转自 http://blog.csdn.net/shagoo/article/details/6531950
上一篇《Socket深度探究4PHP(一)》中,大家应该对 poll/select/epoll/kqueue 这几个 IO 模型有了一定的了解,为了让大家更深入的理解 Socket 的技术内幕,在这个篇幅,我会对这几种模式做一个比较详细的分析和对比;另外,大家可能也同说过 AIO 的概念,这里也会做一个简单的介绍;最后我们会对两种主流异步模式 Reactor 和 Proactor 模式进行对比和讨论。
首先,然我们逐个介绍一下 2.6 内核(2.6.21.1)中的 poll/select/epoll/kqueue 这几个 IO 模型。
> POLL
先说说 poll,poll 和 select 为大部分 Unix/Linux 程序员所熟悉,这俩个东西原理类似,性能上也不存在明显差异,但 select 对所监控的文件描述符数量有限制,所以这里选用 poll 做说明。poll 是一个系统调用,其内核入口函数为 sys_poll,sys_poll 几乎不做任何处理直接调用 do_sys_poll,do_sys_poll 的执行过程可以分为三个部分:
1、将用户传入的 pollfd 数组拷贝到内核空间,因为拷贝操作和数组长度相关,时间上这是一个 O(n) 操作,这一步的代码在 do_sys_poll 中包括从函数开始到调用 do_poll 前的部分。
2、查询每个文件描述符对应设备的状态,如果该设备尚未就绪,则在该设备的等待队列中加入一项并继续查询下一设备的状态。查询完所有设备后如果没有一个设备就绪,这时则需要挂起当前进程等待,直到设备就绪或者超时,挂起操作是通过调用 schedule_timeout 执行的。设备就绪后进程被通知继续运行,这时再次遍历所有设备,以查找就绪设备。这一步因为两次遍历所有设备,时间复杂度也是 O(n),这里面不包括等待时间。相关代码在 do_poll 函数中。
3、将获得的数据传送到用户空间并执行释放内存和剥离等待队列等善后工作,向用户空间拷贝数据与剥离等待队列等操作的的时间复杂度同样是 O(n),具体代码包括 do_sys_poll 函数中调用 do_poll 后到结束的部分。
但是,即便通过 select() 或者 poll() 函数复用事件通知具有突出的优点,不过其他具有类似功能的函数实现也可以达到同样的性能。然而,这些实现在跨平台方面没有实现标准化。你必须在使用这些特定函数实现同丧失可移植性之间进行权衡。我们现在就讨论一下两个替代方法:Solaris 系统下的 /dev/poll 和 FreeBSD 系统下的 kqueue:
1、Solaris 系统下的 /dev/poll:在Solaris 7系统上,Sun引入了/dev/poll设备。在使用 /dev/poll的时候,你首先要打开/dev/poll作为一个普通文件。然后构造pollfd结构,方式同普通的poll()函数调用一样。这些 pollfd结构随后写入到打开的 /dev/poll 文件描述符。在打开句柄的生存周期内, /dev/poll会根据pollfd结构返回事件(注意,pollfd结构内的事件字段中的特定POLLREMOVE将从/dev/poll的列表中删除对应的fd)。通过调用特定的ioctl (DP_POLL) 和dvpoll,程序就可以从/dev/poll获得需要的信息。在使用dvpoll结构的情况下,发生的事件就可以被检测到了。
2、FreeBSD 系统下的 kqueue:在FreeBSD 4.1中推出。FreeBSD的kqueue API设计为比其他对应函数提供更为广泛的事件通知能力。kqueue API提供了一套通用过滤器,可以模仿poll()语法(EVFILT_READ和EVFILT_WRITE)。不过,它还实现了文件系统变化(EVFILT_VNODE)、进程状态变更(EVFILT_PROC)和信号交付(EVFILT_SIGNAL)的有关通知。
> EPOLL
接下来分析 epoll,与 poll/select 不同,epoll 不再是一个单独的系统调用,而是由 epoll_create/epoll_ctl/epoll_wait 三个系统调用组成,后面将会看到这样做的好处。先来看 sys_epoll_create(epoll_create对应的内核函数),这个函数主要是做一些准备工作,比如创建数据结构,初始化数据并最终返回一个文件描述符(表示新创建的虚拟 epoll 文件),这个操作可以认为是一个固定时间的操作。epoll 是做为一个虚拟文件系统来实现的,这样做至少有以下两个好处:
1、可以在内核里维护一些信息,这些信息在多次 epoll_wait 间是保持的,比如所有受监控的文件描述符。
2、epoll 本身也可以被 poll/epoll。
具体 epoll 的虚拟文件系统的实现和性能分析无关,不再赘述。
在 sys_epoll_create 中还能看到一个细节,就是 epoll_create 的参数 size 在现阶段是没有意义的,只要大于零就行。
接着是 sys_epoll_ctl(epoll_ctl对应的内核函数),需要明确的是每次调用 sys_epoll_ctl 只处理一个文件描述符,这里主要描述当 op 为 EPOLL_CTL_ADD 时的执行过程,sys_epoll_ctl 做一些安全性检查后进入 ep_insert,ep_insert 里将 ep_poll_callback 做为回掉函数加入设备的等待队列(假定这时设备尚未就绪),由于每次 poll_ctl 只操作一个文件描述符,因此也可以认为这是一个 O(1) 操作。ep_poll_callback 函数很关键,它在所等待的设备就绪后被系统回掉,执行两个操作:
1、将就绪设备加入就绪队列,这一步避免了像 poll 那样在设备就绪后再次轮询所有设备找就绪者,降低了时间复杂度,由 O(n) 到 O(1)。
2、唤醒虚拟的 epoll 文件。
最后是 sys_epoll_wait,这里实际执行操作的是 ep_poll 函数。该函数等待将进程自身插入虚拟 epoll 文件的等待队列,直到被唤醒(见上面 ep_poll_callback 函数描述),最后执行 ep_events_transfer 将结果拷贝到用户空间。由于只拷贝就绪设备信息,所以这里的拷贝是一个 O(1) 操作。
还有一个让人关心的问题就是 epoll 对 EPOLLET 的处理,即边沿触发的处理,粗略看代码就是把一部分水平触发模式下内核做的工作交给用户来处理,直觉上不会对性能有太大影响,感兴趣的朋友欢迎讨论。
> POLL/EPOLL 对比:
表面上 poll 的过程可以看作是由一次 epoll_create,若干次 epoll_ctl,一次 epoll_wait,一次 close 等系统调用构成,实际上 epoll 将 poll 分成若干部分实现的原因正是因为服务器软件中使用 poll 的特点(比如Web服务器):
1、需要同时 poll 大量文件描述符;
2、每次 poll 完成后就绪的文件描述符只占所有被 poll 的描述符的很少一部分。
3、前后多次 poll 调用对文件描述符数组(ufds)的修改只是很小;
传统的 poll 函数相当于每次调用都重起炉灶,从用户空间完整读入 ufds,完成后再次完全拷贝到用户空间,另外每次 poll 都需要对所有设备做至少做一次加入和删除等待队列操作,这些都是低效的原因。
epoll 将以上情况都细化考虑,不需要每次都完整读入输出 ufds,只需使用 epoll_ctl 调整其中一小部分,不需要每次 epoll_wait 都执行一次加入删除等待队列操作,另外改进后的机制使的不必在某个设备就绪后搜索整个设备数组进行查找,这些都能提高效率。另外最明显的一点,从用户的使用来说,使用 epoll 不必每次都轮询所有返回结果已找出其中的就绪部分,O(n) 变 O(1),对性能也提高不少。
此外这里还发现一点,是不是将 epoll_ctl 改成一次可以处理多个 fd(像 semctl 那样)会提高些许性能呢?特别是在假设系统调用比较耗时的基础上。不过关于系统调用的耗时问题还会在以后分析。
> POLL/EPOLL 测试数据对比:
测试的环境:我写了三段代码来分别模拟服务器,活动的客户端,僵死的客户端,服务器运行于一个自编译的标准 2.6.11 内核系统上,硬件为 PIII933,两个客户端各自运行在另外的 PC 上,这两台PC比服务器的硬件性能要好,主要是保证能轻易让服务器满载,三台机器间使用一个100M交换机连接。
服务器接受并poll所有连接,如果有request到达则回复一个response,然后继续poll。
活动的客户端(Active Client)模拟若干并发的活动连接,这些连接不间断的发送请求接受回复。
僵死的客户端(zombie)模拟一些只连接但不发送请求的客户端,其目的只是占用服务器的poll描述符资源。
测试过程:保持10个并发活动连接,不断的调整僵并发连接数,记录在不同比例下使用 poll 与 epoll 的性能差别。僵死并发连接数根据比例分别是:0,10,20,40,80,160,320,640,1280,2560,5120,10240。
下图中横轴表示僵死并发连接与活动并发连接之比,纵轴表示完成 40000 次请求回复所花费的时间,以秒为单位。红色线条表示 poll 数据,绿色表示 epoll 数据。可以看出,poll 在所监控的文件描述符数量增加时,其耗时呈线性增长,而 epoll 则维持了一个平稳的状态,几乎不受描述符个数影响。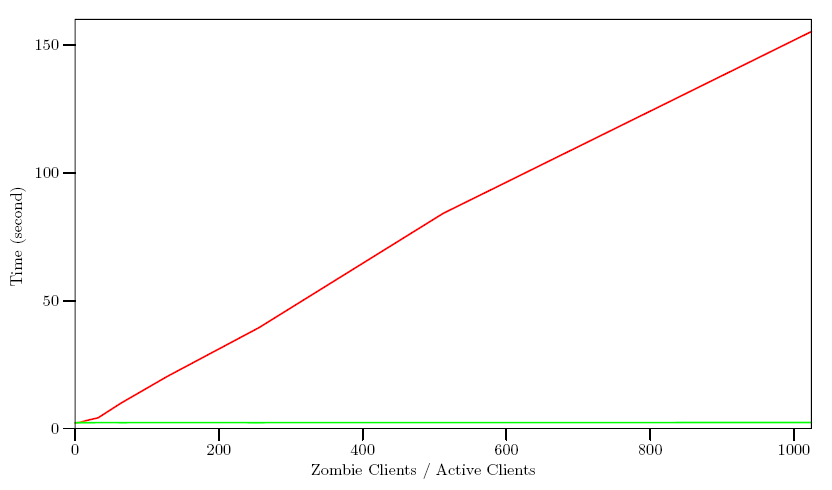
但是要注意的是在监控的所有客户端都是活动时,poll 的效率会略高于 epoll(主要在原点附近,即僵死并发连接为0时,图上不易看出来),究竟 epoll 实现比 poll 复杂,监控少量描述符并非它的长处。
> epoll 的优点综述
1、支持一个进程打开大数目的socket描述符(FD):select 最不能忍受的是一个进程所打开的 FD 是有一定限制的,由 FD_SETSIZE 设置,在 Linux 中,这个值是 1024。对于那些需要支持的上万连接数目的网络服务器来说显然太少了。这时候你一是可以选择修改这个宏然后重新编译内核,不过资料也同时指出这样会带来网络效率的下降,二是可以选择多进程的解决方案(传统的 Apache 方案),不过虽然 linux 上面创建进程的代价比较小,但仍旧是不可忽视的,加上进程间数据同步远比不上线程间同步的高效,所以也不是一种完美的方案。不过 epoll 则没有这个限制,它所支持的 FD 上限是最大可以打开文件的数目,这个数字一般远大于 1024,举个例子,在 1GB 内存的机器上大约是 10 万左右,具体数目可以 cat /proc/sys/fs/file-max 察看,一般来说这个数目和系统内存关系很大。
2、IO 效率不随 FD 数目增加而线性下降:传统的 select/poll 另一个致命弱点就是当你拥有一个很大的 socket 集合,不过由于网络延时,任一时间只有部分的 socket 是"活跃"的,但是 select/poll 每次调用都会线性扫描全部的集合,导致效率呈现线性下降。但是 epoll 不存在这个问题,它只会对"活跃"的 socket 进行操作---这是因为在内核实现中 epoll 是根据每个 fd 上面的 callback 函数实现的。那么,只有"活跃"的 socket 才会主动的去调用 callback 函数,其他 idle 状态 socket 则不会,在这点上,epoll 实现了一个"伪"AIO,因为这时候推动力在 os 内核。在一些 benchmark 中,如果所有的 socket 基本上都是活跃的 --- 比如一个高速LAN环境,epoll 并不比 select/poll 有什么效率,相反,如果过多使用 epoll_ctl,效率相比还有稍微的下降。但是一旦使用 idle connections 模拟 WAN 环境,epoll 的效率就远在 select/poll 之上了。
3、使用 mmap 加速内核与用户空间的消息传递:这点实际上涉及到 epoll 的具体实现了。无论是 select,poll 还是 epoll 都需要内核把 FD 消息通知给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll 是通过内核于用户空间 mmap 同一块内存实现的。而如果你想我一样从 2.5 内核就关注 epoll 的话,一定不会忘记手工 mmap 这一步的。
4、内核微调:这一点其实不算 epoll 的优点了,而是整个 linux 平台的优点。也许你可以怀疑 linux 平台,但是你无法回避 linux 平台赋予你微调内核的能力。比如,内核 TCP/IP 协议栈使用内存池管理 sk_buff 结构,那么可以在运行时期动态调整这个内存 pool(skb_head_pool) 的大小 --- 通过 echo XXXX > /proc/sys/net/core/hot_list_length 完成。再比如 listen 函数的第 2 个参数(TCP 完成 3 次握手的数据包队列长度),也可以根据你平台内存大小动态调整。更甚至在一个数据包面数目巨大但同时每个数据包本身大小却很小的特殊系统上尝试最新的 NAPI 网卡驱动架构。
> AIO 和 Epoll
epoll 和 aio(这里的aio是指linux 2.6内核后提供的aio api)的区别:
1、aio 是异步非阻塞的。其实是aio是用线程池实现了异步IO。
2、epoll 在这方面的定义上有点复杂,首先 epoll 的 fd 集里面每一个 fd 都是非阻塞的,但是 epoll(包括 select/poll)在调用时阻塞等待 fd 可用,然后 epoll 只是一个异步通知机制,只是在 fd 可用时通知你,并没有做任何 IO 操作,所以不是传统的异步。
在这方面,Windows 无疑是前行者,当然 Boost C++ 库已经实现了 linux 下 aio 的机制,有兴趣的朋友可以参考:http://stlchina.huhoo.NET/twiki/bin/view.pl/Main/WebHome
> Reactor 和 Proactor
一般地,I/O多路复用机制都依赖于一个事件多路分离器(Event Demultiplexer)。分离器对象可将来自事件源的I/O事件分离出来,并分发到对应的read/write事件处理器(Event Handler)。开发人员预先注册需要处理的事件及其事件处理器(或回调函数);事件分离器负责将请求事件传递给事件处理器。两个与事件分离器有关的模式是Reactor和Proactor。Reactor模式采用同步IO,而Proactor采用异步IO。
在Reactor中,事件分离器负责等待文件描述符或socket为读写操作准备就绪,然后将就绪事件传递给对应的处理器,最后由处理器负责完成实际的读写工作。而在Proactor模式中,处理器--或者兼任处理器的事件分离器,只负责发起异步读写操作。IO操作本身由操作系统来完成。传递给操作系统的参数需要包括用户定义的数据缓冲区地址和数据大小,操作系统才能从中得到写出操作所需数据,或写入从socket读到的数据。事件分离器捕获IO操作完成事件,然后将事件传递给对应处理器。比如,在windows上,处理器发起一个异步IO操作,再由事件分离器等待IOCompletion事件。典型的异步模式实现,都建立在操作系统支持异步API的基础之上,我们将这种实现称为“系统级”异步或“真”异步,因为应用程序完全依赖操作系统执行真正的IO工作。
举个例子,将有助于理解Reactor与Proactor二者的差异,以读操作为例(类操作类似)。
在Reactor中实现读:
- 注册读就绪事件和相应的事件处理器
- 事件分离器等待事件
- 事件到来,激活分离器,分离器调用事件对应的处理器。
- 事件处理器完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。
与如下Proactor(真异步)中的读过程比较:
- 处理器发起异步读操作(注意:操作系统必须支持异步IO)。在这种情况下,处理器无视IO就绪事件,它关注的是完成事件。
- 事件分离器等待操作完成事件
- 在分离器等待过程中,操作系统利用并行的内核线程执行实际的读操作,并将结果数据存入用户自定义缓冲区,最后通知事件分离器读操作完成。
- 事件分离器呼唤处理器。
- 事件处理器处理用户自定义缓冲区中的数据,然后启动一个新的异步操作,并将控制权返回事件分离器。
对于不提供异步 IO API 的操作系统来说,这种办法可以隐藏 Socket API 的交互细节,从而对外暴露一个完整的异步接口。借此,我们就可以进一步构建完全可移植的,平台无关的,有通用对外接口的解决方案。上述方案已经由Terabit P/L公司实现为 TProactor (ACE compatible Proactor) :http://www.terabit.com.au/solutions.PHP。正是因为 linux 对 aio 支持的不完整,所以 ACE_Proactor 框架在 linux 上的表现很差,大部分在 windows 上执行正常的代码,在 linux 则运行异常,甚至不能编译通过。这个问题一直困扰着很大多数 ACE 的用户,现在好了,有一个 TProactor 帮助解决了在 Linux 不完整支持 AIO 的条件下,正常使用(至少是看起来正常)ACE_Proactor。TProactor 有两个版本:C++ 和 Java 的。C++ 版本采用 ACE 跨平台底层类开发,为所有平台提供了通用统一的主动式异步接口。Boost.Asio 库,也是采取了类似的这种方案来实现统一的 IO 异步接口。
以下是一张 TProactor 架构设计图,有兴趣的朋友可以看看:
到这里,第二部分的内容结束了,相信大家对 Socket 的底层技术原理有了一个更深层次的理解,在下一篇《Socket深度探究4PHP(三)》我将会深入 PHP 源代码,探究一下 PHP 在 Socket 这部分的一些技术内幕,然后介绍一下目前在这个领域比较活跃的项目(Node.js)。