图像处理
1、灰度化
灰度处理,就是把彩色的验证码图片转为灰色的图片。
二值化,是将图片处理为只有黑白两色的图片,利于后面的图像处理和识别
在OpenCV中有现成的方法可以进行灰度处理并二值化,处理后的效果:

cvtcolor()函数是一个颜色空间转换函数。
通道转换说明:
经常用到的颜色转换:BGR-->RGB, BGR-->Gray 和 BGR-->HSV
BGR-->RGB: 经过摄像头采集的图像的通道排列顺序为BGR,而BMP文件的排列顺序也为BGR,所以保存成BMP文件使不会出现什么问题。
但是在显示器上显示的时候的排列顺序为RGB,所以RGB是为了让机器更好的显示图像,。
BGR-->Gray:将BGR的图像转为单通道的灰色图像
BGR-->HSV: 一般对颜色空间的图像进行有效处理都是在HSV空间进行的。RGB是为了让机器更好的显示图像,对于人类来说并不直观,
HSV更为贴近我们的认知,所以通常我们在针对某种颜色做提取时会转换到HSV颜色空间里面来处理
#读取原始图
img = cv2.imread(img_path)
cv2.imshow("img", img)
# BGR-->RGB
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
cv2.imshow("img_rgb", img_rgb)
# 图像的灰化YUV(Y为灰度图, Y=0.299R+0.587G+0.114B):BGR-- >Gray
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imshow("img_gray", img_gray)
# HSV模型转化YUV(Y为亮度, UV代表色度)BGR-->HSV
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
cv2.imshow("img_hsv", img_hsv)
2、图像阈值
对于每个像素,应用相同的阈值。如果像素值小于阈值,则将其设置为0,否则将其设置为最大值。
cv.threshold()用来实现阈值分割,ret是return value缩写,代表当前的阈值,暂时不用理会。函数有4个参数:
参数1:要处理的原图,一般是灰度图
参数2:设定的阈值
参数3:最大阈值,一般为255
参数4:阈值的方式,主要有5种。
0: THRESH_BINARY 当前点值大于阈值时,取Maxval,也就是第四个参数,下面再不说明,否则设置为0
1: THRESH_BINARY_INV 当前点值大于阈值时,设置为0,否则设置为Maxval
2: THRESH_TRUNC 当前点值大于阈值时,设置为阈值,否则不改变
3: THRESH_TOZERO 当前点值大于阈值时,不改变,否则设置为0
4: THRESH_TOZERO_INV 当前点值大于阈值时,设置为0,否则不改变
# 应用5种不同的阈值方法 ret, th1 = cv.threshold(img, 127, 255, cv.THRESH_BINARY) ret, th2 = cv.threshold(img, 127, 255, cv.THRESH_BINARY_INV) ret, th3 = cv.threshold(img, 127, 255, cv.THRESH_TRUNC) ret, th4 = cv.threshold(img, 127, 255, cv.THRESH_TOZERO) ret, th5 = cv.threshold(img, 127, 255, cv.THRESH_TOZERO_INV)
请通过类型的文档来观察区别。该方法返回两个输出。第一个是使用的阈值,第二个输出是阈值后的图像。此代码比较了不同的简单阈值类型:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('gradient.png',0)
ret,thresh1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
ret,thresh2 = cv.threshold(img,127,255,cv.THRESH_BINARY_INV)
ret,thresh3 = cv.threshold(img,127,255,cv.THRESH_TRUNC)
ret,thresh4 = cv.threshold(img,127,255,cv.THRESH_TOZERO)
ret,thresh5 = cv.threshold(img,127,255,cv.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in xrange(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
自适应阈值
看得出来固定阈值是在整幅图片上应用一个阈值进行分割,它并不适用于明暗分布不均的图片。
cv.adaptiveThreshold()自适应阈值会每次取图片的一小部分计算阈值,这样图片不同区域的阈值就不尽相同。它有5个参数:
参数1:要处理的原图
参数2:最大阈值,一般为255
参数3:小区域阈值的计算方式
ADAPTIVE_THRESH_MEAN_C:小区域内取均值
ADAPTIVE_THRESH_GAUSSIAN_C:小区域内加权求和,权重是个高斯核
参数4:阈值方式(跟前面讲的那5种相同)
参数5:小区域的面积,如11就是11*11的小块
参数6:最终阈值等于小区域计算出的阈值再减去此值
# 固定阈值
ret, th1= cv.threshold(img, 127, 255, cv.THRESH_BINARY) # 自适应阈值 th2 = cv.adaptiveThreshold(img, 255, cv.ADAPTIVE_THRESH_MEAN_C, cv.THRESH_BINARY, 15, 4) th3 = cv.adaptiveThreshold(img, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY, 15, 8)
若我们使用一个全局值作为阈值,这可能并非在所有情况下都很好。例如,如果图像在不同区域具有不同的光照条件。在这种情况下,自适应阈值阈值化可以提供帮助。在此,算法基于像素周围的小区域确定像素的阈值。因此,对于同一图像的不同区域,我们获得了不同的阈值,这为光照度变化的图像提供了更好的结果。除上述参数外,方法cv.adaptiveThreshold还包含三个输入参数:该adaptiveMethod决定阈值是如何计算的:cv.ADAPTIVE_THRESH_MEAN_C::阈值是邻近区域的平均值减去常数C。
cv.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域值的高斯加权总和减去常数C。该BLOCKSIZE确定附近区域的大小,C是从邻域像素的平均或加权总和中减去的一个常数。下面的代码比较了光照变化的图像的全局阈值和自适应阈值:
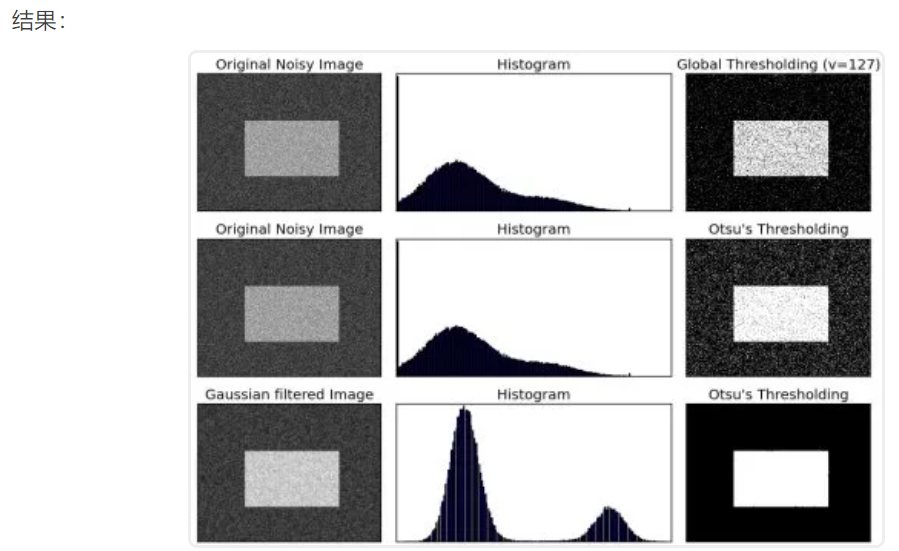
结果:

Otsu的二值化
在全局阈值化中,我们使用任意选择的值作为阈值。相反,Otsu的方法避免了必须选择一个值并自动确定它的情况。考虑仅具有两个不同图像值的图像(双峰图像),其中直方图将仅包含两个峰。一个好的阈值应该在这两个值的中间。类似地,Otsu的方法从图像直方图中确定最佳全局阈值。为此,使用了cv.threshold作为附加标志传递。阈值可以任意选择。然后,算法找到最佳阈值,该阈值作为第一输出返回。查看以下示例。输入图像为噪点图像。在第一种情况下,采用值为127的全局阈值。在第二种情况下,直接采用Otsu阈值法。在第三种情况下,首先使用5x5高斯核对图像进行滤波以去除噪声,然后应用Otsu阈值处理。了解噪声滤波如何改善结果。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('noisy2.png',0)
# 全局阈值
ret1,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
# Otsu阈值
ret2,th2 = cv.threshold(img,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
# 高斯滤波后再采用Otsu阈值
blur = cv.GaussianBlur(img,(5,5),0)
ret3,th3 = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
# 绘制所有图像及其直方图
images = [img, 0, th1,
img, 0, th2,
blur, 0, th3]
titles = ['Original Noisy Image','Histogram','Global Thresholding (v=127)',
'Original Noisy Image','Histogram',"Otsu's Thresholding",
'Gaussian filtered Image','Histogram',"Otsu's Thresholding"]
for i in xrange(3):
plt.subplot(3,3,i*3+1),plt.imshow(images[i*3],'gray')
plt.title(titles[i*3]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+2),plt.hist(images[i*3].ravel(),256)
plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+3),plt.imshow(images[i*3+2],'gray')
plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([])
plt.show()
Otsu的二值化如何实现?
本节演示了Otsu二值化的Python实现,以展示其实际工作方式。如果您不感兴趣,可以跳过此步骤。由于我们正在处理双峰图像,因此Otsu的算法尝试找到一个阈值(t),该阈值将由关系式给出的加权类内方差最小化:
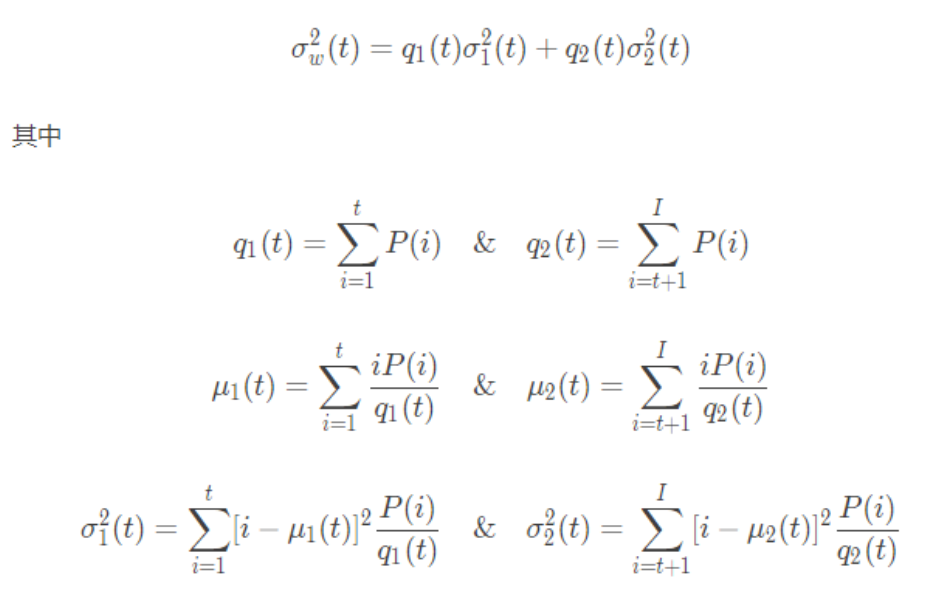
实际上,它找到位于两个峰值之间的t值,以使两个类别的差异最小。它可以简单地在Python中实现,如下所示:
img = cv.imread('noisy2.png',0)
blur = cv.GaussianBlur(img,(5,5),0)
# 寻找归一化直方图和对应的累积分布函数
hist = cv.calcHist([blur],[0],None,[256],[0,256])
hist_norm = hist.ravel()/hist.max()
Q = hist_norm.cumsum()
bins = np.arange(256)
fn_min = np.inf
thresh = -1
for i in xrange(1,256):
p1,p2 = np.hsplit(hist_norm,[i]) # 概率
q1,q2 = Q[i],Q[255]-Q[i] # 对类求和
b1,b2 = np.hsplit(bins,[i]) # 权重
# 寻找均值和方差
m1,m2 = np.sum(p1*b1)/q1, np.sum(p2*b2)/q2
v1,v2 = np.sum(((b1-m1)**2)*p1)/q1,np.sum(((b2-m2)**2)*p2)/q2
# 计算最小化函数
fn = v1*q1 + v2*q2
if fn < fn_min:
fn_min = fn
thresh = i
# 使用OpenCV函数找到otsu的阈值
ret, otsu = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
print( "{} {}".format(thresh,ret) )
大津二值化算法 ( Otsu's binarization ) ,是自动确定二值化图像时的阈值,也被称作最大类间方差法
ret2,th2 = cv2.threshold(img,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
THRESH_OTSU和THRESH_TRIANGLE
这两种标志是获取阈值的方法,并不是阈值的比较方法的标志,这两个标志可以和前面5种标志一起使用。
前面5种标志在调用函数时都需要人为的设置阈值,如果对图像不了解设置的阈值不合理,会对处理后的效果造成严重的影响,这两个标志分别表示利用大津法(OTSU)和三角形法(TRIANGLE)结合图像灰度值分布特性获取二值化的阈值,并将阈值以函数返回值的形式给出。
 help(cv2.cvtColor)
help(cv2.cvtColor)灰度处理、二值化处理
#导入模块
import cv2
#获取图片地址
image_addr = 'D:\\Learning\\test.jpg'
#读取图片,返回的是图片的一个数组对象
image = cv2.imread(image_addr)
#image对象常用属性如下:
image_attr =[
'all', 'any', 'argmax', 'argmin', 'argpartition', 'argsort', 'astype', 'base', 'byteswap', 'choose', 'clip', 'compress', 'conj',
'conjugate', 'copy', 'ctypes','cumprod', 'cumsum', 'data', 'diagonal', 'dot', 'dtype', 'dump', 'dumps', 'fill', 'flags', 'flat',
'flatten', 'getfield', 'imag', 'item', 'itemset', 'itemsize', 'max', 'mean', 'min', 'nbytes', 'ndim', 'newbyteorder', 'nonzero',
'partition', 'prod', 'ptp', 'put', 'ravel', 'real', 'repeat', 'reshape', 'resize', 'round', 'searchsorted', 'setfield', 'setflags',
'shape', 'size', 'sort', 'squeeze', 'std', 'strides', 'sum', 'swapaxes', 'take', 'tobytes', 'tofile', 'tolist', 'tostring', 'trace',
'transpose', 'var', 'view']
print(f"获取图片的维度: {image.ndim}") #获取图片的维度
print(f"获取图片的形状: {image.shape}") #获取图片的形状
print(f"获取图片的大小: {image.size}") #获取图片的大小
#对图片灰度处理
image_cvt = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#输出图片地址
image_out_addr = 'D:\\Learning\\imagecvt.jpg'
#输出图片
cv2.imwrite(image_out_addr,image_cvt)
#对灰度后的图片进行二值化处理
image_binary = cv2.adaptiveThreshold(image_cvt, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 1)
#输出图片地址
image_binary_addr = 'D:\\Learning\\binary.jpg'
#输出图片
cv2.imwrite(image_binary_addr,image_binary)



3、模糊
平均滤波cv2.Blur,
高斯滤波cv2.GaussianBlur(),
中值模糊cv2.medianBlur(),
双边模糊cv2.bilateralFilter()
4、去噪
OpenCV提供了这种技术的四种变体。
cv2.fastNlMeansDenoising() - 使用单个灰度图像
cv2.fastNlMeansDenoisingColored() - 使用彩色图像。
cv2.fastNlMeansDenoisingMulti() - 用于在短时间内捕获的图像序列(灰度图像)
cv2.fastNlMeansDenoisingColoredMulti() - 与上面相同,但用于彩色图像。
fastNlMeansDenoising(src[, dst[, h[, templateWindowSize[, searchWindowSize]]]])
fastNlMeansDenoisingColored(src[, dst[, h[, hColor[, templateWindowSize[, searchWindowSize]]]]])
fastNlMeansDenoisingMulti(srcImgs, imgToDenoiseIndex, temporalWindowSize[, dst[, h[, templateWindowSize[, searchWindowSize]]]])
fastNlMeansDenoisingColoredMulti(srcImgs, imgToDenoiseIndex, temporalWindowSize[, dst[, h[, hColor[, templateWindowSize[, searchWindowSize]]]]])
参数解析:
h:参数决定滤波器强度。较高的h值可以更好地消除噪声,但也会删除图像的细节 (10 is ok)
hColor:与h相同,但仅适用于彩色图像。 (通常与h相同)
templateWindowSize:应该是奇数。 (recommended 7)
searchWindowSize:应该是奇数。 (recommended 21)
5、腐蚀和膨胀
数学形态学提供了一组有用的方法,能够用来调整分割区域的形状以获得比较理想的结果,它最初是从数学中的集合论发展而来并用于处理二值图的,虽然运算很简单,但是往往可以产生很好的效果,后来这些方法推广到普通的灰度级图像处理中。常用的形态学处理方法包括:腐蚀、膨胀、开运算、闭运算、顶帽运算、底帽运算,其中膨胀与腐蚀是图像处理中最常用的形态学操作手段,其他方法是两者相互组合而产生的。
形态学处理的核心就是定义结构元素,在OpenCV-Python中,可以使用其自带的getStructuringElement函数,也可以直接使用NumPy的ndarray来定义一个结构元素。
getStructuringElement(shape, ksize[, anchor])
参数解析:
shape:核的形状
MORPH_RECT 表示产生矩形的结构元
MORPH_ELLIPSE 表示产生椭圆形的结构元
MORPH_CROSS 表示产生十字交叉形的结构元
ksize:表示结构元的尺寸,即(宽,高),必须是奇数
anchor:表示结构元的锚点,即参考点。默认值Point(-1, -1)代表中心像素为锚点
erode(src, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]])把白色变成黑色
参数解析
src:表示输入矩阵
kernel:表示结构元,即 函数getStructuringElement( )的返回值
anchor:结构元的锚点,即参考点
iterations:腐蚀操作的次数,默认为一次
borderType:边界扩充类型
borderValue:边界扩充值
dilate(src, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]])把黑色变成白色
参数解析
src:表示输入矩阵
kernel:表示结构元,即 函数getStructuringElement( )的返回值
anchor:结构元的锚点,即参考点
iterations:膨胀操作的次数,默认为一次
borderType:边界扩充类型
borderValue:边界扩充值
6、边缘检测
cv2.Canny(), cv2.Laplacian(),cv2.Sobel()
7、轮廓检测
轮廓检测也是图像处理中经常用到的。OpenCV-Python接口中使用cv2.findContours()函数来查找检测物体的轮廓。
import cv2
img = cv2.imread("./test.jpg")
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray,127,255,cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img,contours,-1,(0,0,255),3)
cv2.imshow("img", img)
cv2.waitKey(0)
原图如下:

检测结果如下:

注意,findcontours函数会“原地”修改输入的图像。这一点可通过下面的语句验证:
cv2.imshow("binary", binary)
contours, hierarchy = cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
cv2.imshow("binary2", binary)
dn.net/hjxu2016/article/details/77833336
执行这些语句后会发现原图被修改了。
cv2.findContours()函数
函数的原型为
cv2.findContours(image, mode, method[, contours[, hierarchy[, offset ]]])
opencv2返回两个值:contours:hierarchy。注:opencv3会返回三个值,分别是img, countours, hierarchy。注意,findcontours函数会“原地”修改输入的图像。
参数
第一个参数是寻找轮廓的图像;
第二个参数表示轮廓的检索模式,有四种(本文介绍的都是新的cv2接口):
cv2.RETR_EXTERNAL 表示只检测外轮廓
cv2.RETR_LIST 检测的轮廓不建立等级关系
cv2.RETR_CCOMP 建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息。如果内孔内还有一个连通物体,这个物体的边界也在顶层。
cv2.RETR_TREE 建立一个等级树结构的轮廓。
第三个参数method为轮廓的近似办法
cv2.CHAIN_APPROX_NONE 存储所有的轮廓点,相邻的两个点的像素位置差不超过1,即max(abs(x1-x2),abs(y2-y1))==1
cv2.CHAIN_APPROX_SIMPLE 压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个矩形轮廓只需4个点来保存轮廓信息
cv2.CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS 使用teh-Chinl chain 近似算法

返回值
cv2.findContours()函数返回两个值,一个是轮廓本身,还有一个是每条轮廓对应的属性。
contour返回值
cv2.findContours()函数首先返回一个list,list中每个元素都是图像中的一个轮廓,用numpy中的ndarray表示。这个概念非常重要。在下面drawContours中会看见。通过
print (type(contours))
print (type(contours[0]))
print (len(contours))
可以验证上述信息。会看到本例中有两条轮廓,一个是五角星的,一个是矩形的。每个轮廓是一个ndarray,每个ndarray是轮廓上的点的集合。
由于我们知道返回的轮廓有两个,因此可通过
cv2.drawContours(img,contours,0,(0,0,255),3)
和
cv2.drawContours(img,contours,1,(0,255,0),3)
hierarchy返回值
此外,该函数还可返回一个可选的hiararchy结果,这是一个ndarray,其中的元素个数和轮廓个数相同,每个轮廓contours[i]对应4个hierarchy元素hierarchy[i][0] ~hierarchy[i][3],分别表示后一个轮廓、前一个轮廓、父轮廓、内嵌轮廓的索引编号,如果没有对应项,则该值为负数。
print (type(hierarchy))
print (hierarchy.ndim)
print (hierarchy[0].ndim)
print (hierarchy.shape)
可以看出,hierarchy本身包含两个ndarray,每个ndarray对应一个轮廓,每个轮廓有四个属性。
8、绘画轮廓
OpenCV中通过cv2.drawContours在图像上绘制轮廓。
cv2.drawContours()函数
cv2.drawContours(image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[, maxLevel[, offset ]]]]])
第一个参数是指明在哪幅图像上绘制轮廓;
第二个参数是轮廓本身,在Python中是一个list。
第三个参数指定绘制轮廓list中的哪条轮廓,如果是-1,则绘制其中的所有轮廓。后面的参数很简单。其中thickness表明轮廓线的宽度,如果是-1(cv2.FILLED),则为填充模式。绘制参数将在以后独立详细介绍。
9、特征检测
角点检测---cv2.cornerHarris(gray,2,3,0.04),Shi-Tomasi 角点检测器cv2.goodFeaturesToTrack(gray,20,0.01,10),尺度不变特征变换(SIFT),加速鲁棒特征(SURF)