一、简单的线性回归
只有一个自变量(特征);方程是线性的;回归:label为连续数字型
假设我们找到了最佳拟合的直线方程:y = ax + b,则对于每个样本点x_i ,根据我们的直线方程,预测值为:y_i_hat = a*x_i + b
最佳拟合:误差最小(为了方便求导绝对误差改为了平方误差):∑(y_i_hat-y_i)^2
损失函数:描述了单个样本预测值和真实值之间误差的程度。用来度量模型一次预测的好坏。
风险函数:损失函数的期望,理论模型f(x)关于联合分布P(x,y)的平均意义下的损失
经验风险:模型f(x)关于训练数据集的平均损失,称为经验风险或经验损失
区别:期望风险是模型关于联合分布的期望损失,经验风险是模型关于训练样本数据集的平均损失。根据大数定律,当样本容量N趋于无穷时,经验风险趋于期望风险。
因此很自然地想到用经验风险去估计期望风险。但是由于训练样本个数有限,可能会出现过度拟合的问题,即决策函数对于训练集几乎全部拟合,但是对于测试集拟合效果过差。因此需要对其进行矫正:
结构风险最小化:当样本容量不大的时候,经验风险最小化容易产生“过拟合”的问题,为了“减缓”过拟合问题,提出了结构风险最小理论。结构风险最小化为经验风险与复杂度同时较小。结构风险:在经验风险上加上一个正则化项(regularizer),或者叫做罚项(penalty) 。正则化项是J(f)是函数的复杂度再乘一个权重系数(用以权衡经验风险和复杂度)
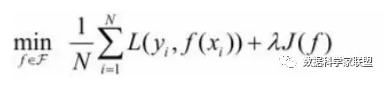
最小二乘法:让总的误差的平方最小的就是真实值。这是基于,如果误差是随机的,应该围绕真值上下波动。
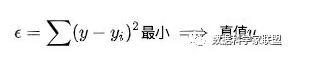
(高斯证明过:如果误差的分布是正态分布,那么最小二乘法得到的就是最有可能的值。)
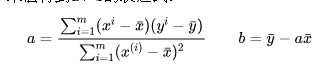
从中总结出一类机器学习算法的基本思路:
- 通过分析问题,确定问题的损失函数或者效用函数;
- 然后通过最优化损失函数或者效用函数,获得机器学习的模型。
#线性回归算法的实现 import numpy as np import matplotlib.pyplot as plt x = np.array([1.,2.,3.,4.,5.]) y = np.array([1.,3.,2.,3.,5,]) plt.scatter(x,y) plt.axis([0,6,0,6]) plt.show() #拟合 x_mean=np.mean(x) y_mean=np.mean(y) num=0.0 d=0.0 for x_i,y_i in zip(x,y): # zip函数打包成[(x_i,y_i)...]的形式 num+=(x_i-x_mean)*(y_i-y_mean) d+=(x_i-x_mean)**2 a=num/d b=y_mean-a*(x_i-x_mean) y_hat= a * x + b plt.scatter(x,y) # 绘制散点图 plt.plot(x,y_hat,color='r') # 绘制直线 plt.axis([0,6,0,6]) plt.show() x_predict=6 y_predict=a*x_predict+b print(y_predict) #向量化运算——dot #用for循环串行计算的效率远远低于向量化后,用矩阵方式并行计算的效率 import time a=np.random.rand(1000000) b=np.random.rand(1000000) tic= time.time() #返回当前时间的时间戳 c = np.dot(a, b) toc = time.time() print("c:%f" % c) print("vectorized version:" + str(1000*(toc-tic)) + "ms") #计算时间 c = 0 tic = time.time() for i in range(1000000): c += a[i] * b[i] toc = time.time() print("c: %f" % c) print("for loop:" + str(1000*(toc-tic)) + "ms") #工程文件 import numpy as np class SimpleLinearRegression: def __int__(self): self.a=None self.b=None def fit(self,x_train,y_train): """根据训练数据集x_train,y_train训练模型""" assert x_train.ndim ==1, "简单线性回归模型仅能够处理一维特征向量" assert len(x_train) == len(y_train), "特征向量的长度和标签的长度相同" x_mean = np.mean(x_train) y_mean = np.mean(y_train) num = (x_train - x_mean).dot(y_train - y_mean) # 分子 d = (x_train - x_mean).dot(x_train - x_mean) # 分母 self.a_ = num / d self.b_ = y_mean - self.a_ * x_mean return self def predict(self,x_predict): """给定待预测数据集x_predict,返回表示x_predict的结果向量""" assert x_predict.ndim == 1, "简单线性回归模型仅能够处理一维特征向量" assert self.a_ is not None and self.b_ is not None, "先训练之后才能预测" return np.array([self._predict(x) for x in x_predict]) def _predict(self, x_single): """给定单个待预测数据x_single,返回x_single的预测结果值""" return self.a_ * x_single + self.b_ def __repr__(self): """返回一个可以用来表示对象的可打印字符串""" return "SimpleLinearRegression()" #调用 from myAlgorithm.SimpleLinearRegression import SimpleLinearRegression x = np.array([1.,2.,3.,4.,5.]) y = np.array([1.,3.,2.,3.,5,]) x_predict = np.array([6]) reg = SimpleLinearRegression() reg.fit(x,y) reg.predict(x_predict) reg.a_ reg.a_
二、多元线性回归


这种计算方法,缺点是时间复杂度较高:O(n^3),在特征比较多的时候,计算量很大。优点是不需要对数据进行归一化处理,原始数据进行计算参数,不存在量纲的问题(多选线性没必要做归一化处理)
#多元回归 from sklearn.metrics import r2_score class LinearRegression: def __init__(self): """初始化Linear Regression模型""" self.coef_ = None # 系数(theta0~1 向量) self.interception_ = None # 截距(theta0 数) self._theta = None # 整体计算出的向量theta def fit_normal(self, X_train, y_train): """根据训练数据X_train,y_train训练Linear Regression模型""" assert X_train.shape[0] == y_train.shape[0], "the size of X_train must be equal to the size of y_train" # 正规化方程求解 X_b = np.hstack([np.ones((len(X_train), 1)), X_train]) self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train) self.interception_ = self._theta[0] self.coef_ = self._theta[1:] return self def predict(self, X_predict): """给定待预测的数据集X_predict,返回表示X_predict的结果向量""" assert self.interception_ is not None and self.coef_ is not None, "must fit before predict" assert X_predict.shape[1] == len(self.coef_), "the feature number of X_predict must be equal to X_train" X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict]) y_predict = X_b.dot(self._theta) return y_predict def score(self, X_test, y_test): """很倔测试机X_test和y_test确定当前模型的准确率""" y_predict = self.predict(self, X_test) return r2_score(y_test, y_predict) def __repr__(self): return "LinearRegression()" #__str__和__repr__ #如果要把一个类的实例变成 str,就需要实现特殊方法__str__() #默认情况下,__repr__() 会返回和调用者有关的 “类名+object at+内存地址”信息。 #当然,我们还可以通过在类中重写这个方法,从而实现当输出实例化对象时,输出我们想要的信息。 # ============================================================================= # 其实在代码中,思想很简单,就是使用公式即可。其中有一些知识点: # 1、np.hstack(tup):参数tup可以是元组,列表,或者numpy数组,返回结果为numpy的数组。按列顺序把数组给堆叠起来(加一个新列)。 # 2、np.ones():返回一个全1的n维数组,有三个参数:shape(用来指定返回数组的大小)、dtype(数组元素的类型)、order(是否以内存中的C或Fortran连续(行或列)顺序存储多维数据)。后两个参数都是可选的,一般只需设定第一个参数。(类似的还有np.zeros()返回一个全0数组) # 3、numpy.linalg模块包含线性代数的函数。使用这个模块,可以计算逆矩阵、求特征值、解线性方程组以及求解行列式等。inv函数计算逆矩阵 # 4、T:array的方法,对矩阵进行转置。 # 5、dot:点乘 # =============================================================================