Erlang 数据类型的内部表示和实现
Erlang 中的变量在绑定之前是自由的,非绑定变量可以绑定一次任意类型的数据。为了支持这种类型系统,Erlang 虚拟机采用的实现方法是用一个带有标签的机器字表示所有类型的数据,这个机器字就叫做 term。在 32 位机器上,一个 term 为 32 位宽;在 64 位机器上,一个 term 默认为 64 位宽[注2]。由于目前大规模的服务器基本上都是 64 位平台,所以本文下面的讨论都基于 64 位平台。
Erlang 虚拟机采用的是虚拟寄存器机的形式,每一个调度器线程相当于一台虚拟的寄存器机。这种寄存器机模型下的 Erlang 进程也包含自己的栈和堆,这些栈和堆实际上就是 term 的数组。此外,这种寄存器机的寄存器文件也是用 term 数组表示的。
下面我们来详细地看一看 Erlang 中 term(Eterm)的结构。
Eterm
Eterm 是一个打了标签的机器字,Erlang 虚拟机可以通过标签的具体内容判断 Eterm 的类型,并且针对不同类型的 Eterm 采取不同的解释。给机器字“打标签”的意义实际上就是把机器字中的几个位“偷出来”当做标签使用,那么机器字中剩下的表示实际信息的位数就减少了,因此 Eterm 采用的标签方案必须简洁高效。
从前一节看出,Erlang 中有不少数据类型,而且有的数据类型还挺复杂,因此为了标签占用机器字中太多的位,Eterm 采用了层次化的标签方案。
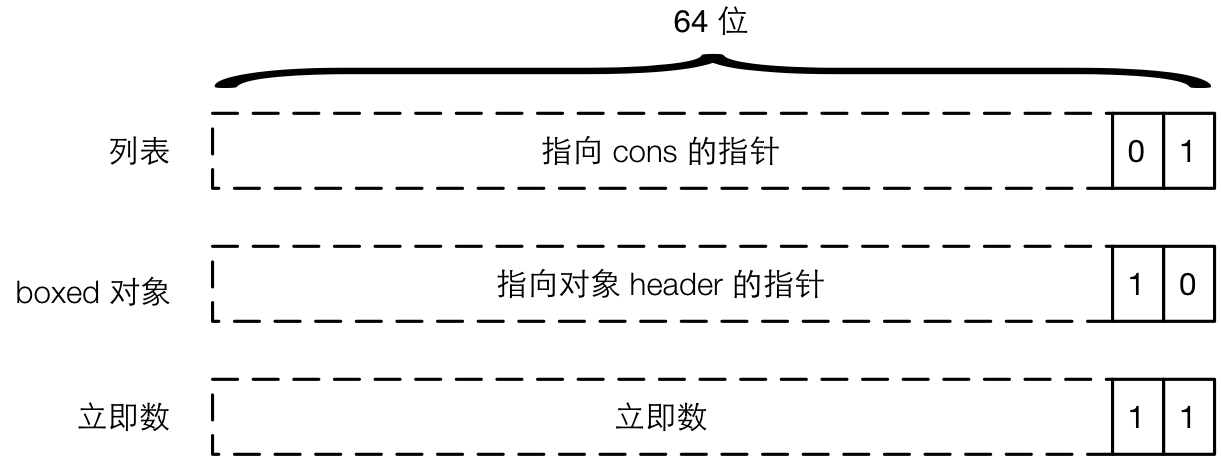
第一层次的标签叫做 primary tag,占用 Eterm 的最低两位,因此有 4 种组合:
- 01:表示一个列表,剩下的部分(62 位)是指向一个列表 cons 的指针。由于一个机器字是 64 位,所以 Eterm 必然采用 8 字节对齐,因而必然也是 4 字节对齐。而这里的指针只能指向一个 Eterm,所以借用 2 个位用作标签不会影响指针的精度,在使用的时候在后面填两个 0 就好了。
- 10:表示一个 boxed(“装箱”?)对象,即无法在一个机器字中表示的复杂对象。同样,剩下的部分是一个保留了高 62 位的指针,这个指针指向 boxed 对象的对象头(header),对象头的定义和对象的数据定义取决于具体的对象。
- 11:表示一个立即数(immediate)。立即数也就是能利用剩下的 62 个位编码的小型对象。
这 3 种主要的 Eterm 如下图所示:
下面先看最简单的 Eterm:立即数。
立即数
立即数在剩下的 62 个位中,又借了 2 个位作为标签用来区分立即数的类别:
- 0011:本地的 pid
- 0111:本地的 port
- 1011:另一类立即数(IMMED2),即在剩下的 60 个位中进一步打标签表示更小的立即数
- 1111:带符号的小整数。去掉符号位,还剩 59 位。
下面分别详细介绍这 4 类立即数。
pid
首先是本地 pid。在玩 Erlang 的时候,我们每时每刻都会见到 pid 的身影,比如说刚打开 Erlang 的 shell 时,调用 self() 就能看到当前 shell 进程的 pid,例如 <0.32.0>,看上去很高级的样子,用“.”分为好几段,还用尖括号括起来。如果只是随便玩玩,系统中进程不多,会发现好像只有中间那一段的数字会变,两边的数字总是 0,所以会觉得似乎两边的数字会用于什么神秘的用途。下面是表示 pid 的 Eterm 的结构:
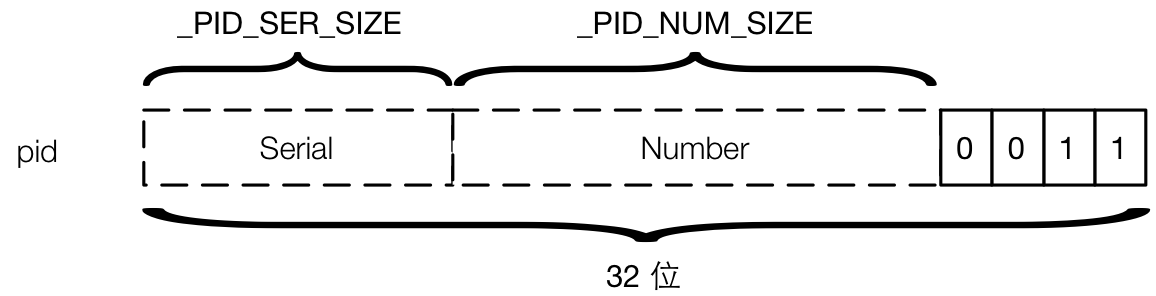
注意上图中 pid 的宽度是 32 位的,目前不论是在 64 位系统还是 32 位系统上,pid 的宽度都是 32 位,因此在 64 位系统上只用了 Eterm 的一半。最低 4 位是标签。然后在剩下的 28 位中,固定地分为两段了,一段是 Serial,一段是 Number。在 pid 的三段式表示法中,中间那一段是 Number,右边那一段是 Serial,也就是说,打印出来的 pid 人为地将一个 28 位的整数分成了两部分显示。目前在代码中将 Number 部分宽度定义为 15 位,剩下的 13 位是 Serial。由于 (2^{15} = 32768),所以当系统进程编号使用超过 32768 的时候,就会进位到 Serial 部分。所以在系统上不断地创建新进程,就可以看到下面这样的 pid 序列:

pid 的后面两段明了了,那么第一段是什么呢?在分布式 Erlang 的环境中,建立两个节点,如果在一个节点上把 pid 放在消息中发送至另外一个节点上的进程,在另一个节点上打印出这个 pid,就会发现第一段的数字变成了一个非零的值。没错,这个值就是和节点有关,具体意义见后。可是我们在上面的 pid Eterm 结构中并没有看到用于保存节点的空间,这是因为 pid 当做消息发送给远程节点之后,Erlang 的分布式机制会对 pid 做打包处理,外部节点收到之后会重组为表示“外部 pid”的新的 Eterm,这个 Eterm 就不是立即数了,变成了一个 boxed Eterm,具体详见后述。在本地节点,第一个段永远打印出 0。
要注意的是,Number 部分并不表示系统最大进程数的限制,Number 部分和 Serial 部分的长度是在编译的时候通过宏写死的。pid 最多有 28 个有效位,这些位构成的数据经过一定的变换可以成为进程表中的索引。进程表就是一个巨大的指针数组,每一个指针都指向一个进程的描述符,数组中包含的元素个数等于系统允许的最大进程数。目前默认最大进程数为 262144,也就是 18 位。最大进程数可以在启动的时候通过虚拟机参数 +P 设置。要注意,由于进程表是静态分配的,每一条 slot 都要占用 8 字节(实际上由于用空间换时间的优化,每一个进程的 slot 要占用 16 字节),所以最大进程数也不要太大了。Erlang 允许 pid 的这 28 位中最多拿出 27 位表示进程的索引,即最大允许(2^{27})个进程(实际上少一个),那么如果真地设置这么大的限值,进程表本身就要占用(2^{27} imes 2^3 imes 2 = 2GB)内存。
以前 pid 里面的高 28 位直接作为进程表的指针。在 R16B 引入了进程表多核访问相关的优化之后,为了避免多个调度器线程同时写入进程表时造成 cache 失效引发的性能降低,连续 pid 对应的指针在进程表中的 slot 中间都间隔了 cache 线。也就是说第一个进程的指针占用第一条 cache 线的第一个位置,第二个进程就跳到第二条 cache 线了。直到所有 cache 线都用完,再跳回第一条 cache 线中的第二个位置分配新的进程指针。因此采用了这种优化之后 pid 的数据值需要做简单的变换才能得到真正的进程表索引。
port
下图是表示 port 的 Eterm:
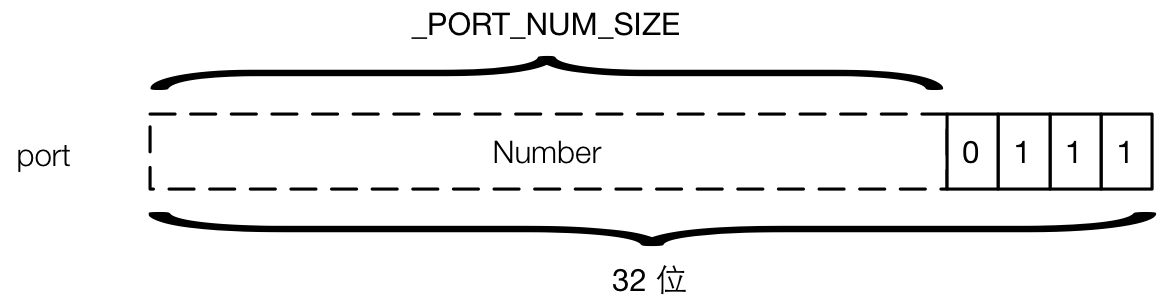
从图中可以看出,port 和 pid 差不多,也是 32 位,只是不区分 Serial 和 Number,整个有效位都作为 Number,所以我们打印 port 的时候得到的是像 #Port<0.52> 这样的结果,只分了两个段。第二个段就是 Number 的值。第一个段和 pid 是一样的,在本地永远打印出 0,发送到外部节点之后,会变成另一个 boxed Eterm。
Erlang 中 port 表的实现用的就是进程表的实现,即 erts/emulator/beam/erl_ptab.h 头文件中定义的 ErtsPTab 数据结构。因此各种限制和优化和进程表都是一样的。
带符号小整数
去掉 4 个标签位之后,还剩下 60 个位,系统可以用这 60 个位表示无符号整数或有符号整数,具体就看怎么用了。字节也是用这个类型表示的。如果在 Erlang 中使用字符串,尽管每一个字符只有一个字节,但是需要占用一个 CONS 一共 16 字节。在需要操作整数的时候,如果Erlang 编译器和虚拟机发现只需要不到 60 个位就能表示的时候,就会自动使用立即数,避免二次访问。
IMMED2
Erlang 里面立即数的类别不算少,但是也不好借太多位,借了太多位的话数据本身能用的位数就少了,所以 Erlang 采用了多级标签的方式,一些不需要那么多位的小数据类型,就放在 IMMED2 这一级了。IMMED2 立即数级别在 1011 的基础上进一步借了 2 位,分别表示 3 种数据类型:
- 001011:atom
- 011011:catch,用于表示 Erlang 中 catch 语句的代码的 Eterm,这个 Eterm 只会出现在进程的栈上。这个数据类型属于 Erlang 虚拟机内部使用的数据类型,Erlang 程序不会直接操作或使用这个数据类型。由于这个数据类型涉及到 Erlang 内部的 Beam 字节码以及虚拟机的执行机制,超出了本篇文章的范围,因此这里先不讨论(其实我自己也没有完全弄清楚虚拟机执行机制的所有细节,所以等具体弄懂之后再写关于 Beam 虚拟机执行机制相关的文章,在这些文章中一定会讨论 catch 的实现)。
- 111011:NIL,表示空指针。虽然 NIL 是打标签的值,但是 Erlang 虚拟机中还是专门定义了一个值表示 NIL,也就是除了这 6 位的标签之外其他位置全部填 1。
目前 IMMED2 这个层次下就只有上面这 3 种类型。catch 超出本文范围,NIL 很简单一句话说明白,下面就来详细谈一下 atom。在 Erlang 里 atom 真是抬头不见低头见,可以通过 atom 来表示各种意义的常量。在其他语言,例如C/C++中要实现类似的功能,我们可以使用 #define 宏定义,可以用 enum 枚举,还可以用 const 常量等方法。使用这些方法的时候,总会觉得不是太舒服,比如使用 #define 宏定义和 const 常量,除了本来就头痛的给宏或常量命名之外,还要真正填上一个值,为了让这些值不冲突,又是一件头痛的事情了。如果用字符串吧,那么每次匹配的时候还要做低效的字符串操作。
在 Erlang 中,使用 atom 既方便又高效,我们就来看看 atom 是怎么实现的。atom 的 Eterm 除去 6 位的标签之外剩下的部分,就是 atom 在 Erlang 虚拟机中的索引,也就是一个整数值。在 Erlang 中,有关 atom 比较的操作只需要比较两个索引值即可,就是整数操作,因此非常高效。atom 本身是一个字符串,那么 atom 的索引是怎样对应上具体的字符串的呢?也就是需要实现字符串和索引值之间的互相映射,字符串和索引值都必须唯一,这显然需要使用散列表。Erlang 虚拟机内实现了一套通用的索引和散列表机制,atom 表就是这个机制的一个客户。下图是这套机制中关键数据结构之间的关系。
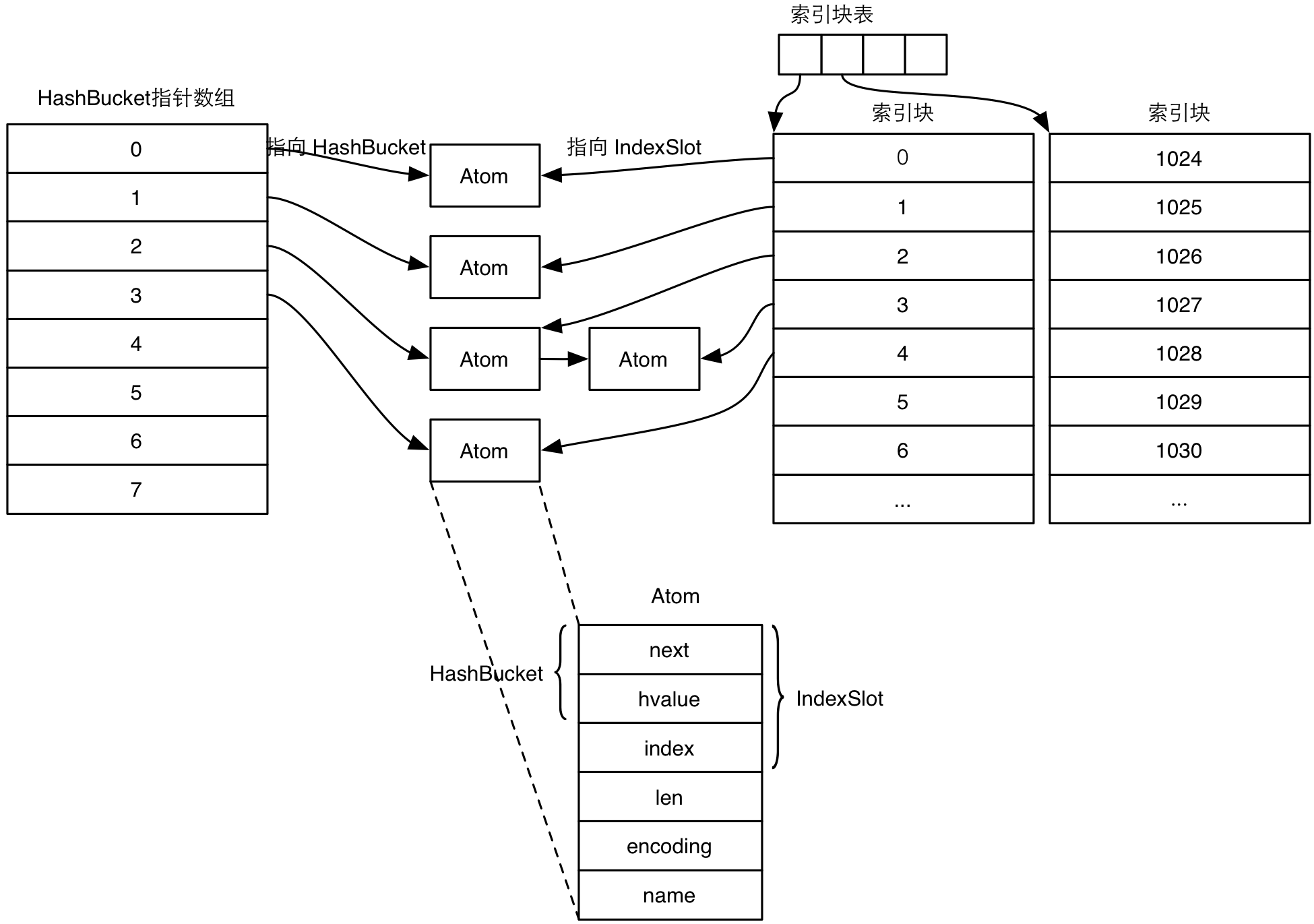
图中左侧是散列表部分,右侧是索引部分。先看左侧。这个散列表采用的是标准的数据结构教科书上的实现。查找的时候:通过散列函数计算被散列对象的散列值,然后对散列表的长度取模,得到图中左侧指针数组的索引,接下来运气好的话能直接得到查找的对象(封装在 HashBucket 中),运气不好的话可能查不到,或者发生碰撞进行线性搜索(例如图中通过散列值得到索引 2 的时候就发生了碰撞,需要线性搜索 HashBucket 中匹配的 hvalue)。插入的时候:同样是先计算散列值得到索引,然后看对应的指针是否已经有对象了,如果没有,则直接加入,如果有的话,则插入队列头部。散列表在扩容的时候,会选择下一个合适的大小(erts/emulator/beam/hash.c 文件中的 h_size_table 数组列出了散列表大小增长的序列,数组里面都是素数,但是基本上符合倍增的关系),把老表复制到新表,然后删除老表。当然,增长是有限制的,散列表大小不能超出 h_size_table 数组中指定的最大值。
图中右侧是索引部分。索引表实际上是指向被索引对象的指针的数组,被索引对象的索引值就是对应指针在数组中的自然顺序。由于事先无法确定具体的索引数目,所以索引表的大小是动态增长的,增长单位为一个索引块的大小,每个索引块中有固定数目的指针(例如 1024 个)。散列表中每插入一个新的对象的时候,设置索引表中最小的那个可用索引。如果新的索引超出了索引块的边界,那么分配一个新的索引块,并且更新索引块表中的指针。同样,索引表的增长也是有限度的,索引块表的指针用完了就不能再增长了。索引块表的长度是在创建索引表的时候设置的,所以理论上可以很大,不超出内存限制即可,但是实际中还要考虑散列表的大小,这两者是相互制约的。
描述了散列和索引的数据结构和实现之后,我们回到散列索引的客户——atom。由于散列和索引是通用的,所以散列表指向的对象是 HashBucket 数据结构,而索引表指向的是 IndexSlot 数据结构。为了将散列和索引结合起来,这两个数据结构是重叠的,HashBucket 在 IndexSlot 头部。具体客户在使用的时候,要把 IndexSlot 放在自己的头部,这样就把具体的对象和散列索引结合起来了(就好像原始的面向对象的实现)。 从图中可以看出,我们的 atom 数据结构除了上述结构之外,还包含了具体的字符串指针、长度以及编码信息。将这些信息串起来之后,我们就可以高效地在常量时间内查询 atom 是否已经存在,已经存在的 atom 的索引值是什么,某个索引值对应的 atom 是什么以及插入新的 atom。
另一个问题,向散列表插入元素的时候,散列表要负责分配对象的内存,而散列表是通用的,那么散列表怎么知道分配例如 atom 呢?解决方法是散列表中元素的分配、比较、释放以及散列值计算的操作都通过回调函数的方式提供给散列表。这里 atom 使用的散列函数是经典的 hashpjw 散列算法,这个算法是字符串散列常用的算法。
在一个 Erlang 节点内,atom 表是全局共享的,因此多个线程对 atom 表的访问是通过读写锁保护的。对 atom 表的操作绝大部分都是读操作,只有真正插入新的 atom 时的操作才是写操作,插入新 atom 的情况一般不频繁,而且也很少有多个线程争抢着插入新 atom 的情况,大部分情况都是试图插入 atom 但是发现其实已经存在了,因此 atom 表使用的读写锁是针对读操作优化的读写锁。使用针对读操作优化的读写锁时读锁的开销非常小,即使是在大量线程争用的情况下。
Erlang 中的 atom 表是不进行垃圾回收的,毕竟在程序员不滥用 atom 的情况下,atom 数目可以控制在合理范围内。而且跟踪每一个 atom 的引用状况会产生很大的开销。所以不要滥用 atom,把 atom 表塞满是把 Erlang 虚拟机 crash 掉的一种方法。目前默认的 atom 数目限制是 1048576((1024 imes 1024)),通过虚拟机的 +t 参数可以设置。
上面我们把 Erlang 中所有立即数都过了一遍,下面我们来看列表数据类型。
[注2] 在 64 位系统上,Erlang 虚拟机支持一种 hybrid heap(混合堆)模式。在这种模式中,混合使用 32 位宽的 term 和 64 位宽的 term,因为有一些数据类型的 term 并不需要 64 位宽,如果在 64 位系统下统一使用 64 位宽的 term,会造成一定程度的内存浪费。由于混合堆模式显然会使得虚拟机更复杂,因此属于一种实验性质的优化措施,默认是关闭的,本文也不讨论混合堆模式。