V(sn)的估计。在最简单的TD学习版本中,称为TD(0)算法,critic改进了它对V(sn)的估计如下:
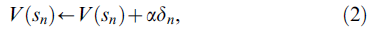
其中 a 是一个小的正步长参数。 对于给定的策略和足够小的 a,TD(0)学习算法以概率1收敛[37,38]。此外,在状态 s 中选择的动作 a 的偏好会被调整,以便在智能体下次访问该状态时相应地或多或少地选择该动作。在actor-critic架构中更新偏好的一种可能性是:
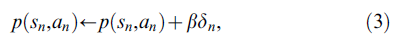
其中 b 是另一个小步长参数。出于本手稿的目的,我们将上述误差信号的计算以及价值函数和策略的更新称为经典的离散时间TD(0)算法。
Results
Spiking actor-critic architecture
Dopaminergic error signal
Synaptic plasticity
Comparison of predictions of the synaptic plasticity models with experimental results
Grid-world task
Cliff-walk task
Discussion
Learning performance on the grid-world task
Learning performance on the cliff-walk task
Model architecture
Dependence on model size
Synaptic plasticity dynamics realizing TD learning
TD learning and the brain
Methods
Neuronal network simulations