// 留着备用。
三个基本款分别是ConsoleAppender、FileAppender(以及他的兄弟RandomAccessFileAppender)、RollingFileAppender(以及他的兄弟RollingRandomAccessFileAppender),其中RollingFileAppender是三个appender中的老大,因为他一个人的文档篇幅就是其它两个appender文档篇幅总和的6~7倍左右。。。
关于三个appender的简单介绍:
<?xml version="1.0" encoding="UTF-8"?> <Configuration status="WARN"> <!-- 在Appenders中定义可选的输出“目的地” --> <Appenders> <!-- Appenders官方文档地址https://logging.apach e.org/log4j/2.x/manual/appenders.html,其次是可 以直接去看org.apache.logging.log4j.core.appender 包下的appender源代码 --> <Console name="STDOUT" target="SYSTEM_OUT"> <!-- 在pattern中定义输出格式,各种占位符(转 义符)的用法、含义可查询文档https://logging.a pache.org/log4j/2.x/manual/layouts.html --> <PatternLayout pattern="%m%n"/> <!-- 对于ConsoleAppender而言,Layout是必要的, 默认就是%m%n --> </Console> <!-- FileAppender。servlet容器中的两个web应用程序 可以拥有它们各自的配置,如果Log4j位于它们共同使用 的类加载器中,则可以安全地将日志写入同一个文件。默认 启用bufferedIO以及immediateFlush(前者提高性能,后 者可以保证写入,缓冲区没满也写入!每次写操作都会调 用flush,不过有点影响性能),如果是异步Logger,即便 immediateFlush设置为false,异步Logger和appender也 将在一批事件结束时自动flush,这样做比较高效同时 保证了数据写入磁盘 --> <File name="MyFile" fileName="logs/app.log"> <PatternLayout pattern="%m%n"/> </File> <!-- 似乎可以看作是FileAppender的进化版,实现上不大 一样,根据报导,相比启用了bufferedIO的FileAppender 性能提高了20-200%(RandomAccessFile没有bufferedIO 这个选项,因为它总是buffered的!) --> <RandomAccessFile name="MyRandomAccessFile" fileName="logs/app.log"> <PatternLayout> <Pattern>%d %p %c{1.} [%t] %m%n</Pattern> </PatternLayout> </RandomAccessFile> <!--RollingFileAppender是一个OutputStreamAppender, 它写入fileName参数中指定的文件,并根据TriggeringPolicy 和RolloverPolicy将文件翻转。对于RollingFileAppender而 言,这两个Policy都是必要的,TriggeringPolicy确定是否应 该执行滚动,而RolloverStrategy定义如何执行滚动。--> <RollingFile name="RollingFileInfo" fileName="logs/info.log" filePattern="logs/$${date:yyyy-MM}/info-%d{yyyy-MM-dd}-%i.log"> <ThresholdFilter level="info" onMatch="ACCEPT" onMismatch="DENY" /> <PatternLayout pattern="[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%-5level] %l %logger{36} - %msg%n" /> <Policies> <OnStartupTriggeringPolicy /> <SizeBasedTriggeringPolicy size="20 MB" /> <TimeBasedTriggeringPolicy /> </Policies> <!-- DefaultRolloverStrategy属性如不设置,则默认为最多同一文件夹下7个文件,这里设置了30 --> <DefaultRolloverStrategy max="30" /> </RollingFile> <!-- 故障转移追加器,如果primary追加器失败了, 就继续按照顺序尝试Failovers中的appenders --> <Failover name="Failover" primary="MyFile"> <Failovers> <AppenderRef ref="STDOUT"/> </Failovers> </Failover> </Appenders> <Loggers> <Root level="debug"> <AppenderRef ref="STDOUT"/> </Root> </Loggers> </Configuration>
针对RollingFileAppender的笔记↓
测试程序,负责源源不断地打log:
package org.sample.webapp.util; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; public class TestLog4j2 { private static final Logger LOGGER = LogManager.getLogger(); public static void main(String[] args) { for (int i = 0; i < 10000; i++) { LOGGER.info("Rolling file appender example..."); try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } } } }
示例之一(DefaultRolloverStrategy ):
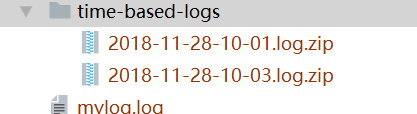
<?xml version="1.0" encoding="UTF-8"?> <!-- 实时写到mylog.log,每隔两分钟进行一次rollover, rollover策略为按照时间作为增量命名日志文件并压缩归档。--> <Configuration status="WARN"> <Appenders> <!-- 便于在控制台观察实际输出情况 --> <Console name="STDOUT" target="SYSTEM_OUT"> <PatternLayout> <Pattern>%d{yyyy-MMM-dd HH:mm:ss a} [%t] %-5p %c{-2} - %m%n</Pattern> </PatternLayout> </Console> <!-- 大概可以视为RollingFileAppender的进化版,没 有bufferedIO这个属性,对于RollingRandomAccessFile, 缓存是固定开启的。fileName是实时写入的(未归档)文 件名,filePattern则是归档文件的命名模式,因为开启了 异步日志所以这里immediateFlush设置为false(不过好像 不管它也无所谓),bufferSize缓冲区大小暂时默认, 最后,TriggeringPolicy和RolloverStrategy是必须有的, 没有显示定义就会采用默认的。--> <RollingRandomAccessFile name="RollingRandomAccessFile" fileName="logs/mylog.log" immediateFlush="false" filePattern="logs/time-based-logs/%d{yyyy-MM-dd-hh-mm}.log.zip"> <!-- 生成的日志文件名要么按照时间来增长,filePattern中需要%d, 要么就以整数增长,filePattern中需要%i,又或者两个搭配(意义似乎不是很大 因为rollover一次计数器又从1开始了。。),文件名仅按照时间增长的话, RolloverStrategy设置max,min参数似乎也没多什么意义了。--> <!-- 如果filePattern以".gz", ".zip", ".bz2", ".deflate", ".pack200",或者".xz"结尾, 那么将使用与相对应的压缩方案压缩生成的归档文件。--> <PatternLayout> <Pattern>%d{yyyy-MMM-dd HH:mm:ss a} [%t] %-5p %c{-2} - %m%n</Pattern> </PatternLayout> <!--决定是否应该执行rollover,只要有任何一个 policy返回true那么就进行rollover,rollover的 意思大概可以理解为:当日志文件满足特定条件时 将触发的事件,例如创建一个新的文件/把原有的文件 归档/删除等,具体怎样rollover由RolloverStrategy 决定 --> <Policies> <!-- jvm重启就进行一次rollover--> <OnStartupTriggeringPolicy /> <!-- 文件大小达到20mb进行一次rollover --> <SizeBasedTriggeringPolicy size="20 MB" /> <!-- TimeBasedTriggeringPolicy是最多用到的Policy, interval默认值是1,根据filePattern中日期的最小单位,例如 在该配置里是mm(分钟),设置interval="2"则每隔两分钟将发生 一次rollover,按当前配置,具体表现就是隔两分钟得到一个log.zip。 modulate就是让第一次rollover发生在区间边界上(即便还没到 interval的时长),按照当前配置,首次rollover会发生在比如 8点50分0秒,这样之后的rollover就是8点52分0秒、8点54分0秒.. 这样做的好处在于rollover的时机就变得很有规律很好预测,生成的 文件还很整齐(假设时间最小单位为天,interval="1",那么就 变成稳定每天0点自动rollover了。。)。还有个属性叫maxRandomDelay, 防止很多应用在同一时间一起rollover的,暂时不理它。 --> <TimeBasedTriggeringPolicy interval="2" modulate="true" /> </Policies> <!-- DefaultRolloverStrategy,默认rollover策略。参数: fileIndex有两个值,max和min,就是决定生成文件是从序号大的到 序号小的,还是从序号小的到序号大。min,计数器的起始值, 默认是1;max,计数器的最大值,默认是7。还有两个参数暂时不管。--> <DefaultRolloverStrategy/> </RollingRandomAccessFile> </Appenders> <Loggers> <!-- 用来debug。只要additivity不设置为false,日志起码会被打印到控制台。--> <Root level="debug"> <AppenderRef ref="STDOUT"/> </Root> <!-- 测试对象。将日志转发给RollingFileAppender --> <Logger name="org.sample.webapp.util.TestLog4j2" level="debug" additivity="true"> <AppenderRef ref="RollingRandomAccessFile" /> </Logger> </Loggers> </Configuration>
运行若干分钟后的结果:
下面是官方的example,将反驳上面注释里的一些自以为是的观点。。
/
示例之二,提速版官方xml(DefaultRolloverStrategy ):
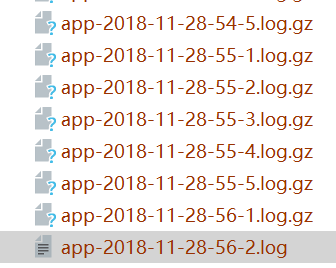
<?xml version="1.0" encoding="UTF-8"?> <!-- 将在同一天创建最多7个归档(1-7号),这些归档存储在基于 当前年和月的目录文件中,并用gzip压缩每个归档,我把所有时间 相关的变小两个单位修改成:每分钟最多7个归档,并存在基于 日和小时的目录文件中,并用gzip压缩每个归档 --> <Configuration status="warn" name="MyApp" packages=""> <Appenders> <!-- 形如$${date:yyyy-MM}参考https://logging.apache.org/log4j/2.x/manual/lookups.html#DateLookup--> <RollingFile name="RollingFile" fileName="logs/app.log" filePattern="logs/$${date:dd-HH}/app-%d{HH-mm-dd}-%i.log.gz"> <!-- 原来的值logs/$${date:yyyy-MM}/app-%d{MM-dd-yyyy}-%i.log.gz --> <PatternLayout> <Pattern>%d %p %c{1.} [%t] %m%n</Pattern> </PatternLayout> <Policies> <TimeBasedTriggeringPolicy /> <!-- 所以时间%d和整数%i同时用的意义就在于,当单个日志文件到达最大size 的时候创建一个新的文件 --> <SizeBasedTriggeringPolicy size="1 KB"/> </Policies> </RollingFile> </Appenders> <Loggers> <Root level="debug"> <AppenderRef ref="RollingFile"/> </Root> </Loggers> </Configuration>
运行若干分钟后的结果:

/
示例之三,提速版本官方xml(DirectWrite Rollover Strategy,好像和默认的也没多大差别。。)
<?xml version="1.0" encoding="UTF-8"?> <Configuration status="warn" name="MyApp" packages=""> <Appenders> <RollingFile name="RollingFile" filePattern="logs/app-%d{yyyy-MM-dd-mm}-%i.log.gz"> <PatternLayout> <Pattern>%d %p %c{1.} [%t] %m%n</Pattern> </PatternLayout> <Policies> <SizeBasedTriggeringPolicy size="2 KB"/> </Policies> <!-- 直接往filePattern所指定的文件写,没有rename这个环节--> <DirectWriteRolloverStrategy maxFiles="10"/> </RollingFile> </Appenders> <Loggers> <Root level="debug"> <AppenderRef ref="RollingFile"/> </Root> </Loggers> </Configuration>
运行若干分钟的结果: