ETL工具开发目标是一款通用数据迁移工具,可扩充迁移的源数据类型,同时可以扩充目标端存储类型,是一款可以不断扩展功能的、通用的数据迁移工具。工具具有数据映射
过滤、默认值等插件可配置使用;提供业务处理插件接口,可供定制化业务处理;对大量数据进行分批迁移的功能;批量任务迁移时支持断点续传功能等。
3.2 ETL软件架构
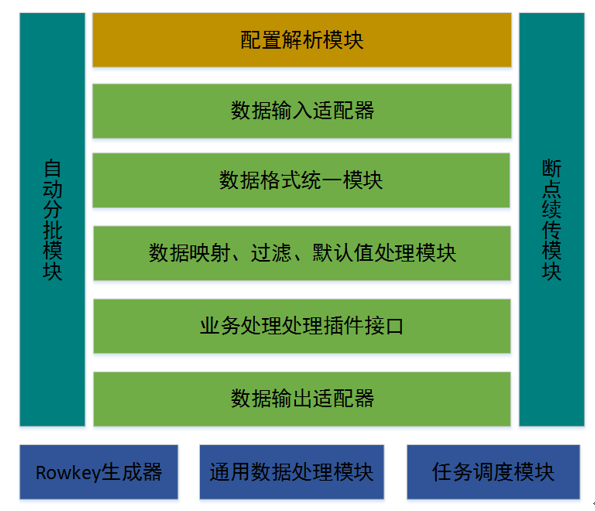
Figure 1 ETL软件架构图
上图为ETL软件架构,主要包含以下几个模块:
1) 配置解析模块
负责接收外部配置文件,按需解析配置文件内容。
2) 数据输入适配器
结合配置解析模块,解析输入配置,得到输入实例,再根据输入配置信息,抽取源数据。
3) 数据统一格式模块
对任意种类的数据,抽取到内存中后,需要对格式进行统一化,方面处理。在ETL中,ETL是基于Spark开发,数据抽取到内容中后,会转化成RDD(分布式弹性数据集),RDD结合数据结构会转化为DataSet(DataFrame)。
4) 数据映射、过滤、默认值处理模块
ETL内部集成针对数据的映射处理、过滤处理以及默认值处理,用户可以通过配置使用。
5) 业务数据处理插件接口
业务处理插件接口,用于复杂、需求常变动场景下,由业务人员定制处理处理业务使用。
6) 数据输出适配器
结合配置解析模块,解析输出配置,得到输出实例,再根据输出配置信息,加载数据到目标数据库端。
7) 自动分批模块
大数据项目中数据量通常从几百万条数据到几十上百亿条数据,对于数据量大的任务,工具需要把大任务分解成一批小任务分别执行。自动分批模块可根据输入的配置,结合单批次设定的数据量大小,对任务进行划分。
8) 断点续传功能
此功能和自动分批模块结合使用,在迁移过程中,批次任务异常中止后,重启工具,任务可自动识别当前已经执行成功的任务,从断点的批次继续执行数据迁移。
9) Rowkey生成器
当前ETL的输出数据端主要是Hbase数据库,rowkey的生成通常来自数据字段的值,结合一定函数组合而成。Rowkey生成器内嵌一些集成的基础函数,可供配置生成Rowkey。
10) 通用数据处理模块
此模块是一些通用的数据处理实现类,是实现业务数据处理插件接口得到。可以完成一些数据转化成输出数据格式要求。
11) 任务调度模块
此模块主要用于调度执行数据迁移任务。
3.3 已有功能说明
ETL工具目前提供功能如下图所示:
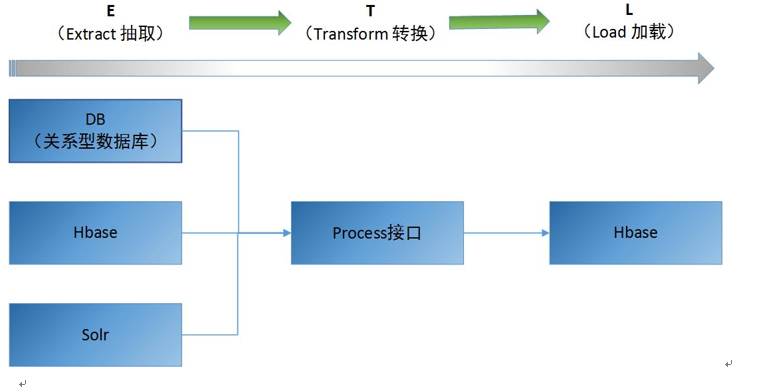
Figure 2 ETL功能示意图
功能说明:
ETL工具主要提供数据抽取、数据转换接口,数据输出功能。目前ETL工具提供从DB、Hbase、Solr抽取数据,然后经过用户实现的Process接口或者通用的业务处理类对数据进行转换处理,最后加载到Hbase数据库中。
3) 业务数据处理插件Process接口优化
业务数据处理插件的使用方式如下:
A、 实现process接口
B、 程序通过输入配置获取实现类信息
C、 通过反射方式实例化实现类
D、 调用实现类处理业务数据
E、 通过实现类返回值获取输出数据和对应的输出数据结构信息
老的process接口类
老版本ETL业务数据处理插件接口类定义如下:
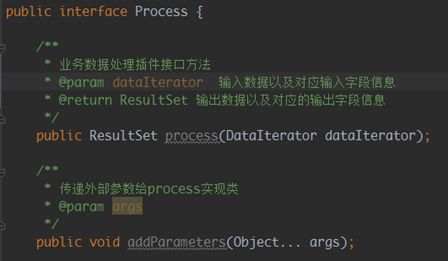
addParameters用于接收外部传入参数供process实现类使用
process方法用于实现对业务数据的处理
process输入参数DataIterator内部结构如下:
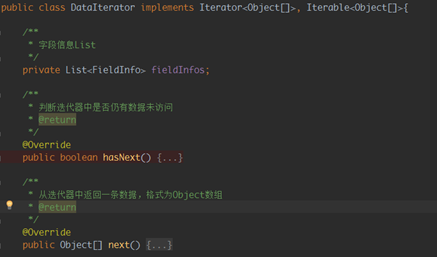
主要包含三个部分:
输入数据的字段信息fieldInfos
判断迭代器中是否有未访问的数据
从迭代器中返回一条数据
输出类ResultSet如下:
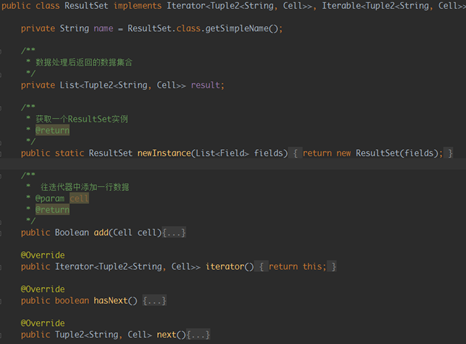
仍是一个迭代器,为后续访问数据方便,内存存储数据使用的为list存储。
(2)新的process接口类
从业务发展发现,上述接口基本可以满足业务处理要求,但一些特殊场景,用户需要获取输入配置的所有信息,不单单是输入数据的字段信息。
修改后新的业务数据处理插件接口类如下:
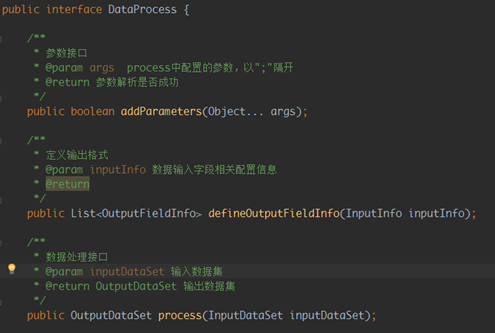
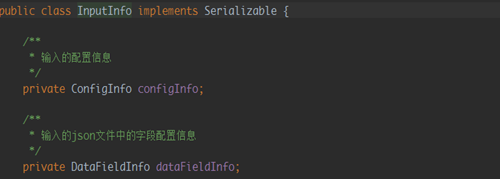
InputInfo类主要内容如下:
新的接口类改变点如下:
1、变更原有两个方式为三个方法
把输入数据和对应的字段信息分别提供两个方法实现,引导用户更好的使用输入字段信息并要求定义输出字段信息
2、在输入信息类中新增属性configInfo,其包含所有的输入配置信息。
3、调整类以及方法、参数的名称,使其更容易理解
4) 代码优化
在开发和测试etl过程中发现一些代码冗余、已经废弃、包含业务、效率低等问题,针对发现的问题,进行列举说明,部分内容进行详细说明。
(1)ArrayList的使用优化
旧版ETL中arraylist通常直接new使用,并未设置capacity,默认为10;
但是当arraylist中放入的数据量达到一定数据量后,arraylist会进行扩容,扩容的方式是拷贝现有数据新创建一个arraylist,扩容的后的数组大小为(oldCapacity + (oldCapacity >> 1))2倍多。
缺点:如果数据量特别大,很发生发次扩容,影响数据处理效率,且对内存有影响。
修改方式:ETL中为spark任务,spark的任务单元为partition,etl中每个partion中有多少条数据是确定的,使用时创建Arraylist时直接指定相应数据量的容量大小。
(linkList也可以解决上述问题,但linklist在随机访问时性能不佳,为影响存储在里面的数据的访问,故未使用)
Arraylist扩容相关代码如下:(如进一步了解请查看arraylist源码)
add数据时,
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
/**
* Copies the specified array, truncating or padding with nulls (if necessary)
**/
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
Spark两种共享变量:广播变量(broadcast variable)与累加器(accumulator)累加器用来对信息进行聚合,而广播变量用来高效分发较大的对象。
共享变量出现的原因:通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。Spark 的两个共享变量,累加器与广播变量,分别为结果聚合与广播这两种常见的通信模式突破了这一限制。
问题描述:
在使用少量数据测试ETL功能时发现,业务数据处理插件DataProcess实现类返回的输出数据字段信息在spark一些节点的execute中为null,定位结论为未进行初始化。
问题原因:
由于一些exectute执行了dataprocess实现类中的方法,有返回值,则输出字段信息有赋值,所以不为空。另外一些未执行,则为null。
解决办法:
Spark的广播变量可以在集群任务中共享此属性,只要在driver节点执行dataprocess获取输出字段信息,然后使用广播变量,即可在所有execute中使用此变量。