有监督学习主要用于分类和回归,而无监督学习的一个非常重要的用途就是对数据进行聚类.
分类是算法基于已有标签的数据进行学习并对新数据进行分类.
聚类则是在完全没有现有标签的情况下,有算法"猜测"哪些数据像是应该"堆"在一起的,并且让算法给不同的"堆"里的数据贴上一个数字标签.
1.K均值聚类算法
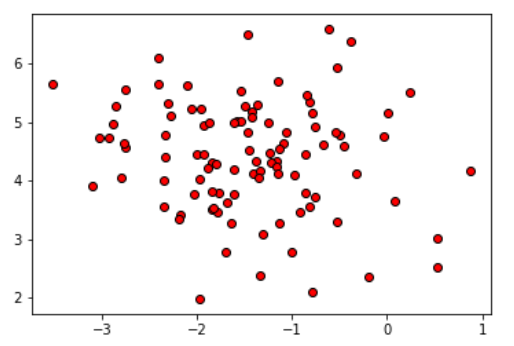
############################# K均值聚类算法 ####################################### #导入numpy import numpy as np #导入数据集生成工具 from sklearn.datasets import make_blobs #导入数据集拆分工具 from sklearn.model_selection import train_test_split #导入画图工具 import matplotlib.pyplot as plt #生成数据集为1的数据集 blobs = make_blobs(random_state=1,centers=1) X_blobs = blobs[0] #绘制散点图 plt.scatter(X_blobs[:,0],X_blobs[:,1],c='r',edgecolor='k') #显示图像 plt.show()
#导入KMeans工具 from sklearn.cluster import KMeans #要求KMeans将数据聚为3类 kmeans = KMeans(n_clusters=3) #拟合数据 kmeans.fit(X_blobs) #下面是用来画图的代码 x_min,x_max = X_blobs[:,0].min()-0.5,X_blobs[:,0].max()+0.5 y_min,y_max = X_blobs[:,1].min()-0.5,X_blobs[:,1].max()+0.5 #用不同的背景色表示不同的分类 xx,yy = np.meshgrid(np.arange(x_min,x_max,.02),np.arange(y_min,y_max,.02)) Z = kmeans.predict(np.c_[(xx.ravel(),yy.ravel())]).reshape(xx.shape) Z = Z.reshape(xx.shape) #将训练集和测试集用散点图表示 plt.figure(1) plt.clf() plt.imshow(Z,interpolation='nearest',extent=(xx.min(),xx.max(),yy.min(),yy.max()),cmap=plt.cm.summer,aspect='auto',origin='lower') plt.plot(X_blobs[:,0],X_blobs[:,1],'r.',markersize=5) #用蓝色叉号代表聚类的中心 centroids = kmeans.cluster_centers_ plt.scatter(centroids[:,0],centroids[:,1],marker='x',s=150,linewidths=3,color='b',zorder=10) plt.xlim(x_min,x_max) plt.ylim(y_min,y_max) plt.xticks(()) plt.yticks(()) #现实图片 plt.show()
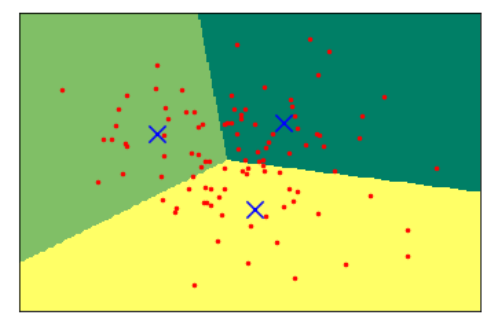
#打印KMeans进行聚类的标签
print("K均值的聚类标签:
{}".format(kmeans.labels_))
K均值的聚类标签: [2 2 1 0 0 0 2 2 1 0 2 0 2 1 2 0 0 2 1 1 0 1 2 2 2 2 0 2 2 2 1 1 2 2 0 1 0 1 2 1 0 2 1 1 0 0 0 2 1 2 1 2 0 1 0 0 1 0 0 2 0 1 0 2 1 0 1 1 2 0 0 2 0 0 0 2 0 2 2 1 0 1 0 0 1 2 0 2 1 1 0 2 1 1 0 0 2 0 0 2]
- K均值算法聚类很好理解,其聚类和分类很相似,是用0,1,2三个数字来代表数据的类.
- 但是它也有明显的局限性,如,它认为每个数据点到聚类中心的方向都是同等重要的,这样一来,对于"形状"复杂的数据集来说,K均值算法就不是很友好了
2.凝聚聚类算法
############################# 凝聚聚类算法 #######################################
#导入dendrogram和ward工具
from scipy.cluster.hierarchy import dendrogram,ward
#使用连线的方式进行可视化
linkage = ward(X_blobs)
dendrogram(linkage)
ax = plt.gca()
#设定横纵轴标签
plt.xlabel("Sample index")
plt.ylabel("Cluster distance")
#显示图像
plt.show()

- 凝聚聚类算法是自上而下,不断的合并相似的聚类中心,以便让类别越来越少,同时每个聚类中心的距离也就越来越远.这种逐级生成的聚类方法称为Hierarchy clustering.
3.DBSCAN聚类算法
"基于密度的有噪声应用空间聚类"(Density-based spatial clustering of applications with noise,DBSCAN)
- DBSCAN是通过对特征空间内的密度进行检测,密度大的地方它会认为是一个类,而密度相对小的地方它会认为是一个分界线.
############################# DBSCAN聚类算法 #######################################
#导入DBSCAN
from sklearn.cluster import DBSCAN
db = DBSCAN()
#使用DBSCAN拟合数据
clusters = db.fit_predict(X_blobs)
#绘制散点图
plt.scatter(X_blobs[:,0],X_blobs[:,1],c=clusters,cmap=plt.cm.cool,s=60,edgecolor='k')
#设定横纵轴标签
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
#显示图像
plt.show()
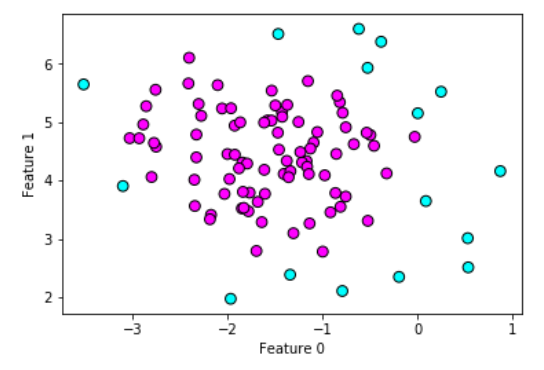
#打印聚类个数
print('
聚类标签为:
{}
'.format(clusters))
聚类标签为: [-1 0 -1 0 -1 0 0 0 0 0 0 0 0 0 -1 0 0 0 0 0 0 0 0 0 0 -1 0 0 -1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 -1 0 0 0 0 0 0 0 0 0 -1 0 0 0 0 0 0 -1 0 0 0 0 0 0 0 0 0 -1 -1 0 0 0 0 -1 0 0 -1 0 0 -1 0 0 0 0 0 0 0 0 -1 0 0 0 -1]
#设置DBSCAN的eps参数为2
db_1 = DBSCAN(eps = 2)
#重新拟合数据
clusters_1 = db_1.fit_predict(X_blobs)
plt.scatter(X_blobs[:,0],X_blobs[:,1],c=clusters_1,cmap=plt.cm.cool,s=60,edgecolor='k')
#设定横纵轴标签
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
#显示图像
plt.show()
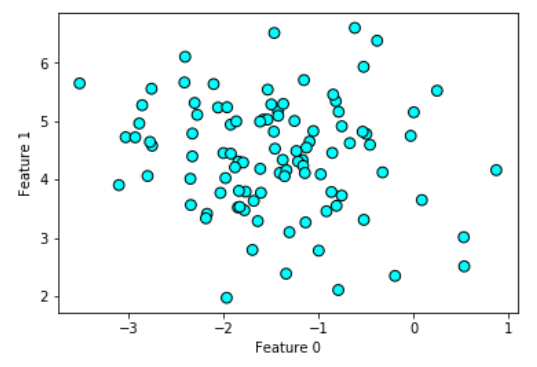
#设置DBSCAN的eps参数为2
db_2 = DBSCAN(min_samples = 20)
#重新拟合数据
clusters_2 = db_2.fit_predict(X_blobs)
plt.scatter(X_blobs[:,0],X_blobs[:,1],c=clusters_2,cmap=plt.cm.cool,s=60,edgecolor='k')
#设定横纵轴标签
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
#显示图像
plt.show()
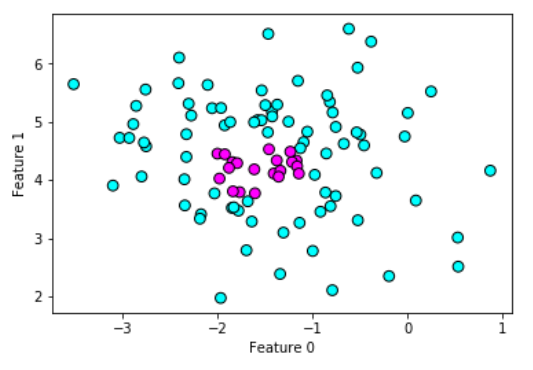
DBSCAN中两个非常重要的参数:
- 一是eps
- 一是min_samples
eps指定的是考虑划入同一"坨"的样本距离有多远,eps值设置得越大,则聚类所覆盖的数据点越多,反之则越少.(默认情况下eps的值为0.5)
总结 :
对于没有分类标签的数据来说,无监督学习的聚类算法可以帮助我们更好的理解数据集,并且为进一步训练模型打好基础.
文章引自 : 《深入浅出python机器学习》