前言
承接上文Java并发包同步工具之Phaser,讲述了同步工具Phaser之后,搬家博客到博客园了,接着未完成的Java并发包源码探索,接下来是Java并发包提供的最后一个同步工具Exchanger。
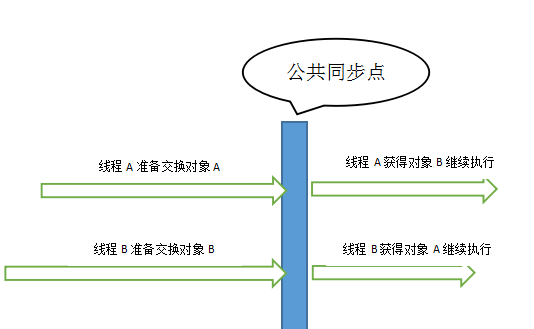
Java并发包中的Exchanger由来已久,从JDK1.5就存在了,但是到了JDK8实现方式已经大不一样了,这里以JDK8的源码分析其实现原理,Exchanger顾名思义就是交换器的意思,它是为了实现不同线程之间安全交换数据的工具,要交换数据当然线程的是成对的,最少一对线程,多则N对线程,以一对线程举例:当两个线程拿着各自准备交换的数据到达一个公共的同步点时,Exchanger就能够安全的将它们各自的数据交换,从而使两个线程分别获取到对方的数据。
使用示例
Exchanger的使用非常简单,我这里以一个最简单的示例来演示一下一对线程的数据交换:


public static void main(String[] args){ Exchanger<String> exchanger = new Exchanger(); new Thread(){ @Override public void run() { try{ String data = exchanger.exchange("AAAA"); System.out.println("A线程得到的数据:"+data); }catch (Exception e){ e.printStackTrace(); } } }.start(); new Thread(){ @Override public void run() { try{ String data = exchanger.exchange("BBBB"); System.out.println("B线程得到的数据:"+data); }catch (Exception e){ e.printStackTrace(); } } }.start(); }
通过上面的示例,最终A线程将会得到B线程的数据"BBBB" ,B线程将会得到A线程的数据"AAAA",根据JDK的描述,Exchanger主要用于遗传算法和管道设计等场景,因为Exchanger同时支持多对线程进行数据交换,而不单单是像我这个例子这样简单。
源码分析
Exchanger的使用非常简单,但是它的源码实现逻辑却不简单,要理解它的源码实现还是非常有难度的,在分析源码之前,我们通过Java Doc可以了解到它可以看做是SynchronousQueue的双向形式,Exchanger的实现分为单槽位交换与多槽位交换数据,所谓的槽位“slot”其实就是一个存储待交换数据的内存区域,单槽位交换就是为了满足简单的一对线程进行数据交换,试想如果有多对线程参与数据交换如果还使用一个数据槽位进行数据交换,那对性能将是多么严重的影响就像多个线程同时更改一个原子变量一样,所以针对这种情况,Exchanger将会开辟多个槽位用于那些线程进行两两交换。
构造方法
1 //构造方法 2 public Exchanger() { 3 participant = new Participant(); 4 } 5 6 //对应的线程,每个线程就是一个参与者,内部用一个Node对象来保存线程的相关数据 7 static final class Participant extends ThreadLocal<Node> { 8 public Node initialValue() { return new Node(); } 9 } 10 11 /** 12 * Per-thread state 13 */ 14 private final Participant participant; 15 16 /** 17 * Nodes hold partially exchanged data, plus other per-thread 18 * bookkeeping. Padded via @sun.misc.Contended to reduce memory 19 * contention. 20 * 每个线程用于交换的相关数据 21 */ 22 @sun.misc.Contended static final class Node { 23 int index; // 多槽位Arena的索引,用于多槽位 24 int bound; // 记录上一次的边界bound,用于多槽位 25 int collides; // 在当前边界bound内CAS失败的次数,用于多槽位 26 27 int hash; // 用于线程自旋的伪随机数 28 Object item; // 当前线程携带的用于交换的数据对象 29 volatile Object match; // 被交换线程用于交换的数据对象(后到达的交接线程将会把自己需要交接的数据设置与之交接的线程的该字段上) 30 volatile Thread parked; // 当阻塞等待交换时设置的阻塞对象,就是自身。 31 } 32 33 /** 34 * Slot used until contention detected. 35 * 单槽位用于交换数据的槽位 36 */ 37 private volatile Node slot;
构造方法非常简单,仅仅是创建了一个参与者participant,它继承自ThreadLocal使用线程本地变量保存线程用于交换的数据节点Node,而且槽位slot也是Node类型,所以其实Node节点对象就是实现数据交换时在内存槽位中存储的数据模型。
Node节点对象被Contended注解修饰,这样是为了避免伪共享,将整个槽位与其他数据存储分隔开来,避免因为其他缓存数据的失效与更新导致对整个缓存行的数据的重新加载,从而降低程序运行效率。
exchange入口方法
1 public V exchange(V x) throws InterruptedException { 2 Object v; 3 Object item = (x == null) ? NULL_ITEM : x; // translate null args 4 if ((arena != null || 5 (v = slotExchange(item, false, 0L)) == null) && 6 ((Thread.interrupted() || // disambiguates null return 7 (v = arenaExchange(item, false, 0L)) == null))) 8 throw new InterruptedException(); 9 return (v == NULL_ITEM) ? null : (V)v; 10 }
该方法就是Exchanger对外提供的两个使用方法之一,另一个只是增加了对超时机制的实现基本逻辑都是一样,这里就只针对这个方法进行阐述, 首先,Exchanger支持交换空对象,但是对空对象进行了处理,以一个NULL_ITEM来代替空对象执行内部的交换逻辑,其实还有个TIMED_OUT对象用于标识发生了超时,以两个特殊的对象来表述特殊的情况只是为了内部实现的方便。变量arena就是用于多槽位交换的Node数组对象,默认情况下是没有开启多槽位交换机制的,所以它是null,slotExchange方法就是单槽位交换实现,而arenaExchange则是多槽位实现逻辑,所以这个方法的逻辑过程如下:
多槽位没有开启时(arena为空),执行单槽位交换slotExchange。多槽位不为空或者单槽位交换失败(被中断,发生了竞争)时,如果被中断就抛出中断异常,如果发生竞争就执行多槽位交换逻辑arenaExchange
总之一句话,在多槽位没有开启之前默认执行单槽位方式交换,发生竞争才执行多槽位方式交换。过程中若发生了中断抛出中断异常。
单槽位交换slotExchange
1 /** 2 * 单槽位交换函数, 3 * 正常情况下返回的是另一个线程交换的对象,在产生竞争或者在完成之前被中断返回null,超时返回TIMED_OUT对象。 4 */ 5 private final Object slotExchange(Object item, boolean timed, long ns) { 6 Node p = participant.get(); //得到一个初始Node 7 Thread t = Thread.currentThread(); 8 if (t.isInterrupted()) // 如果发生了中断,返回null,isInterrupted不会复位中断中断,所以在exchange方法中可以继续使用Thread.interrupted()来检测其中断状态 9 return null; 10 11 for (Node q;;) { 12 //该slot槽位不为空,表示已经被先来一步的等待交换数据的线程占据 13 if ((q = slot) != null) { 14 //交换数据之前,尝试将被占据的槽位重置为空 15 if (U.compareAndSwapObject(this, SLOT, q, null)) { 16 Object v = q.item; //拿到别人的数据 17 q.match = item; //将自己的数据给别人 18 Thread w = q.parked; 19 if (w != null) 20 U.unpark(w); //唤醒别人 21 return v; //拿到交换的数据了,返回 22 } 23 // create arena on contention, but continue until slot null 24 if (NCPU > 1 && bound == 0 && 25 U.compareAndSwapInt(this, BOUND, 0, SEQ)) 26 arena = new Node[(FULL + 2) << ASHIFT]; 27 } 28 else if (arena != null) //单槽位为空,但是多槽位不为空表示发生了竞争,需要执行多槽位交换逻辑 29 return null; // caller must reroute to arenaExchange 30 else { 31 //单槽位还没被占据,那么带着自己想交换的数据尝试占据该槽位 32 p.item = item; 33 if (U.compareAndSwapObject(this, SLOT, null, p)) 34 break; //成功占据该槽位,退出自旋。 35 p.item = null; //占据失败,清除数据继续自旋。 36 } 37 } 38 39 //执行到这里,表示最先来交换的线程已经成功占据了单槽位,所以需要将自己阻塞(阻塞之前可以适当自旋),直到另一个交换线程来释放它。 40 // await release 41 int h = p.hash; 42 long end = timed ? System.nanoTime() + ns : 0L; 43 int spins = (NCPU > 1) ? SPINS : 1; //自旋次数,如果是单核CPU将不会自旋 44 Object v; 45 while ((v = p.match) == null) { //表示除非等到另一个交换线程将要交换的数据设置到match才跳出循环 46 if (spins > 0) { 47 h ^= h << 1; h ^= h >>> 3; h ^= h << 10; 48 if (h == 0) 49 h = SPINS | (int)t.getId(); 50 else if (h < 0 && (--spins & ((SPINS >>> 1) - 1)) == 0) 51 Thread.yield(); //主动让出cpu 52 } 53 else if (slot != p) //其他线程来交换数据了(上面for循环里面交换数据之前会将槽位重置为空),但是match还没有被设置 54 spins = SPINS; //设置自旋等待的次数 55 else if (!t.isInterrupted() && arena == null && 56 (!timed || (ns = end - System.nanoTime()) > 0L)) { 57 //自旋等待太久,迫不得已,在没被中断,没有竞争,且超时未到达时将自己阻塞起来吧。 58 U.putObject(t, BLOCKER, this); 59 p.parked = t; 60 if (slot == p) 61 U.park(false, ns); //阻塞 62 p.parked = null; 63 U.putObject(t, BLOCKER, null); 64 } 65 //执行到这里表示被中断或者超时了或者产生了竞争,所以要退出循环了,但是先要重置槽位slot 66 else if (U.compareAndSwapObject(this, SLOT, p, null)) { 67 v = timed && ns <= 0L && !t.isInterrupted() ? TIMED_OUT : null; 68 break; 69 } 70 } 71 //一些清理工作 72 U.putOrderedObject(p, MATCH, null); 73 p.item = null; 74 p.hash = h; 75 return v; //返回交换得到的数据(失败则为null) 76 }
单槽位交换的逻辑比较简单,该方法里面有一个for循环和一个while循环,在单槽交换时,先执行该方法的线程两个循环都会执行,后执行该方法的线程只会执行第一个for循环。
先执行的线程,在单槽位逻辑中会先带着自己需要交换的数据占据槽位slot,然后等待另一个线程执行该方法来交换数据,在等待过程中先尽量通过自旋+yield方式等待,迫不得已才进行阻塞等待另一个交换线程来唤醒。
后执行的线程,发现单槽位已经被占据,表示别人已经准备好了,那么在交换之前先将槽位置空,然后交换数据,最后把先执行的那个线程唤醒。
在单槽位逻辑中,先执行的线程如果在等待交换的过程中发生了中断或者等待超时或等待中发现产生了竞争,那么会清空被自己占据的槽位然后立即返回(如果是被中断或者超时最终会抛出相应的异常)。当然任何线程在交换之前发生了中断也会抛出中断异常。在单槽位交换中,只要发生了竞争那么所有线程都将立即从该方法返回,然后转入多槽位交换逻辑。
注意Node对象的item属性并没有被volatile修饰,这是因为对它的读操作都是发生在CAS操作之后,对其的写操作都是发生在CAS操作之前,所以能够保证对该变量的可见性,所以就没有必要将其用volatile修饰,从而减小系统运行开支。
多槽位交换arenaExchange
单槽位交换的逻辑非常简单,Exchanger在实现数据交换时总是默认采用单槽位交换,只有发生了竞争才会开启多槽位交换,毕竟多槽位交换复杂度高并且占用系统资源多,所谓的多槽位其实就是开辟了一个槽位数组,不同的线程定位到数组的不同下标进行数据数据交换,当然这只是一个基本的思想,它的实现过程远远没有这么简单,为了彻底理解多槽位交换的逻辑,我们一步步的来分析。在核心代码之前,我们需要先了解相关的一些基础的辅助变量:
private volatile Node[] arena; //表示多槽位的数组 private volatile int bound; //表示当前槽位数组的界限 //两个有效槽位之间的字节地址长度,1 << 7 至少是缓存行的大小 private static final int ASHIFT = 7; //最大支持的数组索引,即255,二进制低八位8个1 private static final int MMASK = 0xff; //bound的递增单元,每次递增都会同时递增低8位和高8位 private static final int SEQ = MMASK + 1; //CPU个数,用于控制自旋和多槽位数组的大小 private static final int NCPU = Runtime.getRuntime().availableProcessors(); //实际支持的最大有效索引 static final int FULL = (NCPU >= (MMASK << 1)) ? MMASK : NCPU >>> 1; //自旋次数,实际上单核CPU的时候没启用自旋 private static final int SPINS = 1 << 10;
上面的变量不是很好理解,先继续往下看,在多槽位交换机制中,初始化槽位数组的过程在单槽位交换方法slotExchange中,如下:
if (NCPU > 1 && bound == 0 && U.compareAndSwapInt(this, BOUND, 0, SEQ)) arena = new Node[(FULL + 2) << ASHIFT];
可以看到,在初始化槽位数组arena之前,先要进行CPU核心个数判断,单核心CPU是不能开启多槽位交换模式的,然后对bound进行了初始化成SEQ,SEQ= MMASK+1=256=100000000(二进制),这个bound其实由两部分组成,二进制低8位用于表示当前arean数组的最大有效索引值,例如现在,bound二进制100000000的低8位都是0,通过bound&MMASK运算,MMASK二进制是8个1,结果就是bound低8位表示的数值0,即在初始化之后数组的最大有效索引就是0,就是只能存放一个有效槽位,这里的有效槽位是什么意思呢?其实就是为了避免伪共享,由于数组元素在分配内存的时候大都是地址连续的,为了避免伪共享,所以在实际存放数据的时候并不会将我们的槽位按顺序存储,而是会按间隔一个缓存行的长度进行存储,两个有效数据之间就由填充数据占据,所以数组中真正可用于存储的下标会很少。
解决了bound的低8位,那么高8位呢?高8位其实是一个版本号的概念,虽然这里的arean数组初始化的长度为 (FULL + 2) << ASHIFT,但是并不是说我们从开始到结束都可以利用该数组所有可利用的下标进行存取,为什么呢?试想如果竞争不是很激烈,数组长度又很大,某个线程占据了某个槽位,剩下空的槽位很多,所以其他来交换的线程很难刚好也寻找到了同一个槽位从而交换成功,很大可能是重新找了一个空槽位也傻傻的等待着别人来交换,虽然Exchanger在实现中会把那些等待太久的线程不断往下标0压缩,从而迫使它们尽快发生交换,但这明显不是最高效的,所以arean数组表面上看起来大小是固定的,其实在内部存储的时候会动态的对数组的大小进行限制,竞争激烈的时候它就扩张,竞争稍缓或者等待交换的线程等待太久就会压缩数组大小,对于扩张的策略是,只有当线程在当前数组的特定有效槽位(bound低8位)情况下,如果线程已经在每一个有效槽位上都进行了尝试交换但是都由于竞争激烈而失败时才扩张数组的实际有效槽位(扩张不会超过初始化的长度),交换失败的次数可以由CAS失败之后Node对象的collides字段记录,那么对应的特定有效槽位则就是bound的高8位来记录,数组的实际有效槽位在不断的变大变小,例如加1后再减1,如果没一个版本号的概念,就相当于存在了ABA的问题。每一个版本的bound都需要重新记录CAS失败的次数collides,所以当bound发生变化之后,都会将collides重置为0.
关于数组实际有效槽位的扩张和缩减是由下面这两个个计算逻辑进行的:
U.compareAndSwapInt(this, BOUND, b, b + SEQ + 1) //扩张1
U.compareAndSwapInt(this, BOUND, b, b + SEQ - 1) //缩减1
每一次都是在原来的基础上 增加 SEQ +1 , 其实就是分别将bound的低8位和高8位都增加了1,例如:100000000 (初始值) -> 1000000001 (扩张1)-> 1100000010 (再扩张1) -> 10000000001 (缩减1) ......, 不论低8位的实际有效槽位怎么变化,高8位表示的版本号都是不断增长的。
接下来,看看arean数组的有效索引以及对有效索引位的存取方式。上面arean的初始长度是 (FULL + 2) << ASHIFT, 其实实际最多有效索引就是FULL+2个,因为Exchanger按每两个有效索引位之间间隔一个缓存行 1 << ASHIFT的大小来存储,例如:我的笔记本是双核四线程的,NCPU=4,FULL=2, arean数组的长度 (FULL + 2) << ASHIFT = 512, 每两个有效索引间隔 1 << ASHIFT = 128, 假设数组的第一个元素内存偏移地址是0, 那么有效的索引位依次就是:...(填充)..128...(填充)..256.....384.....512. 即最多只有4个有效索引,Exchanger内部其实限制最大只能到FULL,因此不会发生越界。从下面的根据线程取索引编号也可以印证这一点:
Node q = (Node)U.getObjectVolatile(a, j = (i << ASHIFT) + ABASE); //i 从0 开始最多递增到 m,m = bound & MMASK,不就是128, 256, 384, 512吗
关于避免伪共享,Exchanger只是以大多数常见缓存行都是128个地址偏移来编写代码,而且Exchanger还对不满足这种情况进行了处理,那就是在构造实例的时候就会抛出异常:
static { try { ......//省略 s = U.arrayIndexScale(ak); //arean数组元素的增量地址长度 // ABASE absorbs padding in front of element 0。数组首元素偏移地址 ABASE = U.arrayBaseOffset(ak) + (1 << ASHIFT); } catch (Exception e) { throw new Error(e); } if ((s & (s-1)) != 0 || s > (1 << ASHIFT)) //不支持避免伪共享,抛异常 throw new Error("Unsupported array scale");
OK, 将多槽位交换相关的东西介绍完了,下面看真正的实现逻辑:
private final Object arenaExchange(Object item, boolean timed, long ns) { Node[] a = arena; Node p = participant.get(); //获取当前线程对于的Node对象 for (int i = p.index;;) { // 根据线程对于的index访问数组的有效槽位 int b, m, c; long j; // j 是包括填充在内的偏移 //获取偏移地址为(i << ASHIFT) + ABASE的内存值,就是实际有效的槽位 Node q = (Node)U.getObjectVolatile(a, j = (i << ASHIFT) + ABASE); if (q != null && U.compareAndSwapObject(a, j, q, null)) { //这里说明已经有线程在等着交换了,当前线程先重置该槽位,然后再和它交换 Object v = q.item; // 取出等待线程携带的数据 q.match = item; // 将当前线程携带的数据交给等待线程 Thread w = q.parked; if (w != null) U.unpark(w); // 唤醒等待线程 return v; // 交换成功,返回得到的数据 } //否则,当前位置再实际有效索引之内,并且槽位还没被占据 //m = bound & MMASK, 就是bound低8位表示的当前最大有效索引 else if (i <= (m = (b = bound) & MMASK) && q == null) { p.item = item; // 把准备交换的数据设置好,一旦占据槽位成功就可以等着被交换了 if (U.compareAndSwapObject(a, j, null, p)) { // 槽位占据成功 long end = (timed && m == 0) ? System.nanoTime() + ns : 0L; //计算超时时间 Thread t = Thread.currentThread(); // wait for (int h = p.hash, spins = SPINS;;) { Object v = p.match; //match就是来交换的线程携带的数据 if (v != null) { //已经有线程来交换了 U.putOrderedObject(p, MATCH, null); p.item = null; // 清空,下次接着使用 p.hash = h; return v; // 交换成功,返回得到的数据 } else if (spins > 0) { //自旋 + yield h ^= h << 1; h ^= h >>> 3; h ^= h << 10; // xorshift if (h == 0) // initialize hash h = SPINS | (int)t.getId(); else if (h < 0 && // approx 50% true (--spins & ((SPINS >>> 1) - 1)) == 0) Thread.yield(); // two yields per wait } else if (U.getObjectVolatile(a, j) != p) spins = SPINS; //交换线程已经来了,正在准备数据,继续自旋,马上就可以交换成功 else if (!t.isInterrupted() && m == 0 && (!timed || (ns = end - System.nanoTime()) > 0L)) { //等太久了,没有打断,没有超时,而且已经再0这个最左侧的有效索引位了 U.putObject(t, BLOCKER, this); // emulate LockSupport p.parked = t; // minimize window if (U.getObjectVolatile(a, j) == p) U.park(false, ns); //只有阻塞等待唤醒了 p.parked = null; U.putObject(t, BLOCKER, null); } else if (U.getObjectVolatile(a, j) == p && U.compareAndSwapObject(a, j, p, null)) { //超时或打断或不是在最左侧0这个有效索引位 if (m != 0) // 不是在最左侧的0索引位,那么有效索引位减1,bound版本号会加1 U.compareAndSwapInt(this, BOUND, b, b + SEQ - 1); p.item = null; p.hash = h; i = p.index >>>= 1; // 索引也减半,这样可以快速找到交换点 if (Thread.interrupted()) return null; //中断返回 if (timed && m == 0 && ns <= 0L) return TIMED_OUT; //超时返回 break; // 跳出等待内循环,重新开始 } } } else p.item = null; //槽位占据失败,清理之后重试 } else { //到这里还是失败,那只有重新从右往左遍历,以期望能够发生交换了 if (p.bound != b) { //bound已经发生变化了, p.bound = b; //更新自身的bound p.collides = 0; //重置CAS失败次数 i = (i != m || m == 0) ? m : m - 1; //这里的i,其实就是当i已经在最右边的最大有效索引了,就减一继续往左查找,否则重新从最右侧的最大索引开始往左查找 } //CAS失败次数已经达到最大了,也就是在每一个有效索引位都失败了,并且当前最大有效索引位还没有到达FULL,就扩大有效索引位 else if ((c = p.collides) < m || m == FULL || !U.compareAndSwapInt(this, BOUND, b, b + SEQ + 1)) { p.collides = c + 1; //本次失败了,CAS失败次数加1 i = (i == 0) ? m : i - 1; // 还是在左移i,i已经到最左侧了,重新从最右侧开始往左遍历 } else i = m + 1; //bound加1成功了,实际最大有效索引位扩张了,那么可以去占据新出炉的空的有效索引位 p.index = i; } } }
多槽位交换的源码分析印证了上面的描述,但是实现的过程真的有点难懂,也可以用精妙来形容,通过上面的源码可以得出以下几个重要的实现细节:
1. 关于槽位的增长,由U.compareAndSwapInt(this, BOUND, b, b + SEQ + 1)语句完成,分别对高8位版本号加1和低8位最大有效索引加1,只有在当前线程在每一个有效索引位都尝试失败(这时候collides==m,m就是当前bound下最大有效索引)之后才会触发槽位的增长,当然有效槽位最大不能超过FULL,槽位增长之后,如果当前处于最左侧0索引,那么就定位到最大索引m处,否则 i-1 即继续往左侧移动进行尝试。
2. 关于槽位的缩减,由U.compareAndSwapInt(this, BOUND, b, b + SEQ - 1)语句完成,分别对高8位版本号加1和低8位最大有效索引减1,只有在当前线程在非0索引位处等待了一段时间都没有等到线程来交换才会尝试缩减槽位(由于实际使用槽位并没有真正到达FULL +2,而是到FULL截至,所以不用担心丢失有效节点),槽位缩减之后,当前线程的索引也会减半,使其往左寻找槽位,这样就增大了交换成功的机率。
3. 关于线程的动态移动,不论槽位缩减还是增长之后,都会重置还没有占据槽位的那些线程的索引以及冲突失败次数collides,对于索引的重置策略是只要不是处于最大索引 m 处,那么就会将其重新定位到最右侧m处,否则定位到m-1,总之线程节点都是在不停的从右往左流动的过程。如果失败次数还没有达到最大(collides < m)或者槽位已经到达最大FULL,或者扩张槽位失败,那么当前线程只要还没到达最左侧的0索引位,那么就将索引减1,继续往左靠。
4. 关于0索引位,这是一个很关键的槽位,你会发现所有的线程节点都会在等待交换的过程中,只要没有成功就向左靠近,所有的线程阻塞都只会发生在0索引槽位,所以在该处交换成功的几率非常高,而在其它有效槽位只会以 spin + yield 的方式进行等待。
内存一致性
由于Exchanger内部在实现交换的时候采用了CAS+volatile对槽位进行更新替换,所以很容易得出通过Exchanger成功交换的每一对线程,每一个线程在调用exchange()方法之前的操作都 happen-before 另一个线程在exchange()方法返回之后的操作。
所以交换成功的每对线程中的任何一方在其exchange方法返回之后都可见另一个线程在调用exchange方法之前的操作。
总结
Exchanger的数据交换内部实现策略支持两个线程情况下的单槽位交换,以及多线程情况下的多槽位交换,在多槽位交换过程中,每个线程最终会和哪一个线程交换是不能确定的,它只能保证能够两两成功交换。单槽位交换很简单,当线程来交换数据的时候,如果发现槽位为空,则以spin + yield + block的方式进行等待,否则就和占据槽位的线程进行交换,然后唤醒等待的线程拿着数据返回。
多槽位的思想其实也好理解,只是它的实现过程非常精细而复杂,当线程来交换数据的时候,如果第一个有效槽位为空,那么占据槽位以spin + yield + block的方式等待,如果发现第一个有效槽位非空,那么就尝试和其进行交换,如果交换失败,说明已经有其它线程抢先尝试与其交换了,那么就往后移动一个有效槽位,如果此处被占据则尝试与其交换,否则就以spin + yield的方式等待,注意此时不会进入block状态,如果等待自旋结束依然没有线程来交换,则往左移动索引,如果在往左移动的过程中一直没有成功与那些槽位交换,最终移动到第一个有效槽位,那又以spin + yield + block的方式进行等待, 当然内部实现机制还会涉及到对多槽位数组有效容量的动态扩展和缩减,以及移动线程节点的过程中的数组容量版本号与交换失败记录的对比等等精密逻辑。
其它参考连接:
http://m.debug8.com/java/t_2767.html