摘自Apache Flink官网
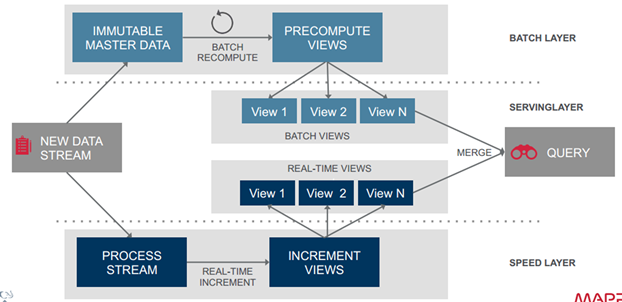
最早的streaming 架构是storm的lambda架构
分为三个layer
- batch layer
- serving layer
- speed layer
一、在streaming中Flink支持的通知时间
Flink官网写了个了解streaming和各种时间的博客
https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101#F2
1、Processing time:执行时候的机器系统时间。
- 如果使用时间窗口的话,如果一个应用在9:15开始,那么第一次的结束时间在10:00. 然后是10:00~11:00, 之后都是整点。就第一个点比较特殊
2、Event time:每一个Event在其设备上产生的时间,是在进入Flink之前的时间。
- 可以从data里面提取出来
- Event time的程序必须声明怎么产生Event Time Watermarks。
- Event time处理会发生延时,因为有可能有的Event没有到达
- 如果所有的events都到达了,那么event time operations会按照预期的执行
3、Ingestion time:events进入Flink的时间
- 在source算子,每一个记录得到当前算子的时间,基于时间的操作根据这个时间。
- 记录时间有点开销,因为是在source上,但是非常可靠。因为如果是processing time的话,有可能机器的local time不一样
- Ingestion time和event time不一样,这个不能处理过期时间
4、watermark:在Flink中Event time程序衡量执行的是watermarks
- watermark携带了时间戳
- watermark在source function之后产生
- 每一个并行的子任务独立的产生watermarks
- 可以设置迟到时间,来容忍迟到的watermak
注册watermark的代码:
1 public static class BoundedOutOfOrdernessGenerator implements AssignerWithPeriodicWatermarks<OrderRecord> { 2 private final long maxOutOfOrderness = 3500; // 3.5 seconds 3 4 private long currentMaxTimestamp; 5 6 @Override 7 public long extractTimestamp(OrderRecord record, long previousElementTimestamp) { // 将数据中的时间戳字段(long 类型,精确到毫秒)赋给 timestamp 变量,此处是 OrderRecord 的 timestamp 字段 8 long timestamp = record.timestamp; 9 currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp); 10 return timestamp; 11 } 12 13 @Override 14 public Watermark getCurrentWatermark() { // return the watermark as current highest timestamp minus the out-of-orderness bound 15 return new Watermark(currentMaxTimestamp - maxOutOfOrderness); 16 } 17 }
5、Late Elements:迟到元素。即使在watermark(k)已经产生了之后,仍然有迟到元素
- 设置很长的延迟时间不太实际
- 默认上Late Elements是drop掉的
- Flink支持allowedLateness,在被drop前可以容忍的最大延迟时间
- 如果设置了allowedLateness,当迟到元素到达的时候,会再计算一遍窗口
- 也可以设置side output将废弃的数据当成side output
6、idling sources: 在一段时间内,watermark没有到来,窗口内的元素就不执行,这就是idling sources
二、生成TimeStamps / Watermarks
1、指派timestamps
这部分通常在实例中的一些filed内进行accessing/extracting the timestamp。
2、生成timestamps 和 watermark的方法
- Directly in the data source.
- 通过watermark 和 timestamp generator
3、在source下生成timestamps和watermark
- 需要使用collectWithTimestamp方法在SourceContext下面
- watermark需要使用emitWatermark
如果使用了generator那么source生成的watermark和timestamp会被复写
Java Code:
1 final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); 2 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); 3 4 DataStream<MyEvent> stream = env.readFile( 5 myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100, 6 FilePathFilter.createDefaultFilter(), typeInfo); 7 8 DataStream<MyEvent> withTimestampsAndWatermarks = stream 9 .filter( event -> event.severity() == WARNING ) 10 .assignTimestampsAndWatermarks(new MyTimestampsAndWatermarks()); 11 12 withTimestampsAndWatermarks 13 .keyBy( (event) -> event.getGroup() ) 14 .timeWindow(Time.seconds(10)) 15 .reduce( (a, b) -> a.add(b) ) 16 .addSink(...);
三、预定义的TimeStamp Extractor和Watermark Emmiter
1、最简单的watermark generator
如果并行数据是升序的,那么最简单的方法是使用 AscendingTimestampExtractor。即便是kafka消息源,如果每个partition的消息是升序的,那么在shuffle阶段,会把每个partition的watermark正确的进行shuffle。
1 DataStream<MyEvent> stream = ... 2 3 DataStream<MyEvent> withTimestampsAndWatermarks = 4 stream.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<MyEvent>() { 5 6 @Override 7 public long extractAscendingTimestamp(MyEvent element) { 8 return element.getCreationTime(); 9 } 10 });
2、允许延迟的watermark
可以设定固定的延时时间,延迟=迟到时间戳 - 上一个元素的watermark。如果延迟 > lateness,会被忽略。
1 DataStream<MyEvent> stream = ... 2 3 DataStream<MyEvent> withTimestampsAndWatermarks = 4 stream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<MyEvent>(Time.seconds(10)) { 5 6 @Override 7 public long extractTimestamp(MyEvent element) { 8 return element.getCreationTime(); 9 } 10 });