郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

IEEE transactions on neural networks and learning systems, (2020): 1-14
Abstract
脉冲神经网络是大脑中多功能和高效信息处理的基础。尽管我们目前缺乏对这些网络如何计算的详细了解,但最近开发的优化技术使我们能够在计算机上实例化日益复杂的功能脉冲神经网络。这些方法有望构建更高效的非冯诺依曼计算硬件,并将为探索脑回路功能提供新的前景。为了加速这些方法的发展,客观的方法来比较它们的性能是必不可少的。然而,目前还没有被广泛接受的方法来比较脉冲神经网络的计算性能。为了解决这个问题,我们引入了两个基于脉冲的分类数据集,广泛适用于对脉冲神经网络的软件和神经形态硬件实现进行基准测试。为此,我们开发了一种受神经生理学启发的通用音频到脉冲转换程序。此外,我们将此转换应用于现有的和新颖的语音数据集。后者是我们专门为这项研究创建的免费、高保真和字级对齐的海德堡数字数据集。通过训练一系列常规和脉冲分类器,我们表明利用这些数据集中的脉冲时序信息对于良好的分类准确性至关重要。这些结果可作为脉冲神经网络未来性能比较的第一个参考。
Index Terms——Audio, benchmark, classification, data set, neuromorphic computing, spiking neural networks, spoken digits, surrogate gradients.
I. INTRODUCTION
脉冲神经网络(SNN)是用于快速和多功能信息处理的生物学解决方案。从计算的角度来看,SNN具有几个理想的特性:它们并行处理信息、耐噪声和高能效[1]。在给定的生物学SNN中执行哪些计算在很大程度上取决于其连接结构。为了在计算机上实例化这种功能连接,已经为传统计算机和神经形态硬件[9]-[14]开发了越来越多的SNN训练算法[2]-[8]。然而,这种学习算法的多样性迫切需要有原则的方法来比较它们。不幸的是,允许进行此类比较的广泛接受的SNN基准数据集很少[14][15]。因此,在本文中,我们试图通过为SNN引入两个新的广泛适用的分类数据集来填补这一空白。
在下文中,我们简要介绍了为什么基准测试至关重要,然后再回顾过去用于评估SNN性能的现有任务。通过分析这些任务的优缺点,我们激发了我们对本文介绍的数据集的具体选择。最后,我们通过在这些数据集上测试一系列常规和SNN分类器来建立第一组基线。
A. Why Benchmarks?
基准测试的最终目标是提供一种定量无偏的方法来比较同一问题的不同方法和方法。虽然每个建模者通常使用一组私人基准,针对他们的具体研究问题量身定制,但同样重要的是共享基准,理想情况下每个人都同意使用,以便进行无偏见的比较并促进方法之间的建设性竞争[14][15]。
例如,如果没有无处不在的MNIST数据集[16],过去几十年的机器学习研究将难以想象。要使用SNN处理MNIST,必须将其转换为脉冲。此转换步骤将基本设计决策留给建模者,从而使可比性面临风险。目前,SNN网络社区缺乏通过直接向最终用户提供脉冲序列来避免转换步骤的既定基准。通过阻碍方法之间的定量比较,缺乏合适的基准有可能减缓整个SNN研究社区的进展。
既然社区基准是必不可少的,那么为什么在使用哪个基准上几乎没有一致意见呢?有几个可能的原因,但最可能的原因如下:首先,现有的基准可能无法获得。例如,它可能未发布、在付费墙后面或太难使用。其次,发布的基准可能是针对特定问题量身定制的,因此不够通用,不足以引起其他研究人员的兴趣。 第三,基准可能是饱和的,这意味着它已经通过现有方法以高精度求解。自然地,这排除了对这些方法的改进的表征。最后,基准测试可能需要大量预处理。
因此,问题是:用于SNN学习的理想基准数据集是什么?虽然这个问题很难回答(如果不是不可能的话),但可以公平地说,理想的基准测试应该至少是不饱和的、需要最少的预处理、足够通用、易于获取和免费使用。
B. Previous Work
没有统一的方法来衡量SNN的性能,这部分是由于许多不同的学习方法和架构。SNN架构可以粗略地分为稳态发放率编码和时序编码网络,尽管两者之间也存在混合。在稳态发放率编码中,SNN通过使用有效的发放率代码来逼近传统的模拟神经网络,其中输入和输出发放率在单个刺激的呈现期间保持恒定[3][17][18]。网络的输入以泊松分布的脉冲序列形式输入,其发放率与当前输入水平成正比。类似地,网络输出以指定输出单元的发放率或脉冲计数给出。由于这些输入输出规范,稳态发放率编码网络通常可以使用网络翻译[3]进行训练,并且可以在标准机器学习数据集(例如MNIST [16]、CIFAR10 [19]或SVHN [20])。
然而,SNN的能力超越了这种发放率编码网络。在时序编码网络中,输入和输出活动在处理单个输入示例期间会发生变化。在此编码方案中,输出可以是单个脉冲[21]-[24]、具有预定义触发时间的脉冲序列[25]、不同的发放率[26]-[28],或从输出脉冲衍生的连续变化量。后者通常被定义为低通滤波脉冲序列的线性组合[26][27][29]-[31]。
最简单的时序编码基准之一是时序异或(XOR)任务,它存在于不同的变体中[22][31][32]。没有隐藏层的简单SNN无法解决这个问题,类似于感知器无法解决常规XOR任务。因此,时序XOR通常用于证明特定方法支持隐藏层学习。在时序XOR任务中,神经网络必须解决布尔XOR问题,其中逻辑off和on水平分别对应于早期和晚期脉冲时间。虽然时序XOR确实需要正确求解隐藏层,但其固有的低维性和输入模式的数量少导致该基准饱和。因此,它在训练方法之间进行定量比较的可能性是有限的。
为了以更细粒度的方式评估学习,一些研究集中在SNN在更一般的场景中生成精确定时输出脉冲序列的能力[25][33]-[37]。为此,习惯上使用几个泊松输入脉冲序列来生成特定的目标脉冲序列。除了常规(参见[37])之外,还考虑了具有增加长度和泊松统计的随机输出脉冲序列[25]。类似地,Tempotron [38]使用了一种有趣的混合方法,其中随机时序编码的脉冲输入模式被分类为对应于指定输出神经元的脉冲与静止的二值类别。在相关的基准测试中,任务性能被衡量为可以正确分类的二值模式的数量。尽管将随机输入脉冲映射到输出脉冲允许在方法之间进行细粒度比较,但上述任务缺乏非随机结构。
最后,一些用于n路分类的数据集是出于实际工程需要而诞生的。这些数据集大部分基于神经形态传感器的输出,例如动态视觉传感器(DVS)[39]或硅耳蜗[40]。这种数据集的一个早期示例是神经形态MNIST [41],它是由DVS记录投影在屏幕上的MNIST数字生成的。数字以一定的间隔移动以引起DVS中的脉冲反应。任务是从引发的脉冲中识别相应的数字。该基准已在SNN社区中广泛使用。然而,基于MNIST数据集,它已接近饱和。DASDIGITS数据集[40]是通过使用64通道硅耳蜗处理TIDIGITS创建的。不幸的是,由于TIDIGITS是在专有许可下发布的,因此衍生数据集的许可要求并不完全清楚。此外,由于TIDIGITS包含语音数字序列,因此该任务超出了简单的n路分类问题,因此超出了当前几种SNN实现的范围。最近,IBM在知识共享许可下发布了DVS128手势数据集[42]。该数据集由不同人在不同照明条件下执行的11种独特手势的大量DVS记录组成。该数据集中的脉冲以连续数据流的形式提供,因此需要进行大量的切割和预处理。最后,除非应用下采样等额外的预处理步骤,否则128 × 128像素大小使该数据集的计算成本很高。
在本文中,我们试图生成两个具有相对适度计算要求的广泛适用的SNN基准。因此,我们专注于口语的音频信号,因为它们与视频数据相比具有自然的时间维度和较低的带宽,并开发了一个处理框架来将这些音频数据转换为脉冲信号。使用这个框架,我们生成了两个基于脉冲的数据集,用于语音分类和关键字发现,这些数据集未被当前方法饱和。此外,以高精度解决这些问题需要考虑脉冲时间。
II. METHODS
为了改进SNN之间的定量比较,我们从音频数据中创建了两个基于脉冲的大型分类数据集。具体来说,我们为此目的记录了海德堡数字(HD)数据集,并使用了TensorFlow和AI 团队[43]发布的语音命令(SC)数据集。在下文中,我们描述了数据集(第II-A节)、音频到脉冲的转换(第II-B节)以及用于发布的数据格式(第II-C节)。我们以对SNN模型(第II-D节)的描述结束。非脉冲分类器在B节中进行了概述。这项工作中报告的所有误差度量都对应于10个实验的标准差。
A. Audio Data Sets
下面,我们考虑HD(第II-A1节)和SC数据集(第II-A2节)。虽然HD针对录制质量和精确的音频对齐进行了优化,但SC旨在密切模仿移动设备上的关键字定位的真实条件。
1) Heidelberg Digits:
2) Speech Commands:
B. Spike Conversion
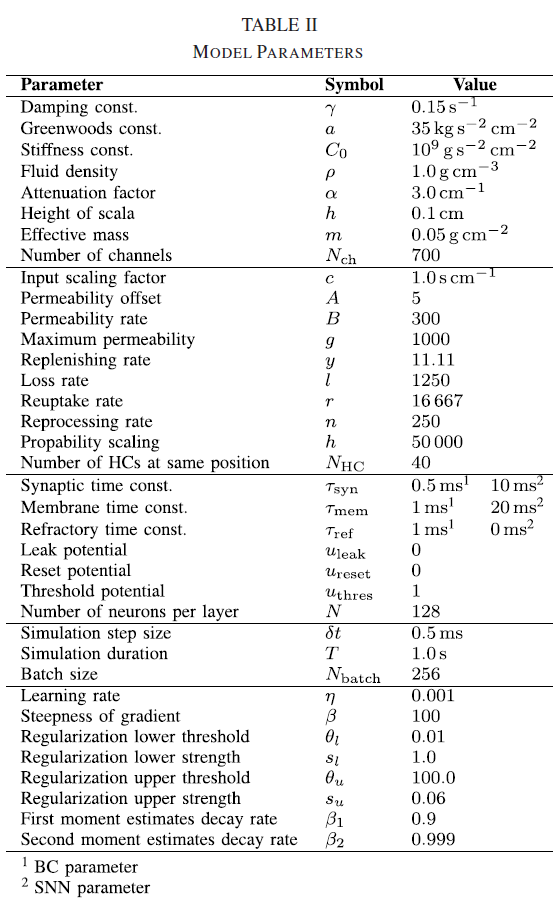
上述音频文件是我们脉冲数据集的基础。使用内耳和部分上行听觉通路的人工模型将音频数据转换为脉冲(图2;A部分)。这种受生物学启发的模型有效地执行与常规口语处理应用程序类似的信号处理步骤[46]。首先,流体动力基底膜(BM)模型(附录A-A)会导致空间频率色散,这与使用Melspaced滤波器组计算频谱图相当。其次,这些分离的频率通过基于生物激励的发射器池的毛细胞(HC)模型(附录A-B)转换为瞬时发放率,该模型增加了不应效应,以及一层增加相位锁定的浓密细胞(BCs)(附录A-C)(见图2)。选择所有模型参数以模拟生物学发现,从而减少自由参数的数量(见附录A)。
总体而言,内耳模型近似于在听觉系统中观察到的脉冲活动,同时保持较低的计算成本。这种受生物学启发的转换使我们能够回避用户特定的音频到脉冲转换的问题,这可能会混淆可比性,并作为我们基准数据集的基础。
C. Event-Based Data Format

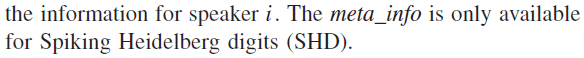
D. Spiking Network Models
我们使用有监督的损失函数训练了具有替代梯度和随时间反向传播(BPTT)的LIF神经元网络,以在两个脉冲数据集上建立性能参考。在下文中,我们描述了网络架构(第II-D1节),然后是应用的神经元和突触模型(第II-D2节)。我们最后描述了权重初始化(第II-D3节)、监督学习算法(第II-D4节)和损失函数(第II-D5节)以及正则化技术(第II-D6节)。
1) Network Model: Nch = 700 BCs发出的脉冲序列用于刺激实际的分类网络。在本文中,我们训练了前馈网络和循环网络;每个隐藏层包含N = 128个LIF神经元。对于所有网络架构,最后一层都伴随着一个线性读数,该读数由没有脉冲的泄漏积分器组成。
2) Neuron and Synapse Models:
3) Weight Initialization:
4) Supervised Learning:
5) Loss Functions: 我们对读出层l = L的活动应用了交叉熵损失。在具有Nbatch样本和Nclass类的数据上,{(xs , ys)|s = 1, ... , Nbatch; ys ∈ {1, ... , Nclass}},它采用以下形式:
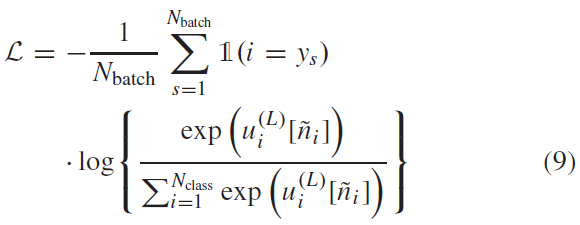
使用指示函数![]() 。我们测试了时间步骤
。我们测试了时间步骤![]() 的以下两种选择:对于max-over-time损失,考虑每个读数单元具有最大膜电位的时间步骤
的以下两种选择:对于max-over-time损失,考虑每个读数单元具有最大膜电位的时间步骤![]() 。相反,在last-time-step的情况下,为每个读出神经元选择所有样本的最后一个时间步骤
。相反,在last-time-step的情况下,为每个读出神经元选择所有样本的最后一个时间步骤![]() 。我们使用Adamax优化器[52]最小化了(9)中的交叉熵。
。我们使用Adamax优化器[52]最小化了(9)中的交叉熵。
6) Regularization:
III. RESULTS
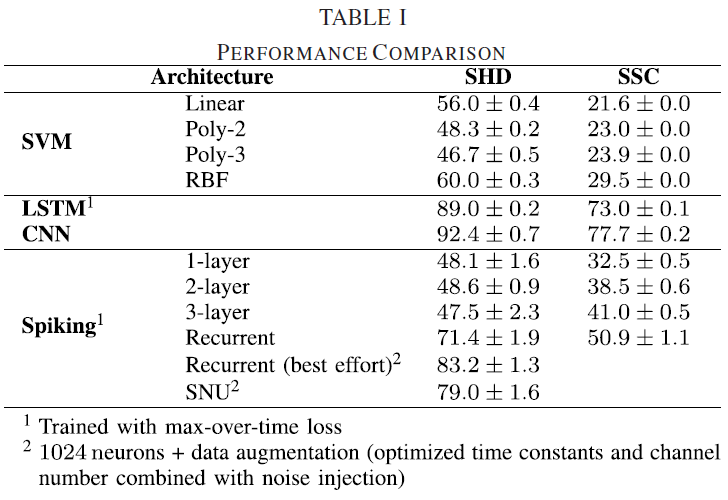
为了分析我们新创建的脉冲数据集的相关性,我们首先试图确定数据集没有饱和,并且脉冲时序信息对于以高精度解决任务至关重要。为了测试这一点,我们首先生成了数据集的简化版本,其中我们删除了所有时序信息。为此,我们从两个数据集中计算了脉冲计数模式,根据设计,这些数据集不包含有关刺激的时序信息。使用这些减少的脉冲计数数据集,我们随后训练了不同的线性和非线性支持向量机(SVM)分类器(B-A部分),并测量了它们在各自测试集上的分类性能。我们发现,虽然线性SVM很容易在SHD的情况下过拟合数据,但其测试性能仅略微超过55%的准确度标记[图3(a)]。对于脉冲语音命令(SSC),过拟合不太明显,但整体测试准确度也下降到20%[图3(b)]。因此线性分类器提供了低程度的泛化。
为了评估非线性分类器的这种情况是否不同,我们用多项式核训练了最多3次的SVM。对于这些核,过拟合不太明显。当使用带有径向基函数(RBF)核的SVM时,SHD的性能略好于60%,脉冲SC (SSC)的性能提高了30%。与验证数据的准确性相比,SHD测试集(包括不属于训练集的说话者)的性能明显较低。特别是,对于多项式和RBF核,跨扬声器的泛化比线性核差[图3(a)]。相比之下,我们发现SSC测试集的性能与验证集的准确性相当[图3(b)],这很可能是均匀扬声器分布的影响。这些结果表明,在没有时序信息的情况下,在脉冲计数模式上训练的线性和非线性分类器都无法超过SHD的60%准确度标记和SSC数据集的30%标记。因此,脉冲计数不足以在所研究的数据集上实现高分类精度。
接下来,我们想评估在训练可以显式访问脉冲时间的时序信息的分类器时是否可以提高解码精度。因此,我们在脉冲活动的时间直方图上训练了长短期记忆(LSTM)(B-B部分)。尽管SHD数据集的规模很小,但LSTM显示出减少了过拟合,并且能够以85.7(14)%的准确度解决分类问题[图3(a)],这大大高于性能最好的SVM。同样,对于SSC数据集,LSTM测试准确度75.0(2)%是脉冲计数数据上表现最好的分类器的两倍多。然而,过拟合的程度略高于SHD。
由于核机器和LSTM都受到过拟合的影响,我们测试了卷积神经网络(CNN)是否可以提高性能,因为它们在频率和时间上对平移不变性的归纳偏差以及参数数量的减少。为此,我们将时空直方图中的脉冲分箱并训练了一个CNN分类器(B-C部分)。在所有测试的分类器中,CNN显示出最少的过拟合;SHD的准确度仅下降1.4%,SSC的准确度下降1.5%(图3)。特别是,SHD测试数据的性能与验证集的性能相当,表现出高度的泛化性。
这些发现强调了两个数据集中包含的时序信息可以被合适的神经网络架构利用。此外,这些结果为两个数据集的性能上限提供了一个下限。似乎更仔细的架构搜索和超参数调整只会改善这些结果。因此,SHD和SSC都可用于SNN之间的定量比较,至少达到这些经验准确度值。
A. Training Spiking Neural Networks
在确定两个脉冲数据集都包含可以由合适的分类器读取的有用时间信息后,我们试图使用BPTT训练LIF神经元的SNN,以建立第一组基线并评估它们的泛化特性。使用梯度下降训练SNN的一个问题出现了,因为神经激活函数的导数出现在梯度的评估中。由于脉冲是一个本质上不连续的过程,因此产生的梯度是不明确的。尽管如此,为了使用监督损失函数训练LIF神经元网络,我们使用了替代梯度方法[8]。替代梯度可以看作是SNN真实梯度的连续松弛,可以在执行BPTT时作为就地替换来实现。重要的是,我们没有改变神经元模型和模型的相关前向传递,而是在计算梯度时使用快速sigmoid作为替代激活函数(Methods部分II-D4)。
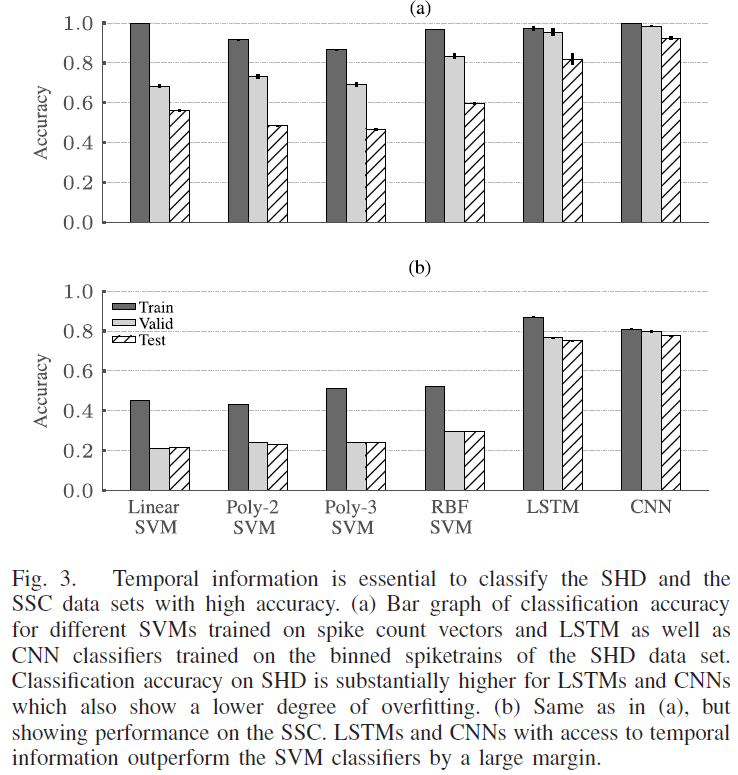
虽然不是要求[8][53],但我们只考虑了受生物学启发的具有固定有限时间常数的SNN,时间常数约为ms。由于这个限制,我们研究了LSTM和SNN的两种不同的损失函数[图4(a)]。图3中所示的LSTM的结果是通过使用last-time-step损失进行训练获得的,其中每个示例和读出单元的最后时间步骤的激活用于计算输出处的交叉熵损失。此外,我们还考虑了max-over-time损失,其中考虑了每个读出单元最大激活的时间步骤[图4(a)]。这种损失函数是由Tempotron [38]推动的,其中网络通过神经元是否发放脉冲来发出其关于所应用输入模式的类成员资格的决定。
我们针对SHD上的上述两种损失函数评估了LSTM和SNN的性能。与SNN相比,基于每个样本的最后一个时间步骤的活动训练具有交叉熵损失的LSTM与高性能相关[图4(b)]。与循环连接的脉冲神经网络(RSNN)相比,使用last-time-step损失训练的前馈SNN的性能略有下降,这表明时间常数太低而无法在最后一个时间步骤提供所有必要的信息。这可能是由于通过循环连接的回响活动实现的主动记忆。总体而言,SNN与max-over-time损失函数结合起来表现更好[图4(c)]。结合max-over-time损失的LSTM还表现出更高的性能;验证准确度从last-time-step损失的95.4(17)%提高到max-over-time损失的97.2(09)%。受这些结果的启发,我们在本文的其余部分使用了SNN和LSTM的max-over-time损失。
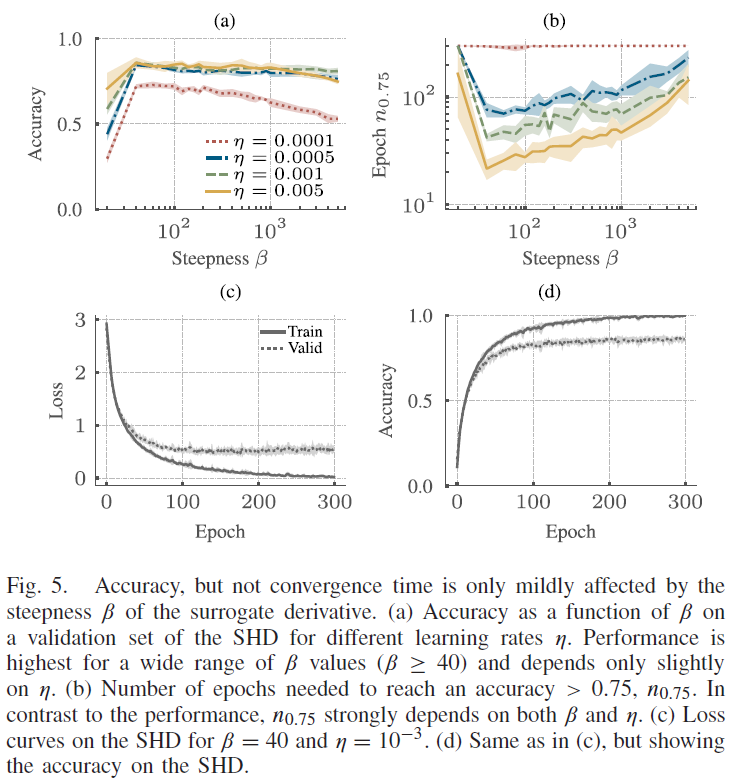
替代梯度学习引入了一个与替代导数的陡度相关的新超参数β(Methods公式(2))。因为β的变化可能需要不同的最佳学习率η,我们基于在SHD上训练的单层RSNN架构执行了β和η的网格搜索。我们发现这两个参数的合理组合会导致在大范围的值上稳定的性能平台[图5(a)]。只有在小β的情况下,准确度才会急剧下降,而对于高值,它只会缓慢下降。有趣的是,学习率对测试参数值的峰值性能几乎没有任何影响。正如预期的那样,收敛速度很大程度上取决于η和β。这些结果促使我们对本文中介绍的所有SNN架构使用β = 40和η = 1 × 10−3,除非另有说明。对于这种选择,RSNN在验证集上的性能在大约150个epoch后达到峰值[图5(d)]。额外的训练只会提高训练数据集的性能[图5(c)],但不影响泛化[图5(d)]。
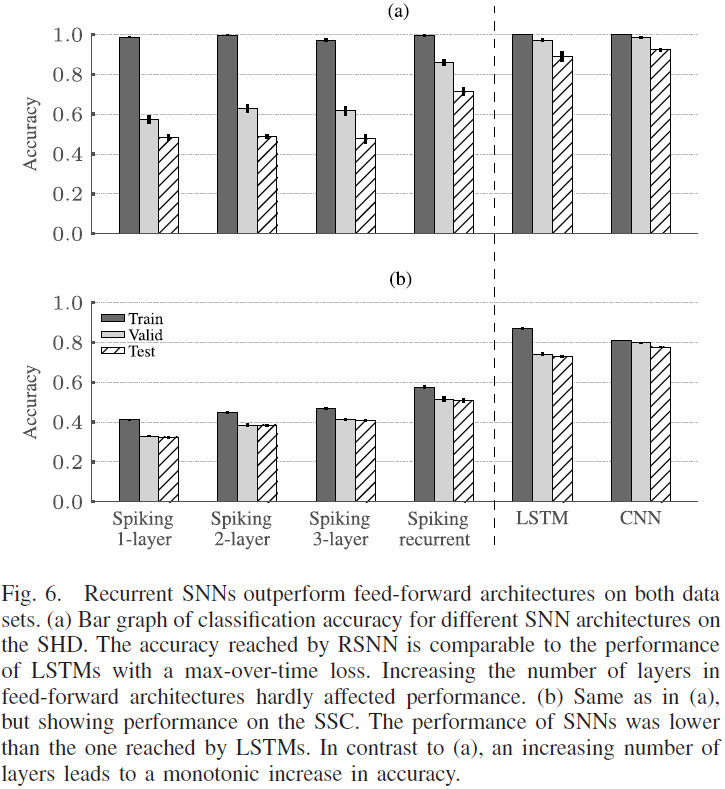
通过上面讨论的参数选择,我们在SHD和SSC上训练了各种SNN架构。为此,我们考虑了具有 l 层的多层前馈SNN和单层RSNN。有趣的是,增加隐藏层的数量 l 并没有显著提高SHD的性能[图6(a)]。此外,l 的所有选择都会导致高度过拟合。此外,前馈SNN的准确度水平略低于SHD上的SVM[图3(a)]。对于较大的SSC数据集,过拟合程度要小得多[图6(b)]并且性能明显优于SVM达到的性能[图3(b)]。在此,增加前馈SNN的层数导致测试集的性能从单层的32.5(5)%单调提高到三层情况下的41.0(5)% (l = 3)。然而,在测试RSNN时,我们发现在说话人之间始终具有更高的性能和改进的泛化能力。与LSTM的准确性相比,RSNN表现出更高的过拟合,并且在说话人之间的泛化效果较差。RSNN在SHD上达到71.4(19)%的最高准确率,在SSC上达到50.9(11)%,仍然低于LSTM,在SHD上达到85.7(14)%,在SSC上达到75.0(2)%。
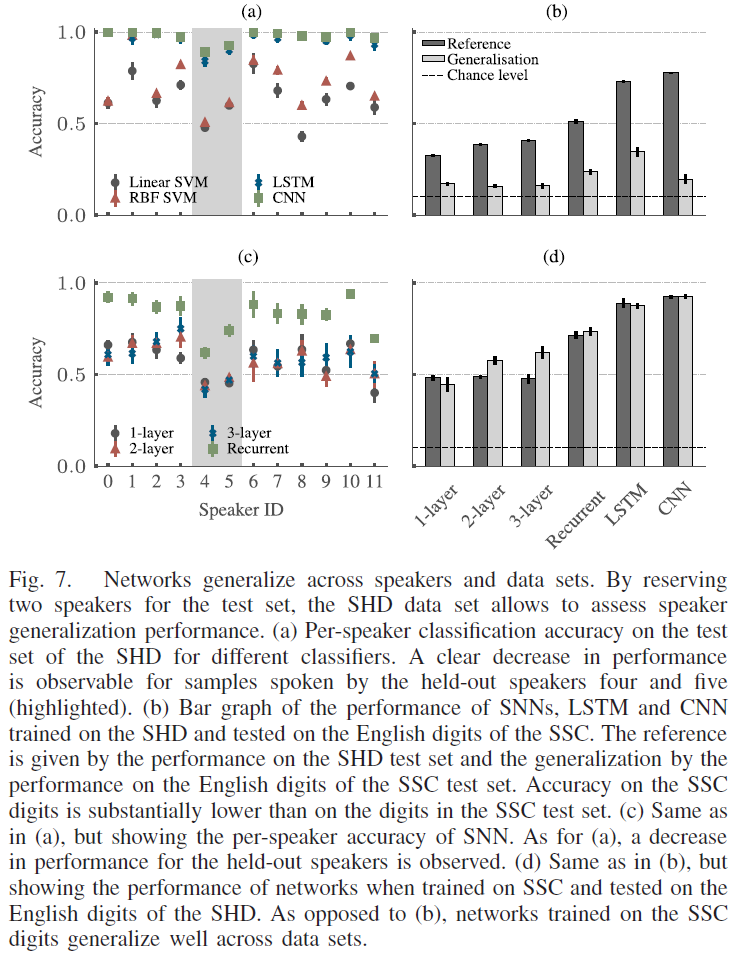
B. Generalization Across Speakers and Data Sets
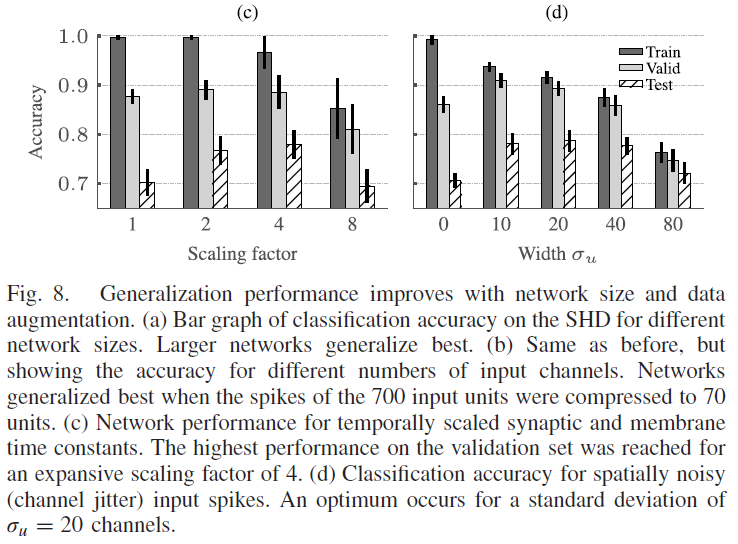
C. Improving Generalization Performance Through Data Augmentation and Larger Networks
IV. DISCUSSION
在本文中,我们介绍了两个新的公共领域基于脉冲的分类数据集,以方便SNN的定量比较。此外,我们通过训练一系列脉冲和非脉冲分类器为未来的比较提供了第一组基线。
随着这些发展,我们解决了SNN缺乏全面的基准数据集的问题。为了推进神经形态计算领域,我们需要一组基准,这些基准对量化收益和跨不同平台的标准化评估提出了现实挑战[15]。我们将本文中的数据集视为我们对这一目标的贡献。但是,由于很难预见未来发展的步伐,我们承认目前的数据集可能不是最终的。因此,为了促进它们的改进、扩展和新数据集的创建,除了脉冲数据之外,我们还发布了我们的转换软件3和原始音频数据集2,两者均在公共领域许可下。
两个脉冲数据集均基于听觉分类任务,但源自在不同记录设置中获取的数据。我们选择音频数据集作为基准测试的基础,因为音频具有时间维度,这使其成为基于脉冲的处理的自然选择。然而,与电影数据相比,音频需要更少的输入通道来实现忠实的表示,这使得派生的脉冲数据集在计算上更易于处理。
由于不同的原因,我们没有使用其他现有音频数据集之一作为脉冲版本的基础。例如,TIDIGITS数据集[54]提供了大量的口语数字。但是,此数据集仅在商业许可下可用,我们的目标是完全开放的数据集。相比之下,Free Spoken Digit Data set [55]在Creative Commons BY 4.0许可下可用。由于该数据集仅包含2k条记录,整体记录和对齐质量较低,我们认为记录HD是必要的贡献。其他数据集,例如Mozilla的Common Voice [56]、LibriSpeech [57]和TED-LIUM [58]也是公开的。然而,这些数据集提出了更具挑战性的语音检测问题,因为它们仅在句子级别对齐。这些更具挑战性的任务留给未来对功能性SNN的研究。例如,口语维基百科语料库[59]也提供了单词级别的对齐,但需要进一步的预处理,例如将音频文件分解为单独的单词。此外,每类样本的纯大小和不平衡使数据集更具挑战性。因此,我们将其转换留作未来的工作。
在撰写本文时,我们知道的唯一现有的具有字级对齐、可处理大小和预处理要求的公共领域数据集是SC数据集。这就是为什么我们选择在SC上建立一个脉冲基准,同时提供具有更高记录质量和对齐精度的单独和更小的HD数据集的原因。最后,HD的高保真记录也使其适用于定量评估噪声对网络性能的影响,因为可以添加良好表征的噪声水平。
脉冲转换步骤包括已发布的物理内耳模型[60],然后是已建立的毛细胞模型[61]。处理链由单层BC完成,以增加相位锁定并减少脉冲的总数。这种方法类似于公开可用的DASDIGIT数据集[40]。DASDIGIT由来自TIDIGIT数据集[54]的录音组成,这些录音已播放到具有2 × 64频率选择通道的动态音频传感器。与SHD和SSC相比,TIDIGIT数据集的原始音频文件仅在商业许可下可用。此外,在BM模型的频率选择频带中测量的频率分辨率大约低10倍。由于用于处理SHD和SSC数据集的软件是公开可用的,因此可以直接扩展现有数据集。这一步对于DASDIGIT来说比较困难,因为它需要一个动态音频传感器。
我们通过从HD和SC音频数据集生成脉冲来标准化从原始音频信号到脉冲的转换步骤。这样做,我们既改进了可用性设置,又减少了由于最终用户的预处理流水线的差异而导致的性能变化的常见来源。
为了建立第一组基线(表I),我们在SHD和SSC上训练了一系列非脉冲和脉冲分类器。在将完整数据集的性能与减少脉冲计数数据集的性能进行比较时,我们发现脉冲时间中可用的时序信息可以通过合适的分类器进行更好的分类。此外,具有显式递归的架构,如LSTM和RSNN,是我们测试的所有架构中性能最好的模型。(CNN?) 最有可能的是,通过循环连接的回响活动实现了所需的记忆,从而弥合了神经时间常数和音频特征之间的差距。因此,在[5]中包含在较慢时间尺度上演化的额外状态变量将是提高SNN性能的有趣扩展。
在本手稿中,我们使用替代梯度结合BPTT [5]-[8][62][63]训练SNN。然而,必须意识到存在大量基于梯度的替代方法,这些方法基于网络转换[3][64]-[66]、单脉冲计时[23][67]、平均发放率[68][69]和随机近似值[37][70]-[72]。此外,还有一些受生物学启发的替代梯度在线近似[2][73][74],最后,大量工作使用了类似于生物学激励的脉冲时序依赖可塑性(STDP)学习规则[75][76](请参见[4]进行全面审查)。对这些过多方法的深入比较超出了本手稿的范围。然而,目前的数据集可能有助于对上述工作进行更详细的比较。因此,研究STDP如何与当前数据集交互是有趣的未来工作。
我们使用LSTM和SNN对SHD和SSC的分析表明,损失函数的选择会对分类性能产生显著影响。虽然LSTM在最后一个时间步骤的损失中表现最好,其中仅使用最后一个时间步骤来计算交叉熵损失,但SNN在max-over-time损失方面达到了最高的准确度,其中每个读出单元的最大膜电位被考虑。对训练SNN的合适成本函数的详细分析是未来研究的一个有趣方向。
总之,我们引入了两个通用和开放的脉冲数据集,并使用SNN分类器进行了第一组性能测量。这构成了朝着在传统计算机和神经形态硬件上对功能SNN进行更定量比较的重要一步。
APPENDIX A
INNER EAR MODEL
A. Basilar Membrane Model
B. Hair Cell Model
C. Bushy Cell Model
APPENDIX B
NONSPIKING CLASSIFIERS
出于验证目的,我们将三种标准的非脉冲方法用于数据集的时间序列分类,即SVM、LSTM和CNN。我们将在下面详细介绍它们中的每一个。
A. Support Vector Machines
我们使用scikitlearn [81]训练线性和非线性SVM。具体来说,我们用多项式(最高三次)和RBF核训练了SVM。输入空间中的向量是这样构建的,即对于每个样本,通过计算每个样本中每个BC发出的脉冲数来生成一个Nch维向量xi。此外,通过去除均值和缩放到单位方差来标准化特征。
B. Long Short Term Memories
我们使用LSTM来验证时间数据[82]。LSTM的输入由BC发出的Nch脉冲序列组成,但在大小为10 ms的时间段中分段。我们使用带有Keras 2.3.0应用程序编程接口(API)[83][84]的TensorFlow 1.14.0训练LSTM网络。对于所有使用的层,我们坚持使用默认参数和初始化,除非另有说明。具体来说,我们考虑了具有128个单元的单个LSTM层,对于输入的线性变换和循环状态的线性变换,dropout概率为0.2。最后,应用了带有softmax激活的读数。该模型使用Adamax优化器[52]进行训练,并在最后一个时间步骤的激活和具有最大激活的时间步骤上定义了分类交叉熵损失。
C. Convolutional Neural Networks
我们应用CNN来进一步测试数据集的可分离性。为此,脉冲序列不仅在时间上进行了分段,而且在空间上也进行了分段。时间段宽度设置为10 ms。沿着空间维度,数据被分段以产生64个不同的输入单元。至于LSTM,除非另有说明,否则CNN网络是使用带有默认参数和初始化的Keras API的Tensorflow进行训练的。首先,应用具有32个大小为11 × 11的滤波器和校正线性单元(ReLU)激活函数的二维卷积层。接下来,输出由三个连续的块处理,每个块由两个二维卷积层组成,每一个都伴随着批量归一化和ReLU激活。两个卷积层都包含32个大小为 3×3 的滤波器。我们通过一个池大小为2×2的2-D最大池化层和一个比率为0.2的dropout层来最终确定这些块。三个块中最后一个块的输出由具有128个节点和ReLU激活函数的密集层处理,然后是带有softmax激活的读数。整个模型使用Adamax优化器[52]和分类交叉熵损失进行优化。