在传递数据时,XML和JSON是最常用的数据格式,SQL Server从很早的版本就开始支持XML格式,而对于JSON格式,SQL Server从2016版本开始支持。大多数数据库系统并没有升级到SQL Server 2016版本,因此在传递格式化的数据时,通常还是使用XML格式。对我而言,查询和解析XML格式的数据需要掌握的知识点较多,MSDN上关于XML的文档,又试图把XML的各个方面都讲解地清清楚楚,以至于内容冗杂,使学习过程变得困难。我十分不喜欢学习这些不常用的数据结构,再说,在平时的数据库开发中,用到XML的地方也很少,可是,一旦在应用程序中用到XML,就只有头疼的份了,既然避不开XML,那就用最简单的方法学习它,了解它,使用它,以备不时之需。写这篇文章,就是以最简单的方式,分享XML最常用的使用方法。
一,XML数据格式的简单介绍
1,最简单的XML格式
XML数据最简单的格式是:
- 开始标签:<tag>
- 标签的属性,属性值用双引号:<tag id="1" name="azure">,在单个节点中,属性名不能重复,属性之间使用空格分隔,在开始标签中,才能设置属性;
- 结束标签:</tag>,结束标签不能有属性;
- 子节点:在开始标签和结束标签,可以包含节点,叫做子节点;
- 节点值:在开始标签和结束标签的标量值,叫做节点值;
2,使用字符串对XML数据赋值
数据类型XML用于存储XML格式化的文本数据,在本例中,声明一个XML类型的变量 @xml,并赋值,后文示例都使用该变量用于数据查询。

declare @xml xml
set @xml='
<Expression ID="1" TaxonomyID="1">
<SubExpression ID="1" OperandType="Tag" Operator="and">
<Oprand ID="268819" Name="abuse" />
<Oprand ID="277029" Name="mongohq" />
<Oprand ID="516813" Name="access" />
</SubExpression>
<SubExpression ID="2" OperandType="Tag" Operator="and">
<Oprand ID="283839" Name="reviews" />
<Oprand ID="697348" Name="retention" />
</SubExpression>
<SubExpression ID="3" OperandType="Tag" Operator="not">
<Oprand ID="281556" Name="richfaces" />
<Oprand ID="2993766" Name="rgp" />
</SubExpression>
</Expression>'
二,XPath路径表达式
XPath 使用路径表达式在 XML 文档中选取节点,节点是通过沿着路径选取的,XPath是查询XML数据时必备的参数。
常用的路径表达式是:
- . :选取当前节点;
- .. :选取当前节点的父节点;
- / :从根节点开始;
- // :从匹配选择的节点开始选取,而不考虑其位置;
- * :通配符,匹配任意字符,或任意节点;
- node() :匹配任意节点,跟通配符 * 功能相似;
- @PropertyName :选取属性;
在路径表达式中,跟节点的选取有关的表达式是:
- NodeName:选取指定节点名及其所有子节点;
- NodeName[N]:选取指定节点集合的第N个节点;
- NodeName[@Name]:选取当前节点中带有指定属性的节点;
三,XML数据的查询(query()函数)
@xml.query(’xpath‘)函数,参数是路径表达式,返回XML数据类型的结果,该XML是非类型化(untyped)的。
1,选取节点及其子节点
示例中,从根节点Expression开始,选取SubExpression节点及其子节点:
select @xml.query('/Expression/SubExpression')
query()函数返回的结果如下,该查询结果是非类型化的XML数据。
<SubExpression ID="1" OperandType="Tag" Operator="and"> <Oprand ID="268819" Name="abuse" /> <Oprand ID="277029" Name="mongohq" /> <Oprand ID="516813" Name="access" /> </SubExpression> <SubExpression ID="2" OperandType="Tag" Operator="and"> <Oprand ID="283839" Name="reviews" /> <Oprand ID="697348" Name="retention" /> </SubExpression> <SubExpression ID="3" OperandType="Tag" Operator="not"> <Oprand ID="281556" Name="richfaces" /> <Oprand ID="2993766" Name="rgp" /> </SubExpression>
2,选取指定节点的所有子节点集合
select @xml.query('/Expression/SubExpression/node()')
select @xml.query('/Expression/SubExpression/*')
结果集是SubExpression节点下的所有子节点:
<Oprand ID="268819" Name="abuse" /> <Oprand ID="277029" Name="mongohq" /> <Oprand ID="516813" Name="access" /> <Oprand ID="283839" Name="reviews" /> <Oprand ID="697348" Name="retention" /> <Oprand ID="281556" Name="richfaces" /> <Oprand ID="2993766" Name="rgp" />
四,XML数据的查询(value()函数)
@xml.value('xpath','sql_data_type'),返回XML数据中单个属性的标量值,在使用value()函数时,xpath 参数必须指定返回的是单个值,而value()函数不会去check返回值的数量。
一般情况下,即使xml数据只有一个属性值,静态类型化(Static typing)要求,xpath表达式也必须显式指定返回单个标量值,因此,必须指定在xpath函数的末尾添加”[1]“,通常的xpath表达式是”(xpath)[1]“。
select @xml.value('(/Expression/SubExpression[1]/@ID)[1]','int')
select @xml.value('(/Expression/SubExpression/@ID)[1]','int')
五,XML数据的查询(nodes()函数)
@xml.nodes ('xpath') 函数返回节点的集合,用于把XML数据转换为关系数据表,返回的每一个行都是XML数据类型,语法是:
nodes ('xpath') as table(column)
通过nodes()函数,返回SubExpression节点及其属性,由于单个节点中,属性名不可能重复,因此,在nodes()函数返回的单个节点中,不需要通过xpath路由,直接获取当前节点的属性值,这样,可以在xpath表达式中直接指定属性,不需要显式以“[1]”结尾。
示例代码如下,在value()函数中,直接指定属性值,表示获取当前节点的属性值:
select t.v.query('.') as SubExpression
,t.v.value('@ID','int') as SubExpressionID
,t.v.value('@OperandType','varchar(16)') as OperandType
,t.v.value('@Operator','varchar(16)') as Operator
from @xml.nodes('/Expression/SubExpression') as t(v)

通过cross apply 连接操作,把SubExpression节点下的所有数据都转换为关系型数据,并把该数据存储到临时数据表#Expressions中:
 View Code
View Code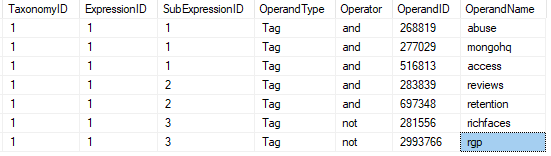
六,把行集数据转化为XML数据(for xml path)
把行集数据转化为XML数据,需要用到for xml path子句,该子句的特点是:
- path('root') 子句用于指定根节点;
- select子句的字段别名用于指定属性,别名中必须使用@符号标识出属性名,例如:'@PropertyName';
- 在select 子句中,如果不在别名中把字段指定为属性,那么该字段的值作为节点值,节点值分为标量类型和XML类型;
- 对于标量类型,节点值是标量值;
- 对于XML类型,节点值是子节点的集合;
例如,要把数据转换为如下的关系型数据结构,其SubExpression字段是一个非类型化的XML数据,要完成这样的数据转换,必须使用for xml path子句和cast()类型转换:

<SubExpression ID="1" OperandType="Tag" Operator="not"> <Oprand ID="268819" Name="abuse" /> <Oprand ID="277029" Name="mongohq" /> <Oprand ID="516813" Name="access" /> </SubExpression> <SubExpression ID="2" OperandType="Tag" Operator="not"> <Oprand ID="283839" Name="reviews" /> <Oprand ID="697348" Name="retention" /> </SubExpression> <SubExpression ID="3" OperandType="Tag" Operator="not"> <Oprand ID="281556" Name="richfaces" /> <Oprand ID="2993766" Name="rgp" /> </SubExpression>
使用类型转换的目的,是为了把for xml path返回的字符串转换成XML数据类型,这样,就能以XML格式嵌入到上次的for xml path的结构中,作为子节点:
View Code还有两个函数modify()和exist(),用于XML数据的修改和检查,由于在我当前接触的项目中,没有用到过,我就不写了。
到此,文章也该结尾了,XML的极简用法已经总结了很多,在以后工作中国,如果用到XML时,翻开这篇文章,能够快速解决XML常见的数据查询和解析问题,这样就足够了。
参考文档: