本文仅供学习与交流,切勿用于非法用途!!!
第一部分(分析):
图1:
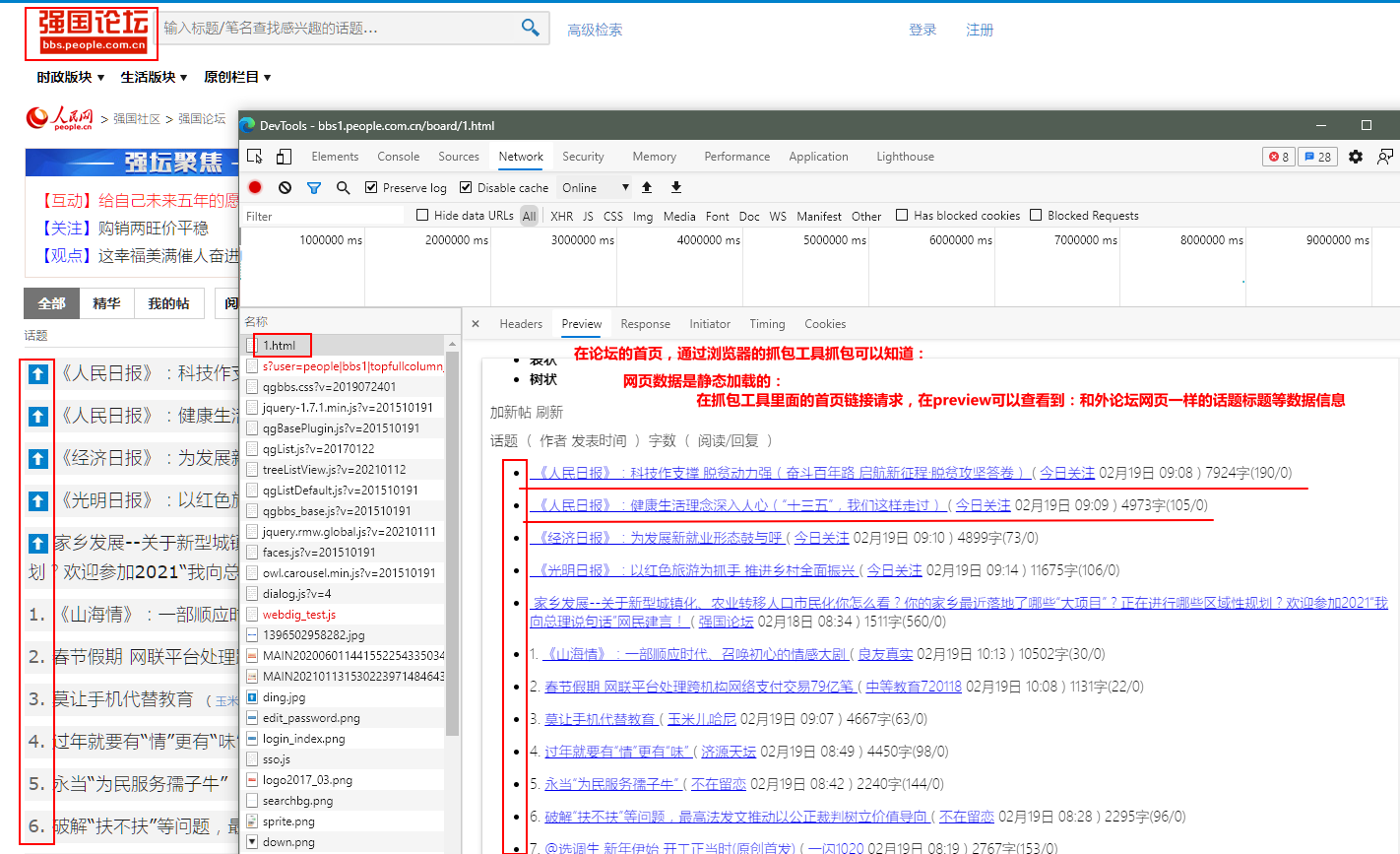
图2:

图3:
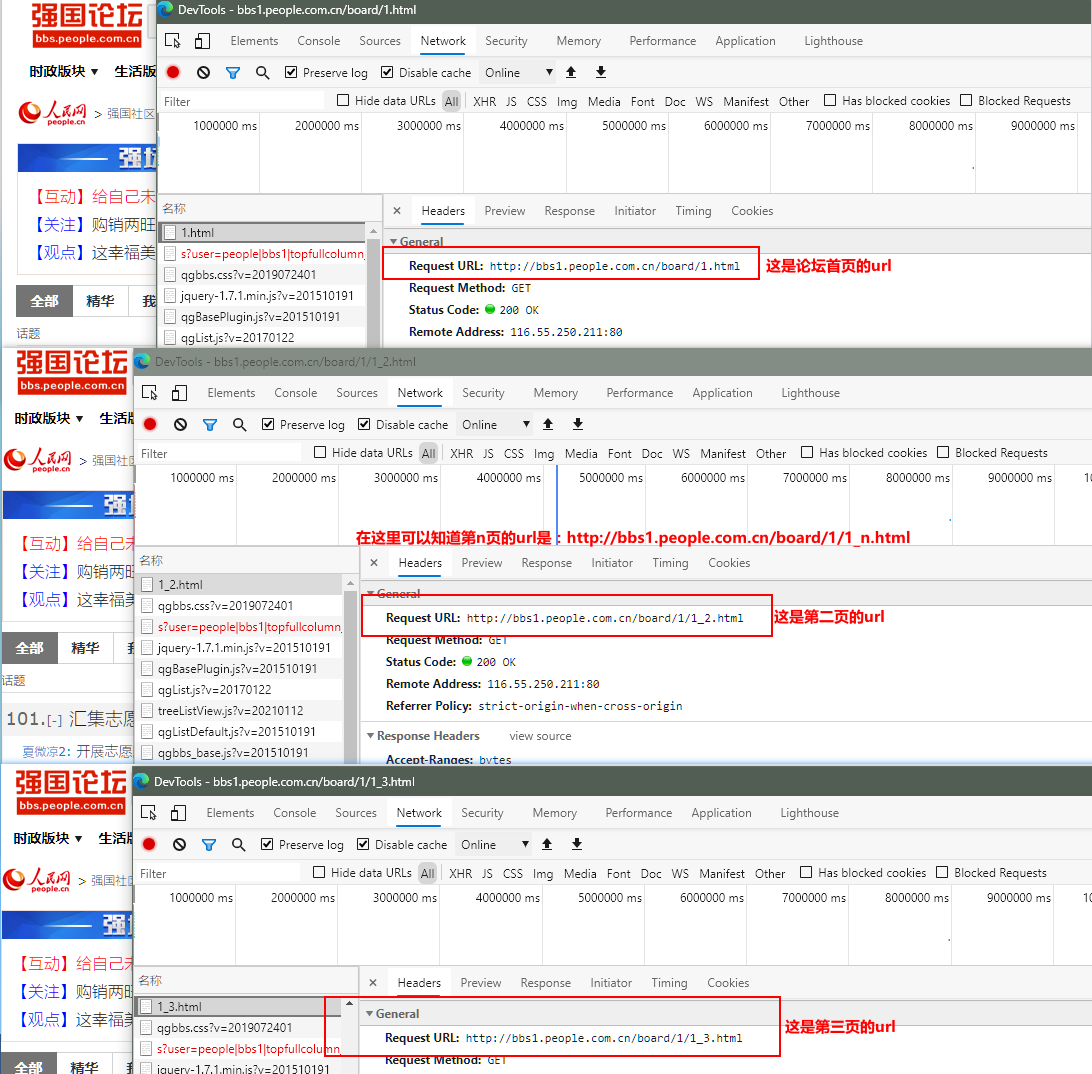
图4:

图5:

图6:

图7:

第二部分(实现代码):
实现爬取强国论坛的新闻标题内容,这里使用: scrapy startproject ProName > cd ProName >scrapy ganspider spiderName www.xxx.com 的scrapy工程和爬虫文件.
当然,也可以使用scrapy框架里面的CrawlSpider: scrapy startproject ProName > cd ProName > scrapy ganspider -t crawl spiderName www.xxx.com 实现爬取强国论坛的新闻标题内容.
1、创建好scrapy工程后,在配置文件settings.py里面设置USER_AGENT、日志级别和ROBOTSTXT_OBEY:
USER_AGENT = '自己设置User_Agent'
LOG_LEVEL = 'ERROR'##设置指定输出(报错的日志),减少CPU的使用率
ROBOTSTXT_OBEY = False #不遵从robots协议
****2、spiderName.py: ****
数据解析,获取到论坛新闻标题对应的url:
import scrapy
class PeopleSpider(scrapy.Spider):
name = 'spiderName'
# allowed_domains = ['www.xxx.com'] #把这个注释掉 用不到
start_urls = ['http://bbs1.people.com.cn/board/1/1_1.html']#论坛首页url
model_urls = []#动态加载数据的url
def parse(self, response):
li_list = response.xpath('/html/body/div[2]/div[3]/div[3]/ul/li')
for li in li_list:
detail_url = li.xpath('./p/a/@href').extract_first()#数据解析,获取到论坛新闻标题的url
self.model_urls.append(detail_url)#由于标题内容是动态加载的,把其作用到全局
手动请求发送,获取到下一页论坛新闻标题对应的url:
import scrapy
class PeopleSpider(scrapy.Spider):
name = 'spiderName'
# allowed_domains = ['www.xxx.com'] #把这个注释掉 用不到
start_urls = ['http://bbs1.people.com.cn/board/1/1_1.html']#论坛首页url
url = 'http://bbs1.people.com.cn/board/1/1_%d.html'#论坛下一页的通用url
pageNum = 2 #定义下一页的变量 进行手动请求发送
model_urls = []#动态加载数据的url
def parse(self, response):
li_list = response.xpath('/html/body/div[2]/div[3]/div[3]/ul/li')
for li in li_list:
detail_url = li.xpath('./p/a/@href').extract_first()#数据解析,获取到论坛新闻标题的url
self.model_urls.append(detail_url)#由于标题内容是动态加载的,把其作用到全局,使用selenium 来获取标题内容
if self.pageNum < 3:#结束递归的条件
new_url = format(self.url % self.pageNum)#下一页对应的完整url
self.pageNum += 1
yield scrapy.Request(url=new_url, callback=self.parse)#对下一页对应的url进行请求发生(手动请求发送)
使用selenium和请求传参:
在 items.py 里面:
class spiderNameproItem(scrapy.Item):#接受item对象
detail_url = scrapy.Field()
在 spiderName.py 里面:
import scrapy
from selenium import webdriver
from spiderName.items import spiderNameproItem
class PeopleSpider(scrapy.Spider):
name = 'spiderName'
# allowed_domains = ['www.xxx.com'] #把这个注释掉 用不到
start_urls = ['http://bbs1.people.com.cn/board/1/1_1.html']#论坛首页url
url = 'http://bbs1.people.com.cn/board/1/1_%d.html'#论坛下一页的通用url
pageNum = 2 #定义下一页的变量 进行手动请求发送
model_urls = []#动态加载数据的url
bro = webdriver.Chrome(executable_path='自己chromedriver的路径')
def parse(self, response):
item = spiderNameproItem()#实例化一个item对象,并且将解析到的数据储存到该对象中
li_list = response.xpath('/html/body/div[2]/div[3]/div[3]/ul/li')
for li in li_list:
detail_url = li.xpath('./p/a/@href').extract_first()#数据解析,获取到论坛新闻标题的url
self.model_urls.append(detail_url)#由于标题内容是动态加载的,把其作用到全局
for url in self.model_urls:
item['detail_url'] = url
yield scrapy.Request(url=url, callback=self.parse_model, meta={'item': item})#meta的作用是:可以将meta字典传递给callback
if self.pageNum < 3:#结束递归的条件
new_url = format(self.url % self.pageNum)#下一页对应的完整url
self.pageNum += 1
yield scrapy.Request(url=new_url, callback=self.parse)#对下一页对应的url进行请求发生(手动请求发送)
def parse_model(self,response):
item = response.meta['item']#接收传递过来的meta
'标题内容的数据解析部分就不写了'
yield item#提交给管道
def closed(self,spider):
self.bro.quit()#关闭selenium
在 middlewares.py 中间件里面:
from scrapy.http import HtmlResponse #scrapy 封装好的响应类
from selenium.webdriver.support.wait import WebDriverWait
#在 middlewares.py 里面class spidernameDownloaderMiddleware:前面的class类代码都干掉 只留下下面的类的三个方法
class spidernameDownloaderMiddleware:
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):#拦截所有响应对象
if request.url in spider.model_urls: #将拦截到的所有的响应对象中指定的标题内容动态加载的model_urls响应对象找出
bro = spider.bro
bro.get(request.url) #这里的request.url表示的就是指定的不满足需求的响应对象url
try:
WebDriverWait(bro,10).until(lambda el:bro.find_element_by_xpath('//*[@class="article scrollFlag"]'))#使用显示等待 等待标题内容的数据加载
except: # 处理bro发起请求时,有时因为某种原因使得页面一直处于加载状态,使得源代码一直不能返回的问题
bro.execute_script('window.stop()')
page_text = bro.page_source #捕获标题内容的数据
return HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request) #这里返回一个新的返回对象,替换原来原来不满足需求的、旧的响应对象
else:
return response #这里的response表示的就是不指定 满足需求的响应对象
def process_exception(self, request, exception, spider):
pass
中间件弄好后,回到配置文件settings.py里面把中间件、管道(要对数据进去持久化存储的话)开启:
DOWNLOADER_MIDDLEWARES = {
'spiderName.middlewares.PeopleproDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'spiderName.pipelines.PeopleproPipeline': 300,
}
加上增量式的代码 spiderName.py的完整代码如下:
这里实现的增量式是基于Redis数据库实现
import scrapy
from redis import Redis
from selenium import webdriver
from spiderName.items import spiderNameproItem
class PeopleSpider(scrapy.Spider):
name = 'spiderName'
# allowed_domains = ['www.xxx.com'] #把这个注释掉 用不到
start_urls = ['http://bbs1.people.com.cn/board/1/1_1.html']#论坛首页url
url = 'http://bbs1.people.com.cn/board/1/1_%d.html'#论坛下一页的通用url
pageNum = 2 #定义下一页的变量 进行手动请求发送
model_urls = []#动态加载数据的url
bro = webdriver.Chrome(executable_path='自己chromedriver的路径')
conn = Redis(host='127.0.0.1',port=6379) # 数据库链接对象
def parse(self, response):
item = spiderNameproItem()#实例化一个item对象,并且将解析到的数据储存到该对象中
li_list = response.xpath('/html/body/div[2]/div[3]/div[3]/ul/li')
for li in li_list:
detail_url = li.xpath('./p/a/@href').extract_first()#数据解析,获取到论坛新闻标题的url
self.model_urls.append(detail_url)#由于标题内容是动态加载的,把其作用到全局
for url in self.model_urls:
ex = self.conn.sadd('people_url',url) #ex==1插入成功,ex==0插入失败
if ex == 1:#表示url没有记录在redis数据库里面
item['detail_url'] = url
yield scrapy.Request(url=url, callback=self.parse_model, meta={'item': item})#meta的作用是:可以将meta字典传递给callback
if self.pageNum < 3:#结束递归的条件
new_url = format(self.url % self.pageNum)#下一页对应的完整url
self.pageNum += 1
yield scrapy.Request(url=new_url, callback=self.parse)#对下一页对应的url进行请求发生(手动请求发送)
def parse_model(self,response):
item = response.meta['item']#接收传递过来的meta
'标题内容的数据解析部分就不写了'
yield item#提交给管道
def closed(self,spider):
self.bro.quit()#关闭selenium
这是开启redis数据库跑这个工程的效果图:



本文可以借鉴学习,切勿照搬,根据自己分析的实际情况实现项目!!!