在我上一个博客里面已经做好一个抓取某短视频网站里面,视频信息数据的工程,点击抓取到的短视频播放地址,是可以直接跳转在浏览器打开播放短视频的:
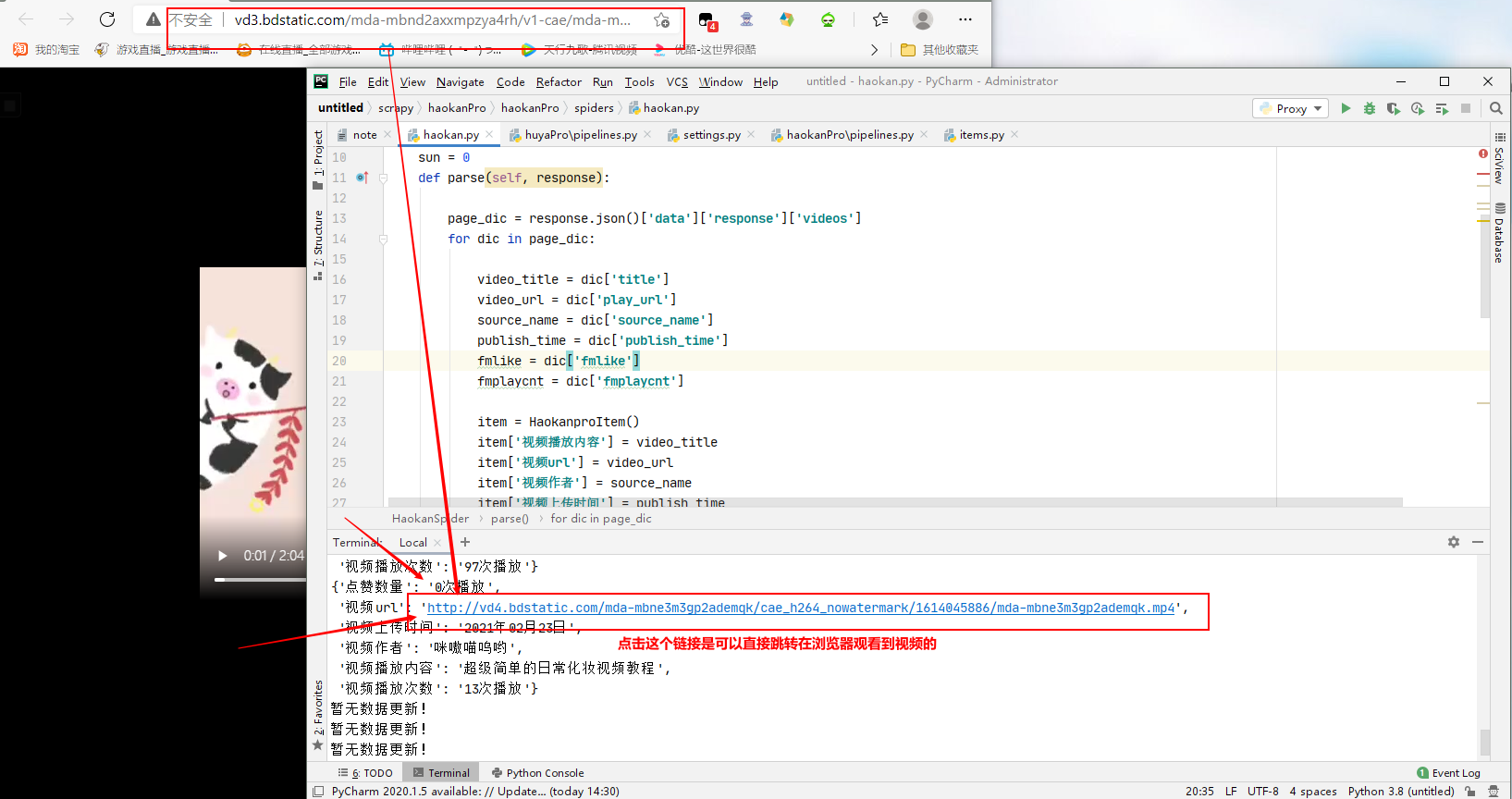
在此工程基础上,再在spiderName 里面请求到短视频的数据并且对其进行持久化储存(对视频播放地址发起请求) ,就可以实现该博客的标题项目:
在管道 pipelines.py 里面是无法通过请求视频播放地址对其进行持久化储存的,使用 ImagesPipeline 也不行,(找的资料说使用ImagesPipeline可以对视频、音频下载) 尝试使用 ImagesPipeline 对频播放地址发起请求,但是无法对其进行持久化储存(试跑工程打印已经下载,但是指定保存视频的文件夹是空的) ImagesPipeline 对图片地址发起请求是可以进行持久化储存(指定保存图片的文件夹有图片文件) 【也可能是我现在能力不足,不知道怎样使用ImagesPipeline对视频文件的下载】 所以这个项目的实现是在 spiderName.py 里面,直接对视频播放地址发起请求并且对其进行持久化储存了!
在 spiderName.py 里面对短视频地址请求并且对其进行持久化储存代码:
import scrapy
import time,os
from redis import Redis
from haokanPro.items import HaokanproItem
class HaokanSpider(scrapy.Spider):
name = 'haokan'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://haokan.baidu.com/videoui/api/videorec?tab=shishang&act=pcFeed&pd=pc&num=20&shuaxin_id={}'.format(int(round(time.time()*1000)))]
url = 'https://haokan.baidu.com/videoui/api/videorec?tab=shishang&act=pcFeed&pd=pc&num=20&shuaxin_id={}'.format(int(round(time.time() * 1000)))
sun = 0
conn = Redis(host='127.0.0.1', port=6379)#数据库链接对象
def parse(self, response):
page_dic = response.json()['data']['response']['videos']
for dic in page_dic:
video_title = dic['title']
video_url = dic['play_url']
source_name = dic['source_name']
publish_time = dic['publish_time']
fmlike = dic['fmlike']
fmplaycnt = dic['fmplaycnt']
trans = video_title.maketrans('/:*?"<?|', ' ')
video_title = video_title.translate(trans)
video_title = video_title.replace(' ','') #处理windows系统特殊符号导致无法保存数据文件(保存数据命名出错的问题)
item = HaokanproItem()
ex = self.conn.sadd('video_url', video_url)
try:
if ex == 1:#记录表去重
item['video_name'] = video_title + '.mp4'#设置保存视频的格式
item['视频播放内容'] = video_title
item['视频url'] = video_url
item['视频作者'] = source_name
# item['视频上传时间'] = publish_time
# item['点赞数量'] = fmlike
# item['视频播放次数'] = fmplaycnt
print('正在下载< {} >'.format(item['视频作者']),'的视频< {} > ...'.format(item['视频播放内容']))
yield scrapy.Request(url=item['视频url'], callback=self.parse_model,meta={'item': item})#对短视频地址请求、请求传参item
except:#处理请求异常报错
pass
if self.sun < 11:
new_url = self.url
self.sun += 1
yield scrapy.Request(url=new_url, callback=self.parse)
def parse_model(self,response):
item = response.meta['item']
fileName = os.path.join('video',item['video_name'])
with open(fileName,'wb') as fp:#保存视频数据的文件夹和保存短视频数据的命名
fp.write(response.body)
print('视频: {} 下载完成!'.format(item['视频播放内容']))
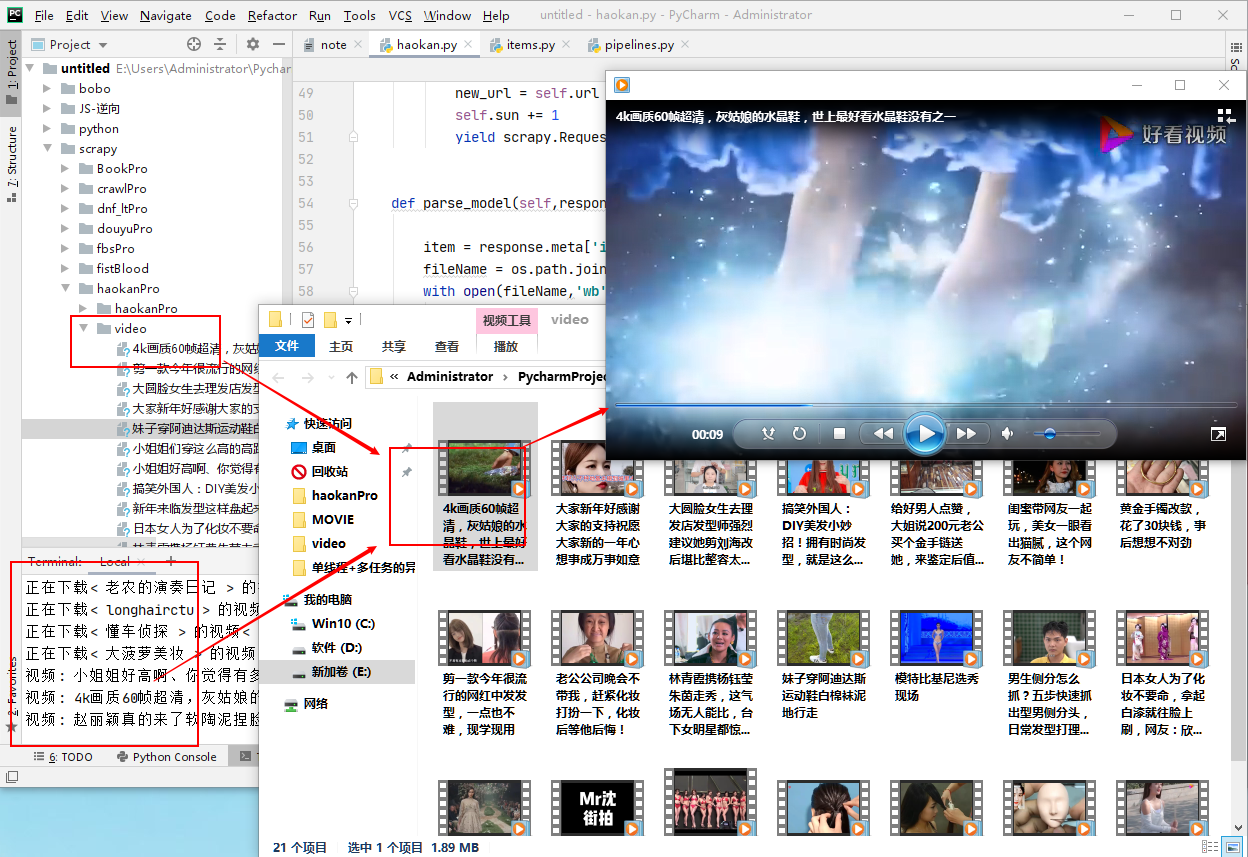
ok 下面是跑该工程的效果图:
本文可以借鉴学习,切勿照搬,根据自己的实际情况实现项目!!!