-
Spark does not have a good mechanism to select reasonable RDDs to cache their partitions in limited memory. --> Propose a novel selection algorithm, by which Spark can automatically select the RDDs to cache their partitions in memory according to the number of use for RDDs. --> speeds up iterative computations.
-
Spark use least recently used (LRU) replacement algorithm to evict RDDs, which only consider the usage of the RDDs. --> a novel replacement algorithm called weight replacement (WR) algorithm, which takes comprehensive consideration of the partitions computation cost, the number of use for partitions, and the sizes of the partitions.
Preliminary Information
Cache mechanism in Spark
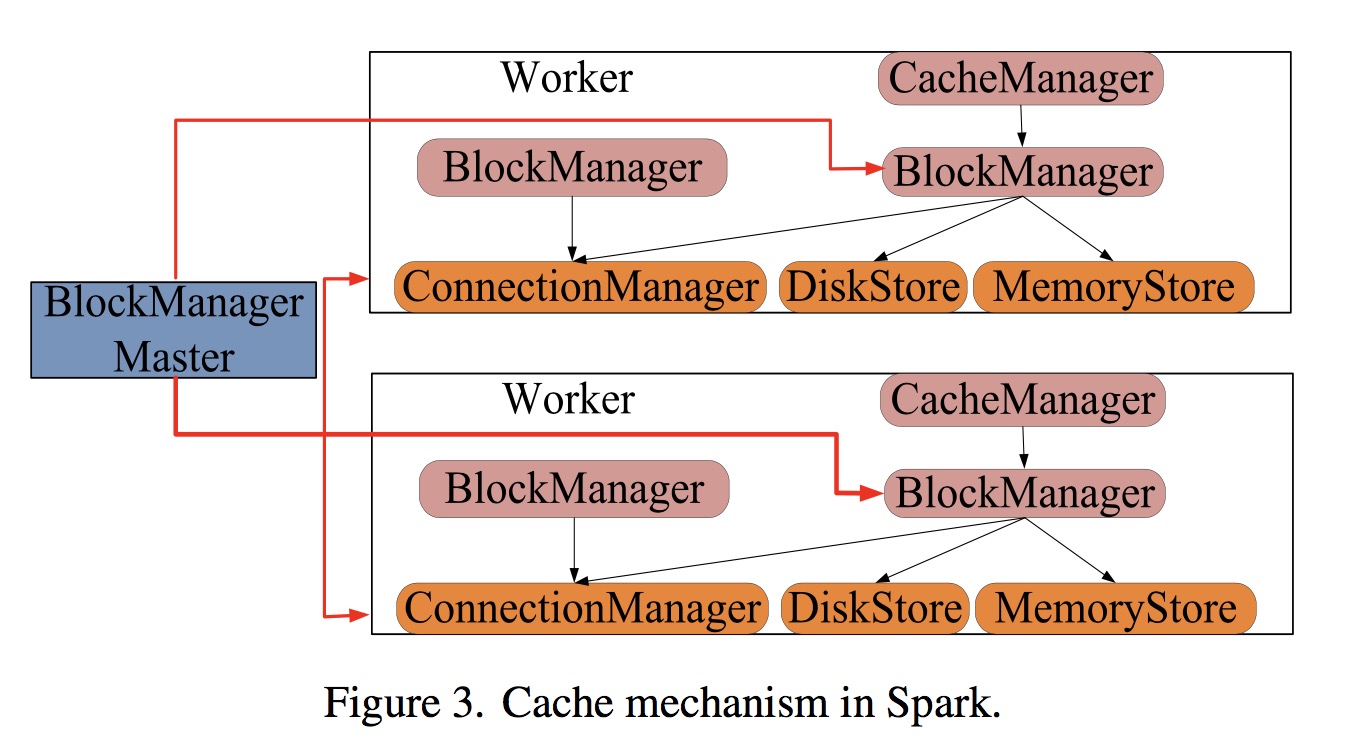
- When RDD partitions have been cached in memory during the iterative computation, an operation which needs the partitions will get them by CacheManager.
- All operations including reading or caching in CacheManager mainly depend on the API of BlockManager. BlockManager decides whether partitions are obtained from memory or disks.
Scheduling model
- The LRU algorithm only considers whether those partitions are recently used while ignores the partitions computation cost and the sizes of the partitions.
- The number of use for partitions can be known from the DAG before tasks are performed.
Let Nij be the number of use of j-th partition of RDDi.
Let Sij be the size of j-th partition or RDDi. - The computation time is also an important part. --> Each partition of RDDi starting time STij and finishing time FTij can roughly express its execution and communication time.
Consider the computation cost of partition as Costj = FTij - STij. - After that, we set up a scheduling model and obtain the weight of Pij, which can be expressed as:
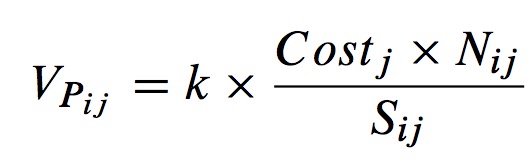
where k is the correction parameter, and it's set to a constant. - Finally, we assume that there are h partitions in RDDi, so the weight of RDDi is:
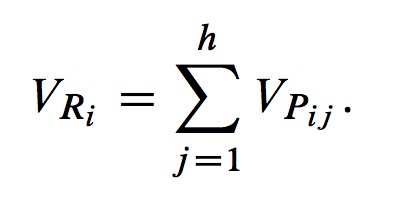
Proposed Algorithm
Selection algorithm
- For a given DAG graph,we can get the num of uses for each RDD, expressioned as NRDDi.
- The pseudocode:

Replacement algorithm
- In this paper, we use weight of partition to evaluate the importance of the partitions.
- When many partitions are cached in memory, we use QuickSort algorithm to sort the partitions according to the value of the partitions.
- The pseudocode:

Experiments
- five servers, six virtual machines, each vm has 100G disk, 2.5GHZ and runs Ubuntu 12.04 operation system while memory is variable, and we set it as 1G, 2G, or 4G in different conditions.
- Hadoop 2.10.4 and Spark-1.1.0.
- use ganglia to observe the memory usage.
- use pageRank algorithm to do expirement, it's iterative.