单线程的Redis为何还能这么快?
1、所有的数据都在内存中,所有的运算都是内存级别的运算
(内存内的操作不会因为磁盘IO速度限制,因此不会成为性能瓶颈)
2、简单高效的数据结构,对数据操作也简单,Redis中的数据结构是专门进行设计的
3、单线程操作,避免了频繁的上下文切换带来的资源消耗问题,也无需关心锁,更不会因为死锁导致的性能消耗
(正因为是单线程,因此时间复杂度为O(n)的指令要谨慎使用,一不小心就会造成卡顿)
4、多路IO复用,非阻塞IO(NIO)来处理 客户端的并发连接
(可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗))
IO多路复用,非阻塞IO:
1)非阻塞IO,Non-block IO, NIO,非阻塞模式,使一个线程从某通道发送请求数据读取数据,如果目前没有数据可读时,就什么都不会获取,而不是保持线程阻塞,直到有数据可读之前,该线程可以继续做别的事情。
非阻塞写也是如此,能写多少取决于内核为套接字分配的写缓冲区的空闲字节数,不必等到完全写入这个线程可以去做别的事情。线程通常将非阻塞IO的空闲时间用于在其他通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
阻塞IO,BIO,如Java IO中的各种流都是BIO,阻塞的。当一个线程调用read或者write方法时,该线程会被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干别的事情了。
2)多路IO复用(事件轮询)
多路指的是多个socket网络连接,复用指的是复用同一个线程
多路复用主要有三种技术:select、poll、epoll。epoll是最新的也是最好的多路复用技术
它的基本原理是,内核不是监控应用程序本身的连接,而是监视应用程序的文件描述符(fd),而每个socket连接和IO都对应一个fd。
内核为每个socket连接请求、IO读写都分配一个文件描述符fd(一个非负整数,是指向内核为该进程维护的打开文件的记录表(记录详细的文件描述信息)的索引),Redis底层通过调用epoll函数获取该进程下就绪的socket连接或IO请求,然后交给Redis的单线程去处理。就实现了单线程的Redis能同时处理多个socket和IO流的效果。
简单来说:Redis单线程情况下,内核会一直监听socket上的连接请求或者数据请求,一旦有请求到达就交给Redis线程处理,这就实现了一个Redis线程处理多个IO流的效果。
select/epoll 提供了基于事件的回调机制,即针对不同事件的发生,调用相应的事件处理器。所以 Redis 一直在处理事件,提升 Redis 的响应性能。
Redis 线程不会阻塞在某一个特定的监听或已连接套接字上,也就是说,不会阻塞在某一个特定的客户端请求处理上。正因为此,Redis 可以同时和多个客户端连接并处理请求,从而提升并发性
非阻塞IO有个问题,那就是线程要读数据,结果读了一部分后返回了,那么当数据到来时,如何通知线程继续读呢?写也是一样,如果缓冲区写满了没有写完,剩下的数据何时继续写,线程也应该得到通知。
事件轮询API就是用来解决这个问题的。最简单的事件轮询API是select函数。它是操作系统提供给用户程序的API。输入是读写描述符列表:read_fds&write_fds,输出是与之对应的可读可写事件。同时还提供了一个timeout参数,如果没有任务事件到来,那么就最多等待timeout的值的时间,线程处于阻塞状态。一旦期间没有任务事件到来,就可以立即返回。时间过了之后没有任务事件到来,也会立即返回。拿到事件后,线程就可以挨个处理相应的事件。处理完了继续过来轮询。于是线程就进入了一个死循环,这个死循环称为事件循环,一个循环为一个周期
每个客户端套接字socket都有对应的读写文件描述符,因为我们通过select(现在使用epoll函数)系统调用同时处理多个通道描述符的读写事件,因此我们将这类系统调用称为多路复用API。
通过系统提供的epoll函数同时处理多个通道描述符的读写事件,因此将这类调用称为多路复用API。
(一句话总结就是利用操作系统提供的epoll函数(基于事件驱动)同时处理多个通道描述符的读写事件来实现多路复用)
指令队列:Redis会将每个客户端套接字都关联一个指令队列。客户端的指令通过队列来排队进行顺序处理,先到先服务。
响应队列:Redis会为每个客户端套接字都关联一个响应队列。Redis服务器通过响应队列来将指令的返回结果回复给客户端。如果队列为空,那么意味着连接暂时处于空闲状态,不需要去获取写事件。
定时任务:服务器除了要响应IO事件外,还要处理其他的事情。比如定时任务就是非常重要的一件事。如果线程阻塞在select系统调用上,定时任务无法得到准时调度。Redis的定时任务会记录在一个被称为最小堆的数据结构中。在这个堆中,最快要执行的任务排在堆的最上方,每个循环周期里。Redis都会对最小堆里面已经到时间点的任务进行处理。处理完毕后,将最快要执行的任务还需要的时间记录下来,这个时间就是select系统调用的timeout参数。因为Redis知道未来timeout的值的时间内,没有其他定时任务需要处理,所以可以安心睡眠timeout的值的时间。
高效的数据结构:
在 Redis 中,常用的 5 种数据类型和应用场景如下:
- String: 缓存、计数器、分布式锁等。
- List: 链表、队列、微博关注人时间轴列表等。
- Hash: 用户信息、Hash 表等。
- Set: 去重、赞、踩、共同好友等。
- Zset: 访问量排行榜、点击量排行榜等
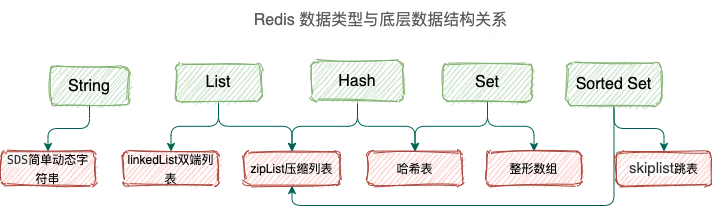
SDS动态字符串:
1)时间复杂度为O(1)
C 语言中获取字符串1的长度,要从头开始遍历,直到 「�」为止,时间复杂度为 O(n)。
SDS中len保存字符串的长度,获取字符串长度的时间复杂度为 O(1)。
2)空间预分配
SDS 被修改后,程序不仅会为 SDS 分配所需要的必须空间,还会分配额外的未使用空间,来减少内存的频繁分配
分配规则如下:如果对 SDS 修改后,len 的长度小于 1M,那么程序将分配和 len 相同长度的未使用空间;如果对 SDS 修改后 len 长度大于 1M,那么程序将分配 1M 的未使用空间。
3)惰性空间释放
当对 SDS 进行缩短操作时,程序并不会回收多余的内存空间,而是使用 free 字段将这些字节数量记录下来不释放,后面如果需要 append 操作,则直接使用 free 中未使用的空间,减少了内存的分配
4)二进制安全
在Redis中不仅可以存储String类型的数据,也可以存储一些二进制数据。
二进制数据并不是规则的字符串格式,其中会包含一些特殊的字符如 '�',在 C 中遇到 '�' 则表示字符串的结束,但在 SDS 中,标志字符串结束的是 len 属性
总结:Redis是一个单进程单线程且采用多路I/O复用模型,非阻塞IO技术, 使之可以同时处理多个连接请求(减少网络IO耗时), 也不需要关心锁,线程切换等资源消耗问题
Redis单线程特性的优缺点
优点:
1、代码更清晰,逻辑更简单
2、不用因为同步去考虑各种锁的问题,不存在加锁和释放锁的操作,基本不会出现死锁而导致的性能消耗
3、避免了多线程切换导致的CPU消耗,没有多线程切换的开销
缺点:
无法发挥多核CPU的性能,不过可以通过在单机开多个Redis实例来实现
为什么Redis6.0之后又改用多线程呢?
Redis6.0并非摒弃单线程,Redis仍使用单线程处理客户端的请求,以及执行命令。
只是使用多线程来处理数据的读写和协议解析。
因为Redis的瓶颈不是CPU,而是网络IO,使用多线程能提升IO读写的效率,从而整体提高Redis的性能。
END.