0. 原作
论文:XMP-Font: Self-Supervised Cross-Modality Pre-training for Few-Shot Font Generation
代码:https://github.com/lfy523/XMP-Font (截止发文时还未公开代码,仅有仓库)
1. 摘要
现存的方法都遵循风格内容解耦范式,新字体由目标风格和源字体的内容构成。
但这种小样本的方法无法捕捉内容独立的风格表征,或是利用局部组件(比笔画高一级、构成整个字的成分)
层级的风格表征,这不足以建模含有超组件特征的汉字风格,比如组件间间隔(如偏旁跟主体的远近)和连笔
为了解决上述缺陷并且使得风格表征更加可靠,本文提出了一种自监督跨模态预训练的策略,以及一种基于
跨模态transformer的编码器,以字形图像和对应笔画标签训练。
该编码器以自监督方式预训练,有效地捕捉模态间和模态内的关联,这用到内容风格解耦并且在所有尺度上
建模了风格表征(笔画级、组件级和字符级)。
随后该编码器被用于下游字体生成任务,无需微调。实验显示本方法成功迁移了所有尺度的风格,
并且仅需一个参考字就能够在少样本字体生成任务取得最低的错误率(比第二名低了28%)
2. 引言

提到本文属于一个少样本字体生成任务(few-shot font generation task (FFG)),仅用少许参考字形且无需再次微调模型。
当目标语言的字库很大(中文超过80000个字)或者难以取得许多目标字形(历史上的古字)
(这些引言几乎是对摘要的扩充)
用卷积编码器直接抽取的风格不够可靠,也不独立于内容,因为对字形结构和字不同区域的关注有限
比较先进的架构如DM-Font, LF-Font, MX-Font,试图使用关注结构的风格表达,学习组件级的风格。它们联合建模字形图像和相应的组件标签,或引入组件标签指导的损失来训练编码器。
这极大地改进了风格表示的可靠性,但仅仅学习组件间风格还不足以处理多组件的字形,如汉字,有着超过200种不同类型的组件,难以在测试的时候用少许参考字形就覆盖所有组件。
为了缓解这个问题,LF-Font简化了组件间风格,思想类似低阶矩阵分解。MX-Font抽取多种风格特征,它们并非显式地建立于组件标签上,而是由多个专家自动地表示不同的局部概念,因此允许模型泛化到未知组件结构的字上。
但这种方法在使用见过的组件泛化未知组件时容易产生不好的样本(bad cases),另一方面组件间的风格无法捕捉字符级的的风格特征(组件间距离, inter-component spacing),这在许多汉字字库中都是重要的方面。
本文提出了两个重要的改变来解决这些问题:
- 使用笔画标签代替组件标签作为字结构的原子表达。因为汉字的笔画集只有约28种,比组件少多了,更好用少许参考字形覆盖,或是从已知笔画来泛化。
- 使用统一多尺度风格表达。用提到的那个跨模态transformer编码器做到,从而兼顾笔画、组件和字符级风格
- 自注意力层利于捕捉局部和全局风格特征
- 跨模态编码器的自监督预训练有助于学习字形-笔画对齐,进一步促进了下游训练阶段多尺度下的内容风格解缠和风格表征建模
- 基于LSTM的笔画损失跟风格内容解耦网络,考虑空间信息转换,用于增强模型可靠性。
(拿出差不多的字数把上面的总结了一下)
提到上面3的风格内容解耦由通道注意力模块构成,并利用8x8的特征图而不是简单平均池化向量来表达风格内容,以期保留空间信息。同时笔画损失基于LSTM是为了有正确的笔画顺序,而不是存在就可以,对于连笔这种笔画顺序相关的风格特征很有帮助。
[注]:通道注意力,Efficient Channel Attention (ECA),来自《ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks》,是一种用于提高深度CNNs性能的超轻量级注意模块
3. 相关任务
3.1. 图像翻译
Image-to-image translation
如StarGANv2,用一个统一框架学习多个域之间的图像翻译。FUNIT则希望将图片转换到给定的风格,同时保留内容,并且无需微调模型,这可以用于FFG字体生成任务。
这篇论文与StarGANv2比已知字体域的字形生成,跟FUNIT同时比已知跟未知的情况。
[注]:FUNIT,Few-Shot Unsupervised Image-to-Image Translation
3.2. 多样本字体生成
早期方法再各个字体间两两训练跨模态翻译器。一些方法先训练一个翻译模型,再根据许多目标风格的参考字形去微调,如Scfont: Structure-guided chinese font generation via deep stacked networks,微调需要几百个目标字形。
3.3. 跨模态预训练
跨模态预训练常用于视觉语言任务:image-text matching, visual question answering, image captioning等等。学习视觉语言联系的框架被引入字形-笔画关联的学习,以期增加风格编码的结构关注。整了个transformer模型,由三个编码器组成:字形处理模块、笔画处理编码器和跨膜态模块。
接着,用大量字形-笔画对,通过自监督信号(重建输入数据)来预训练模型。该任务有助于学习模态间和跨模态的关系。
4. 方法
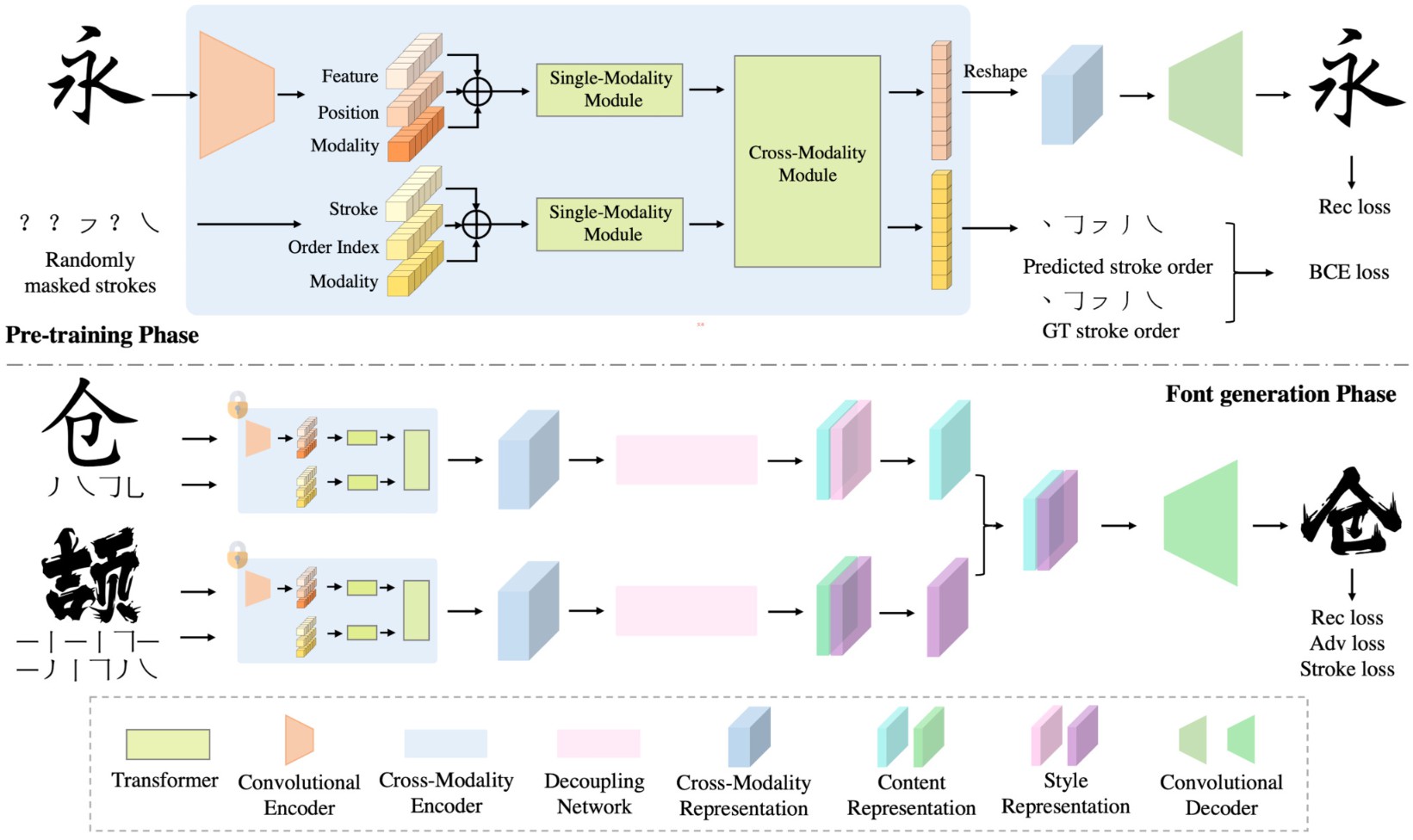
4.1. 总流水线
如图2所示,编码器以两个模态为输入:某一风格的字形图片和表示相应字形结构的笔画标签序列。首先用单一模态模块分别处理二者,然后再用跨模态模块结合。预训练时,编码器后面接一个卷积解码器和笔画标签预测器(重建输入)
之后冻住跨模态编码器然后用于下游任务,此时遵循风格-内容解码范式,并且合成新字体...逼逼赖赖第三遍
编码器后接一个解耦网络,将风格内容表达区分开,再接卷积解码器去结合源字体的内容跟新风格...
4.2. 跨模态编码器
对图2的编码器看图说话
输入嵌入单元
该单元把输入数据转换为两个分开的嵌入序列(字形嵌入跟笔画嵌入),笔画序列由28个笔画嵌入组成,按书写顺序排列。28是常见汉字最多的笔画数,每个笔画都是确定的,因为会基于空间坐标来排列,如从左到右或者从上到下。而且笔画顺序包含空间信息,有利于结构变形跟连笔的生成。
行楷中经常改变字形结构,捺变成点,两横连成3的形状,不知道能否处理
每个笔画嵌入都是三种嵌入的总和:笔画标签嵌入、位置嵌入跟模态类型嵌入。标签嵌入512维,通过嵌入子层从笔画标签映射过来。而笔画的位置索引(从0到29)投影到512维的位置嵌入,模态标签(0表示笔画,1表示字形图像)投影到512维模态类别嵌入。描述得真jb啰嗦。因此对于笔画模态,得到一个长度为30的嵌入序列??(30-embedding sequence)
另一方面输入字形图像256x256x3用5层的卷积编码器映射到8x8x512的特征图。特征图再进一步拉平到一个64 512维的嵌入(64 512-d embeddings)序列,讲的什么jb。
其中每个嵌入都与特定的空间坐标相对应。类似地,每个空间坐标的位置嵌入跟模态类别嵌入都各自从x-y坐标和模态类别映射而来。字形嵌入由位置嵌入、模态类别嵌入和特征嵌入组成,因此最终字形模态的嵌入序列为64维??( a 64-embedding sequence )。提到位置信息的结合对后面用到的transformer层很重要。
自-跨模态层
对着图2编码器中single-modality跟cross-modality module看图说话,提到笔画信息由9个BERT层,字形信息由5个BERT层处理
每个cross-modality module种的cross-modality层由两个自注意力子层、一个双向跨注意力子层和两个前馈子层构成,同时堆叠多个这种cross-modality层。
双向跨注意力子层包含两个单向跨注意力子层:笔画-字形跟字形-笔画,它用于交换两个模态的信息并对齐实体,以便于学习联合跨模态表达。
跨注意力子层(应该是指单向的那两个)后面还有一个自注意力子层,用于进一步建立内部联系。
每个字层后还加了残差连接跟层正则化
bb一大堆就是不画一张图
4.3. 预训练策略
训练中以0.375的概率将所有输入笔画标签遮掩,其他情况则每个笔画有0.5的概率被遮掩。在编码器后面加一个两层全连接的笔画预测头。笔画模态的嵌入序列直接映射到笔画标签。除了从未遮掩的笔画预测遮掩笔画(挺困难的,完全有多种可能),同时也从字形预测遮掩笔画,以便解决歧义。这就建立了字形模态到笔画模态的联系,该任务称为笔画重建任务,使用交叉熵损失。
并且编码器后面还接了个卷积解码器,希望重建自字形图像,将64长度的字形嵌入序列变为8x8的特征图,然后解码为图像,使用L1损失。
数据集来自于方正字库,数据量很大并且有对齐的字形-笔画对。预训练阶段从头训练所有参数,采用xavier initialization,用到字形重建损失跟笔画分类损失(应该是上述那两个),二者权重相同。采用Adam优化器,学习率线性衰减,峰值在 1e-4,batchsize为4,训练了30个epochs,大约 4,000,000 个optimization steps。
\(L^{pre} = \sum^{L}_{i=1}BCE(\hat{s_i}, s_i) + |\hat{I} − I|\)
I表示图像,s表示笔画标签,加hat的是真值
4.4. 小样本字体生成的下游任务
上述的编码器有点像自编码器,重建两个输入,最终学会将输入变为一个特征向量。
经过预训练,冻结编码器,然后接一个解耦网络,该网络由4个ECA模块构成,自适应地缩放通道维度的特征,能够解耦风格与内容表达。
解耦网络的输出是8x8x512的特征图,分成两个8x8x256的,分别作为风格与内容,如此便能够用源字体的内容去结合目标字体风格生成新字体,这边听起来倒是熟悉的味道。这里用8x8的特征图而不是向量是为了保留更丰富的空间信息。
本阶段从对齐字形-笔画数据集中取用30种字体,每种字体取6741个字,这些都是预训练用到的。
一共三种损失:对抗损失、重建损失和笔画损失。
- 对抗损失,使用判别器区分生成的字形跟真实的字形
- 重建损失,生成字形跟真值(源字体的内容但具有目标风格的字形),L1损失
- 笔画损失,用一个LSTM的笔画预测器,输入字形按顺序输出对应笔画,根据倒数第二个?(second last)LSTM激活值计算生成字形跟真值字形之间的特征差异作为损失,本质也是L1损失
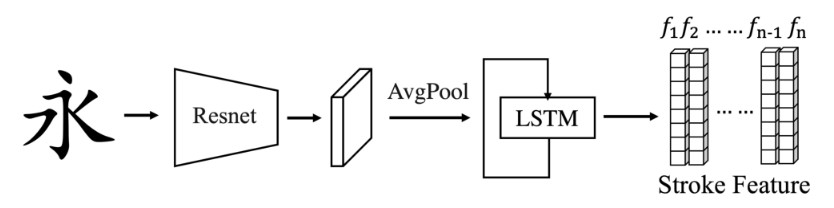
这三种损失权值一致,使用Adam优化器,学习率同样是线性衰减,峰值为1e-4,batchsize为4,训练了30个epochs,大约 5,000,000 个optimization steps。
\(L_{fg} = Loss_{adv} + |\hat{I} − I| + |LSTM(\hat{I}) − LSTM(I)|\)
I表示图像,加hat的是真值,\(Loss_{adv}\)跟WGAN-GP的一样
5. 实验结果
Pytorch1.7,用的是 Tesla V100,预训练任务花了2-3天,第二阶段训练花了6天,如此看来训练花费也是相当大。
跟5中FFG方法对比,还在FFG benchmark测试,效果很好,还做了消融实验
5.1. 对比
跟两种图像翻译方法StarGAN v2、FUNIT以及三种FFG方法LF-Font, MX-Font和DG-Font作对比
StarGAN v2、FUNIT也能用于翻译两个未知的域
将FFG模型在100种字体域上进行训练,仅适用一个字形图像作为参考去评估模型在已知与未知风格上面的效果。由于笔画标签独立于风格,这里6471个字的笔画标签都直接给定。
字体风格多种多样,当 multiple “ground-truths” are satisfying and only one “ground-truth” glyph is present in the evaluation dataset 时就会引发问题,突然就satisfy,莫名其妙
提到除了基于真值ground-truth的评价指标(SSIM,PSNR和L1),还使用不要求配对ground-truth的指标,比如FID。
好像是说SSIM,PSNR和L1这些方法需要跟生成的字形匹配的真值,可能是同一个字同一个风格,但是字体风格多样,会有问题,因此也用FID这种不要求配对的指标
除了客观标准,还做了用户调查,让参与者挑出成功的风格迁移并具有正确字形结构的结果。已知未知的字体随机各挑10种,每个模型再对每种生成30个字,一共3300个样本(10x30x6个已知,10x30x5个未知,因为StarGANv2无法处理未知域)
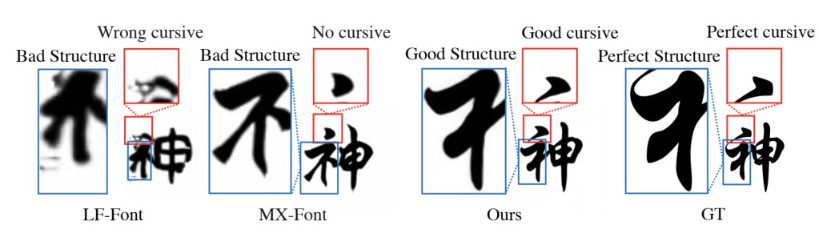
展示了生成样本,FUNIT的最差,出现字形结构的缺失...总之本文的方法是最好的

5.2. 消融研究
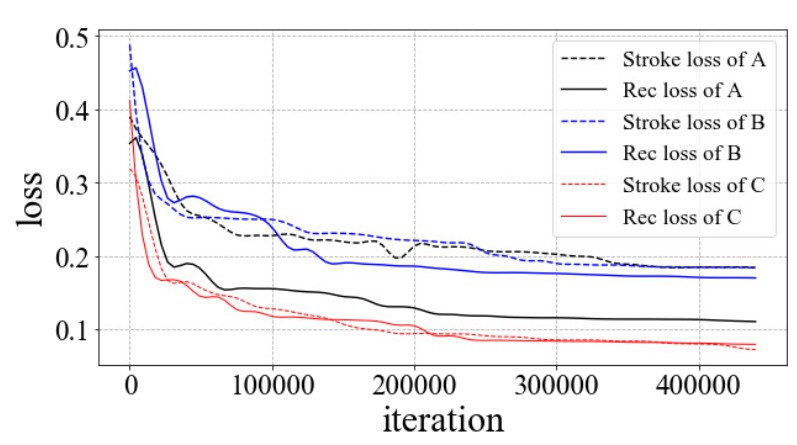
三个实验验证预训练策略:
- A, 跨模态编码器不进行预训练,跟下游任务同时从头开始训练
- B, 预训练编码器,但在第二阶段时不冻结,而是以微小的学习率(1e-6)进行微调
- C, 本文用的预训练并且冻结编码器的做法
下图展示了验证损失(笔画损失跟重建损失),能看出来A, B方法不如C的收敛
三个实验验证笔画损失跟架构设计:
- A, 在第二阶段训练时去掉笔画损失;会导致字形结构缺失
- B, 把字形特征图从8x8改为4x4,通过在8x8特征图后面再加个卷积下采样实现;导致细粒度结构信息丧失,提到虽然尺寸大点好但是16x16会爆显存,就选择8x8的
- C, 将解耦网络里的ECA模块换成简单的卷积层;导致难以解耦内容风格,并且出现了结构缺失

6. 总结
提出了XMP-Font这么个模型处理小样本字体生成任务,效果很好
缺点是不支持未知的笔画标签,因为风格内容表达都基于笔画标签,因此无法用于一些未知语言,它们的字符由不同的笔画构成