第一部分 分析:
第二部分 实现该工程代码:
这里使用: scrapy startproject ProName > cd ProName > scrapy genspider spiderName www.xxx.com 创建scrapy工程和爬虫文件.
创建好scrapy工程后,在配置文件settings.py里面设置USER_AGENT、日志级别和ROBOTSTXT_OBEY:
USER_AGENT = '自己设置User_Agent'
LOG_LEVEL = 'ERROR'#设置指定输出(报错的日志),减少CPU的使用率
ROBOTSTXT_OBEY = False #不遵从robots协议
** spiderName.py 爬虫文件的代码: **
import scrapy
from redis import Redis
from xsbookPro.items import XsbookproItem
class XsbookSpider(scrapy.Spider):
name = 'xsbook'
# allowed_domains = ['www.xxx.com']
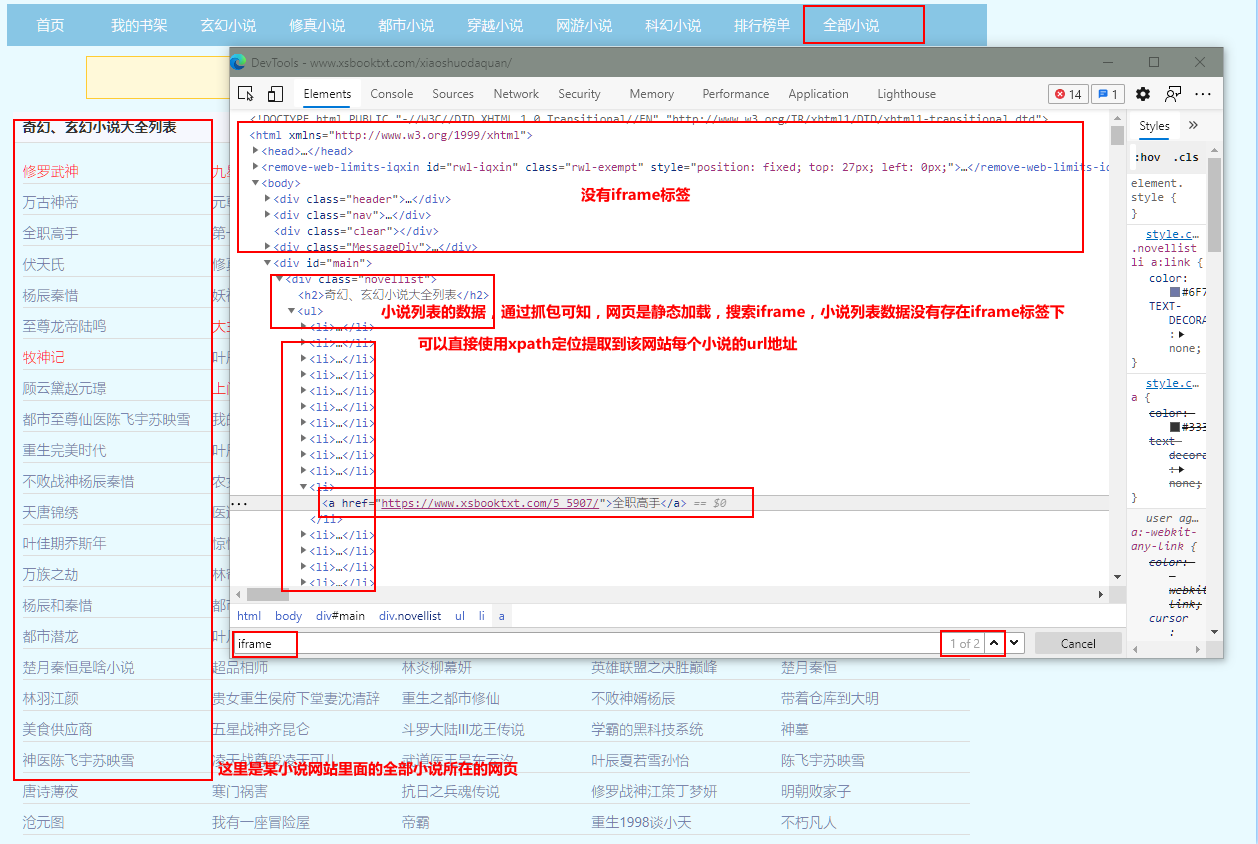
start_urls = ['https://www.xsbooktxt.com/xiaoshuodaquan/']#该函数是解析小说网站的所有的小说所在的网页地址
conn = Redis(host='127.0.0.1', port=6379)
def parse(self, response):#定位解析出小说网站的所有小说的url地址
href_list = response.xpath('//div[@class="novellist"]/ul/li')
for href in href_list:
xs_url = href.xpath('./a/@href').extract_first()
item = XsbookproItem()
item['xs_url'] = xs_url
yield scrapy.Request(url=xs_url,callback=self.parse_detail,meta={'item':item})#对每一本小说的地址发起请求,item对象保存的每本小说url进行请求传参
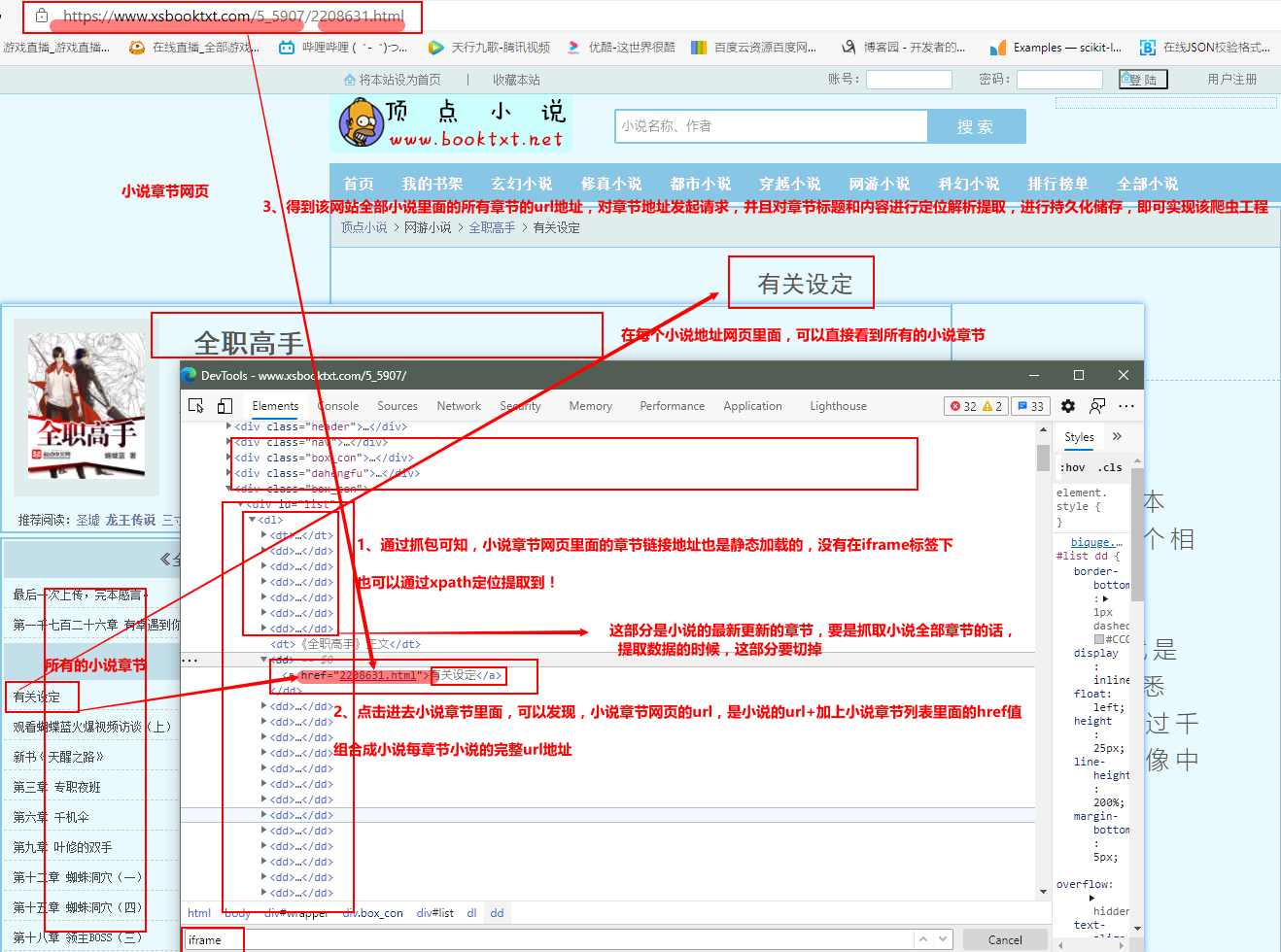
def parse_detail(self,response):#该函数是解析拼接出每本小说的所有章节url地址
item = response.meta['item']
xs_name = response.xpath('//*[@id="info"]/h1/text()').extract_first()
href_list = response.xpath('//*[@id="list"]/dl/dd')[6:]#这是切掉小说的最新更新部分,爬小说所有正文章节
item['xs_name'] = xs_name
for href in href_list:
href_url = item['xs_url'] + href.xpath('./a/@href').extract_first()
ex = self.conn.sadd('xsbooktxt',href_url)#redis数据库记录表去重(数据指纹,抓取过的小说章节不再抓取)
if ex == 1:
print(item['xs_name'] + ' 有最新章节更新...')
yield scrapy.Request(url=href_url, callback=self.requests_data, meta={'item':item})#对每一本小说的小说章节地址发起请求,item对象保存的数据进行请求传参
else:
print(item['xs_name'] + ' : 暂无最新章节更新!!!')
def requests_data(self,response):#该函数是对每本小说所在的章节数据进行解析提取
item = response.meta['item']
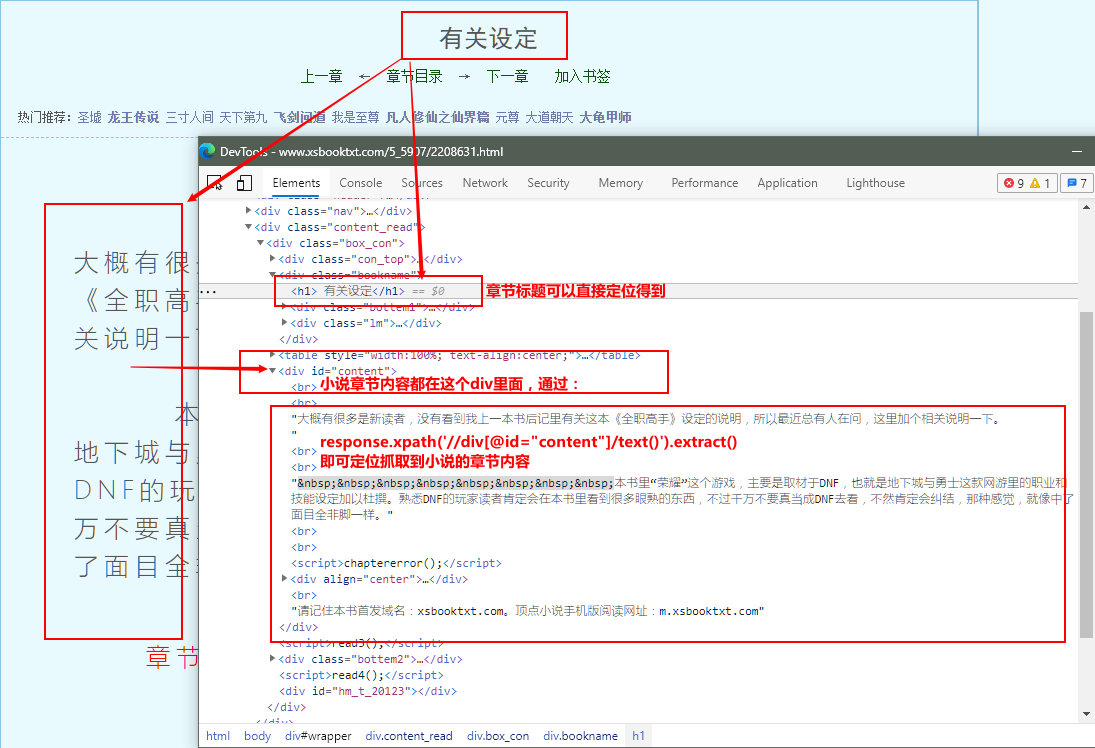
href_title = response.xpath('//div[@class="bookname"]/h1/text()').extract_first()#在这里定位提取每本小说的章节标题(在这里定位提取每本小说的章节标题,在保持数据的时候不会出现每本小说的章节标题和章节内容对不上)
trans = href_title.maketrans('/:*?"<?|', ' ')
href_title = href_title.translate(trans)
href_title = href_title.replace(' ','') #处理windows系统特殊符号导致无法保存数据文件(保存数据命名出错的问题)
content = '
'.join(response.xpath('//div[@id="content"]/text()').extract())
content = content.replace('请记住本书首发域名:xsbooktxt.com。顶点小说手机版阅读网址:m.xsbooktxt.com', '')
content = '
'.join(content.split()) #处理下载小说章节文字排版问题
item['href_title'] = href_title # 在小说章节内容里面找小说章节标题,在小说章节url里面找的话 和小说的章节内容对不上
item['content'] = content
yield item
ok,爬虫文件spiderName.py 部分完成了,下面是 items.py 定义爬取结果存储的数据结构:
class XsbookproItem(scrapy.Item):
xs_url = scrapy.Field()
xs_name = scrapy.Field()
href_title = scrapy.Field()
content = scrapy.Field()
** pipelines.py 数据管道部分的代码:**
import os
class XsbookproPipeline:
def process_item(self, item, spider):
if not os.path.exists(item['xs_name']) :#创建保存每本小说章节的文件夹
os.mkdir(item['xs_name'])
file_name = item['xs_name'] + '//' + item['href_title'] + '.txt'
with open(file_name, 'w', encoding='utf-8') as fp: #对每本小说的没个章节进行存储
fp.write(item['href_title'] + '
' + item['content'])
print(item['xs_name'] +'最新章节:<{}> 下载成功!'.format(item['href_title']))
return item
ok,最后在 settings.py 项目的配置文件开启管道:
ITEM_PIPELINES = {
'xsbookPro.pipelines.XsbookproPipeline': 300,
}
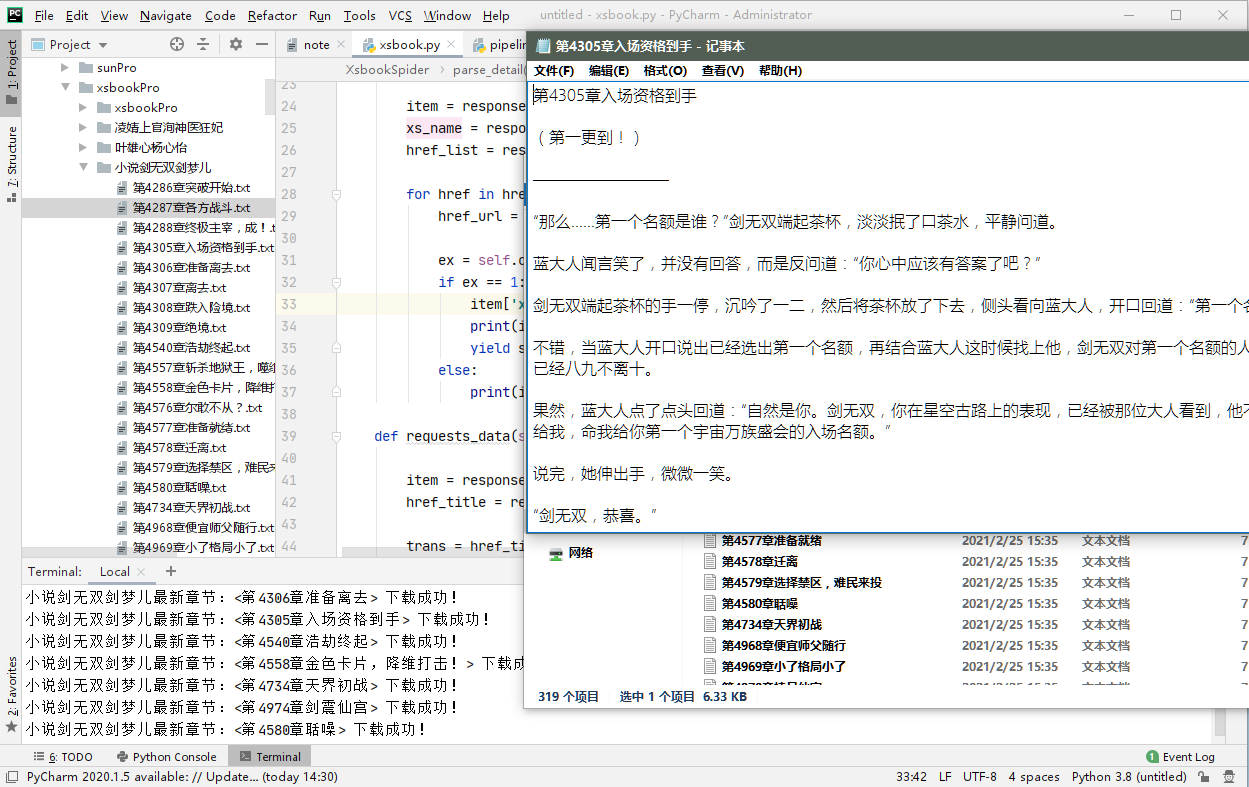
ok,完成!下面是开启redis数据库,跑该工程的效果图如下:
本文可以借鉴学习,切勿照搬,根据自己的实际情况修改部分代码,实现工程项目!!!