Edge Intelligence: On-Demand Deep Learning Model Co-Inference with Device-Edge Synergy
转载自:https://www.cnblogs.com/alpaca/p/9635620.html
边缘智能:按需深度学习模型和设备边缘协同的共同推理
本文为SIGCOMM 2018 Workshop (Mobile Edge Communications, MECOMM)论文。
笔者翻译了该论文。由于时间仓促,且笔者英文能力有限,错误之处在所难免;欢迎读者批评指正。
本文及翻译版本仅用于学习使用。如果有任何不当,请联系笔者删除。
本文作者包含3位,En Li, Zhi Zhou, and Xu Chen@School of Data and Computer Science, Sun Yat-sen University
ABSTRACT (摘要)
As the backbone technology of machine learning, deep neural networks (DNNs) have have quickly ascended to the spotlight. Running DNNs on resource-constrained mobile devices is, however, by no means trivial, since it incurs high performance and energy overhead. While offloading DNNs to the cloud for execution suffers unpredictable performance, due to the uncontrolled long wide-area network latency. To address these challenges, in this paper, we propose Edgent, a collaborative and on-demand DNN co-inference framework with device-edge synergy. Edgent pursues two design knobs: (1) DNN partitioning that adaptively partitions DNN computation between device and edge, in order to leverage hybrid computation resources in proximity for real-time DNN inference. (2) DNN right-sizing that accelerates DNN inference through early-exit at a proper intermediate DNN layer to further reduce the computation latency. The prototype implementation and extensive evaluations based on Raspberry Pi demonstrate Edgent’s effectiveness in enabling on-demand low-latency edge intelligence.
作为机器学习的骨干技术,深度神经网络(DNNs)已经迅速成为人们关注的焦点。然而,在资源受限的移动设备上运行DNN绝不是微不足道的,因为它会带来高性能和高能耗开销。由于不受控制的长广域网延迟,将DNN加载到云中以便执行会带来不可预测的性能。为了应对这些挑战,在本文中,我们提出了Edgent,一种具有设备边缘协同作用的协作和按需DNN协同推理框架。 Edgent追求两个设计目标:(1)DNN划分,自适应地划分设备和边缘之间的DNN计算,以便利用邻近的混合计算资源进行实时DNN推理。(2)DNN正确调整大小,通过在适当的中间DNN层提前退出来加速DNN推理,以进一步减少计算延迟。基于Raspberry Pi的原型实现和广泛评估证明了Edgent在实现按需低延迟边缘智能方面的有效性。
1 INTRODUCTION & RELATED WORK (引言和相关工作)
As the backbone technology supporting modern intelligent mobile applications, Deep Neural Networks (DNNs) represent the most commonly adopted machine learning technique and have become increasingly popular. Due to DNNs’s ability to perform highly accurate and reliable inference tasks, they have witnessed successful applications in a broad spectrum of domains from computer vision [14] to speech recognition [12] and natural language processing [16]. However, as DNN-based applications typically require tremendous amount of computation, they cannot be well supported by today’s mobile devices with reasonable latency and energy consumption.
作为支持现代智能移动应用的骨干技术,深度神经网络(DNN)代表了最常用的机器学习技术,并且越来越受欢迎。 由于DNN能够执行高度准确和可靠的推理任务,他们见证了从计算机视觉[14]到语音识别[12]和自然语言处理[16]等广泛领域的成功应用。 但是,由于基于DNN的应用程序通常需要大量的计算,因此当今的移动设备无法很好地支持它们(在合理的延迟和能耗约束下)。
In response to the excessive resource demand of DNNs, the traditional wisdom resorts to the powerful cloud datacenter for training and evaluating DNNs. Input data generated from mobile devices is sent to the cloud for processing, and then results are sent back to the mobile devices after the inference. However, with such a cloud-centric approach, large amounts of data (e.g., images and videos) are uploaded to the remote cloud via a long wide-area network data transmission, resulting in high end-to-end latency and energy consumption of the mobile devices. To alleviate the latency and energy bottlenecks of cloud-centric approach, a better solution is to exploiting the emerging edge computing paradigm. Specifcally, by pushing the cloud capabilities from the network core to the network edges (e.g., base stations and WiFi access points) in close proximity to devices, edge computing enables low-latency and energy-efficient DNN inference.
为了应对DNN的过多资源需求,传统智慧采用强大的云数据中心来训练和评估DNN。 从移动设备生成的输入数据被发送到云进行处理,然后在推断之后将结果发送回移动设备。 然而,利用这种以云为中心的方法,大量数据(例如,图像和视频)通过长广域网数据传输上传到远程云,导致移动设备上大的端到端延迟和能量消耗。 为了缓解以云为中心的方法的延迟和能量瓶颈,更好的解决方案是利用新兴的边缘计算范例。 具体地,通过将云的能力从网络核心推送到紧邻设备的网络边缘(例如,基站和WiFi接入点),边缘计算实现低延迟和高效能的DNN推断。
While recognizing the benefts of edge-based DNN inference, our empirical study reveals that the performance of edge-based DNN inference is highly sensitive to the available bandwidth between the edge server and the mobile device. Specifcally, as the bandwidth drops from 1Mbps to 50Kbps, the latency of edge-based DNN inference climbs from 0.123s to 2.317s and becomes on par with the latency of local processing on the device. Then, considering the vulnerable and volatile network bandwidth in realistic environments (e.g., due to user mobility and bandwidth contention among various Apps), a natural question is that can we further improve the performance (i.e., latency) of edge-based DNN execution, especially for some mission-critical applications such as VR/AR games and robotics [13].
虽然我们认识到基于边缘的DNN推理的好处,但我们的实证研究表明,基于边缘的DNN推理的性能对边缘服务器和移动设备之间的可用带宽高度敏感。 具体而言,随着带宽从1Mbps降至50Kbps,基于边缘的DNN推断的延迟从0.123s上升到2.317s,并且与设备上本地处理的延迟相当。 然后,考虑到现实环境中易受攻击和易变的网络带宽(例如,由于用户移动性和各种应用之间的带宽争用),一个自然的问题是我们能否进一步改善基于边缘的DNN执行的性能(即延迟), 特别是对于一些关键任务应用,如VR/AR游戏和机器人[13]。
To answer the above question in the positive, in this paper we proposed Edgent, a deep learning model co-inference framework with device-edge synergy. Towards low-latency edge intelligence, Edgent pursues two design knobs. The frst is DNN partitioning, which adaptively partitions DNN computation between mobile devices and the edge server based on the available bandwidth, and thus to take advantage of the processing power of the edge server while reducing data transfer delay. However, worth noting is that the latency after DNN partition is still restrained by the rest part running on the device side. Therefore, Edgent further combines DNN partition with DNN right-sizing which accelerates DNN inference through early-exit at an intermediate DNN layer. Needless to say, early-exit naturally gives rise to the latency-accuracy tradeoff (i.e., early-exit harms the accuracy of the inference). To address this challenge, Edgent jointly optimizes the DNN partitioning and right-sizing in an on-demand manner. That is, for mission-critical applications that typically have a predefned deadline, Edgent maximizes the accuracy without violating the deadline. The prototype implementation and extensive evaluations based on Raspberry Pi demonstrate Edgent’s effectiveness in enabling on-demand low-latency edge intelligence.
为了回答上述问题,我们在本文中提出了Edgent,一种具有设备边缘协同作用的深度学习模型协同推理框架。对于低延迟边缘智能(作为初始探索,本文我们只考虑执行延迟问题。在未来工作中,我们也将考虑能耗问题),Edgent追求两个设计目标。第一个是DNN分区,其基于可用带宽自适应地划分移动设备和边缘服务器之间的DNN计算,从而利用边缘服务器的处理能力,同时减少数据传输延迟。但值得注意的是,DNN分区后的延迟仍然受到设备端运行的其余部分的限制。因此,Edgent进一步将DNN分区与DNN正确大小调整相结合,通过在中间DNN层的早期退出来加速DNN推断。不用说,提前退出自然会产生延迟和准确度之间的均衡(即,提前退出会损害推断的准确性)。为了解决这一挑战,Edgent以按需方式协同优化DNN分区和正确大小调整。也就是说,对于通常具有预定截止时间的关键任务应用程序,Edgent在不违反截止时间的情况下最大化准确性。基于Raspberry Pi的原型实现和广泛评估证明了Edgent在实现按需低延迟边缘智能方面的有效性。
While the topic of edge intelligence has began to garner much attention recently, our study is different from and complementary to existing pilot efforts. On one hand, for fast and low power DNN inference at the mobile device side, various approaches as exemplifed by DNN compression and DNN architecture optimization has been proposed [3–5, 7, 9]. Different from these works, we take a scale-out approach to unleash the benefts of collaborative edge intelligence between the edge and mobile devices, and thus to mitigate the performance and energy bottlenecks of the end devices. On the other hand, though the idea of DNN partition among cloud and end device is not new [6], realistic measurements show that the DNN partition is not enough to satisfy the stringent timeliness requirements of mission-critical applications. Therefore, we further apply the approach of DNN right-sizing to speed up DNN inference.
虽然边缘智能的话题在最近引起了很多关注,但我们的研究与现有的工作不同并且互为补充。一方面,对于移动设备侧的快速和低功率DNN推断,已经提出了DNN压缩和DNN架构优化为例的各种方法[3-5,7,9]。 与这些工作不同,我们采用横向扩展方法释放边缘和移动设备之间协同边缘智能的好处,从而减轻终端设备的性能和能耗瓶颈。另一方面,虽然云和终端设备之间DNN划分的想法并不新鲜[6],但实际测量表明DNN划分不足以满足任务关键型应用的严格的实时性要求。 因此,我们进一步应用DNN正确大小调整的方法来加速DNN推理。
2 BACKGROUND & MOTIVATION (背景 & 动机)
In this section, we frst give a primer on DNN, then analyse the inefciency of edge- or device-based DNN execution, and finally illustrate the benefts of DNN partitioning and rightsizing with device-edge synergy towards low-latency edge intelligence.
在本节中,我们首先介绍DNN,然后分析基于边缘或设备的DNN执行的效率,最后说明利用设备边缘协同作用的DNN划分和正确大小调整实现低延迟边缘智能的好处。
2.1 A Primer on DNN (DNN基础)
DNN represents the core machine learning technique for a broad spectrum of intelligent applications spanning computer vision, automatic speech recognition and natural language processing. As illustrated in Fig. 1, computer vision applications use DNNs to extract features from an input image and classify the image into one of the pre-defned categories. A typical DNN model is organized in a directed graph which includes a series of inner-connected layers, and within each layer comprising some number of nodes. Each node is a neuron that applies certain operations to its input and generates an output. The input layer of nodes is set by raw data while the output layer determines the category of the data. The process of passing forward from the input layer to the out layer is called model inference. For a typical DNN containing tens of layers and hundreds of nodes per layer, the number of parameters can easily reach the scale of millions. Thus, DNN inference is computational intensive. Note that in this paper we focus on DNN inference, since DNN training is generally delay tolerant and is typically conducted in an off-line manner using powerful cloud resources.
DNN代表了包括计算机视觉、自动语音识别和自然语言处理在内的广泛智能应用的核心机器学习技术。如图1所示,计算机视觉应用程序使用DNN从输入图像中提取特征并将图像分类为某一预定类别。典型的DNN模型被组织为有向图,该有向图包括一系列内部连接的层,并且在每个层内包括一些节点。每个节点都是一个神经元,它将某些操作应用于其输入并生成输出。输入层节点由原始数据设置,而输出层确定数据的类别。从输入层到外层的前向传递过程称为模型推断。对于包含数十层和每层包含数百个节点的典型DNN,参数的数量可以轻松达到数百万的规模。因此,DNN推断是计算密集型的。注意,在本文中,我们关注DNN推理,因为DNN训练通常是延迟容忍的,并且通常使用强大的云资源以一种离线的方式进行。

图1:一个用于计算机视觉的4层DNN
2.2 Inefficiency of Device- or Edge-based DNN Inference (基于设备或边缘的DNN推理不高效)
Currently, the status quo of mobile DNN inference is either direct execution on the mobile devices or offloading to the cloud/edge server for execution. Unfortunately, both approaches may suffer from poor performance (i.e., end-to-end latency), being hard to well satisfy real-time intelligent mobile applications (e.g., AR/VR mobile gaming and intelligent robots) [2]. As illustration, we take a Raspberry Pi tiny computer and a desktop PC to emulate the mobile device and edge server respectively, running the classical AlexNet [1] DNN model for image recognition over the Cifar-10 dataset [8]. Fig. 2 plots the breakdown of the end-to-end latency of different approaches under varying bandwidth between the edge and mobile device. It clearly shows that it takes more than 2s to execute the model on the resource-limited Raspberry Pi. Moreover, the performance of edge-based execution approach is dominated by the input data transmission time (the edge server computation time keeps at ∼10ms) and thus highly sensitive to the available bandwidth. Specifcally, as the available bandwidth jumps from 1Mbps to 50Kbps, the end-to-end latency climbs from 0.123s to 2.317s. Considering the network bandwidth resource scarcity in practice (e.g., due to network resource contention among users and apps) and computing resource limitation on mobile devices, both of the device- and edge-based approaches are challenging to well support many emerging real-time intelligent mobile applications with stringent latency requirement.
目前,移动DNN推断的现状是要么在移动设备上直接执行,要么加载到云/边缘服务器执行。不幸的是,这两种方法都可能经历较差的性能(即端到端延迟),难以很好地满足实时智能移动应用(例如AR/VR移动游戏和智能机器人)[2]。例如,我们采用Raspberry Pi小型计算机和台式PC分别模拟移动设备和边缘服务器,运行经典的AlexNet [1] DNN模型,通过Cifar-10数据集进行图像识别[8]。图2绘制了边缘和移动设备之间不同带宽下不同方法的端到端延迟的细分。它清楚地表明在资源有限的Raspberry Pi上执行模型需要2秒以上。此外,基于边缘的执行方法的性能由输入数据传输时间(边缘服务器计算时间保持在~10ms)决定,因此对可用带宽高度敏感。具体而言,随着可用带宽从1Mbps降至50Kbps,端到端延迟从0.123秒攀升至2.317秒。考虑到实际中网络带宽资源的稀缺性(例如,由于用户和应用之间的网络资源争用)以及移动设备上的计算资源限制,基于设备和边缘的方法都难以很好地支持许多新兴的具有严格延迟要求的实时智能移动应用程序。

图2:AlexNet运行时间。
2.3 Enabling Edge Intelligence with DNN Partitioning and Right-Sizing (使用DNN划分和正确大小调整使能边缘智能)
DNN Partitioning: For a better understanding of the performance bottleneck of DNN execution, we further break the runtime (on Raspberry Pi) and output data size of each layer in Fig. 3. Interestingly, we can see that the runtime and output data size of different layers exhibit great heterogeneities, and layers with a long runtime do not necessarily have a large output data size. Then, an intuitive idea is DNN partitioning, i.e., partitioning the DNN into two parts and offloading the computational intensive one to the server at a low transmission overhead, and thus to reduce the end-to-end latency. For illustration, we choose the second local response normalization layer (i.e., lrn 2) in Fig. 3 as the partition point and offload the layers before the partition point to the edge server while running the rest layers on the device. By DNN partitioning between device and edge, we are able to collaborate hybrid computation resources in proximity for low-latency DNN inference.
DNN划分:为了更好地理解DNN执行的性能瓶颈,我们进一步分解运行时(在Raspberry Pi上)并在图3中给出每层的数据大小。有趣的是,我们可以看到运行时间和不同层的输出数据大小表现出很大的异构性,具有长运行时间的层不一定具有大的输出数据大小。 然后,直观的想法是DNN划分,即,将DNN分成两部分并以低传输开销将计算密集的一部分卸载到服务器,从而减少端到端等待时间。 为了说明,我们选择图3中的第二局部响应归一化层(即,lrn 2)作为划分点,并将划分点之前的层卸载到边缘服务器,同时在设备上运行其余层。 通过DNN在设备和边缘之间进行划分,我们能够为低延迟DNN推理协同混合计算资源。
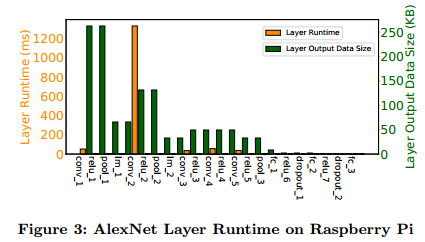
图3:树莓Pi设备上AlexNet层的运行时间。
DNN Right-Sizing: While DNN partitioning greatly reduces the latency by bending the computing power of the edge server and mobile device, we should note that the optimal DNN partitioning is still constrained by the run time of layers running on the device. For further reduction of latency, the approach of DNN Right-Sizing can be combined with DNN partitioning. DNN right-sizing promises to accelerate model inference through an early-exit mechanism. That is, by training a DNN model with multiple exit points and each has a different size, we can choose a DNN with a small size tailored to the application demand, meanwhile to alleviate the computing burden at the model division, and thus to reduce the total latency. Fig. 4 illustrates a branchy AlexNet with five exit points. Currently, the early-exit mechanism has been supported by the open source framework BranchyNet[15]. Intuitively, DNN right-sizing further reduces the amount of computation required by the DNN inference tasks.
DNN正确大小调整:虽然DNN划分通过降低边缘服务器和移动设备的计算能力大大减少了延迟,但我们应该注意到最佳DNN划分仍然受到设备上运行的层的运行时间的限制。 为了进一步减少延迟,DNN正确大小调整的方法可以与DNN划分相结合。 DNN正确的规模承诺通过早期退出机制加速模型推理。 也就是说,通过训练具有多个出口点的DNN模型并且每个具有不同的尺寸,我们可以选择适合应用需求的小尺寸DNN,同时减轻模型部门的计算负担,从而减少总延迟。 图4示出了具有五个出口点分支的AlexNet。 目前,早期退出机制得到了开源框架BranchyNet的支持[15]。 直观地说,DNN正确大小调整进一步减少了DNN推理任务所需的计算量。

图4: DNN正确大小调整中早期退出机制的示例
Problem Description: Obviously, DNN right-sizing incurs the problem of latency-accuracy tradeoff — while early exit reduces the computing time and the device side, it also deteriorates the accuracy of the DNN inference. Considering the fact that some applications (e.g., VR/AR game) have stringent deadline requirement while can tolerate moderate accuracy loss, we hence strike a nice balance between the latency and the accuracy in an on-demand manner. Particularly, given the predefned and stringent latency goal, we maximize the accuracy without violating the deadline requirement. More specifcally, the problem to be addressed in this paper can be summarized as: given a predefned latency requirement, how to jointly optimize the decisions of DNN partitioning and right-sizing, in order to maximize DNN inference accuracy.
问题描述:显然,DNN正确大小调整会产生延迟-准确性的权衡 - 虽然早期退出会缩短计算时间(设备),但它也会降低DNN推理的准确性。 考虑到某些应用程序(例如,VR/AR游戏)具有严格的期限要求而能够容忍适度的准确度损失的事实,因此我们以按需方式在延迟和准确性之间取得了良好的平衡。 特别是,考虑到预定义和严格的延迟目标,我们在不违反期限要求的情况下最大化准确性。 更具体地说,本文要解决的问题可归纳为:给定预定的延迟要求,如何联合优化DNN划分和正确大小调整的决策,以最大化DNN推理的准确性。
3 FRAMEWORK (框架)
We now outline the initial design of Edgent, a framework that automatically and intelligently selects the best partition point and exit point of a DNN model to maximize the accuracy while satisfying the requirement on the execution latency.
我们现在概述Edgent的初始设计,这是一个自动智能地选择DNN模型的最佳划分点和退出点的框架,以在满足执行延迟要求的同时最大化准确性。
3.1 System Overview (系统概述)
Fig. 5 shows the overview of Edgent. Edgent consists of three stages: ofine training stage, online optimization stage and co-inference stage.
图5显示了Edgent的概述。 Edgent由三个阶段组成:训练阶段、在线优化阶段和共同推理阶段。
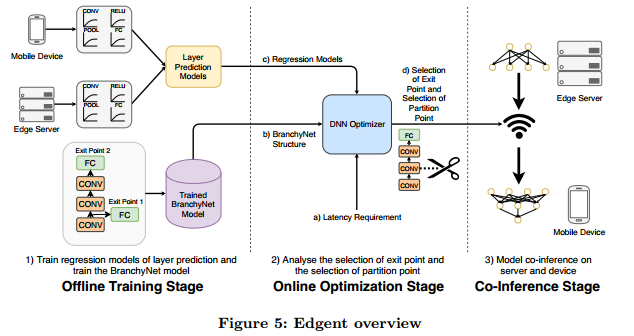
图5: Edgent概览
At offline training stage, Edgent performs two initializations: (1) profling the mobile device and the edge server to generate regression-based performance prediction models (Sec. 3.2) for different types DNN layer (e.g., Convolution, Pooling, etc.). (2) Using Branchynet to train DNN models with various exit points, and thus to enable early-exit. Note that the performance profling is infrastructure-dependent, while the DNN training is application-dependent. Thus, given the sets of infrastructures (i.e., mobile devices and edge servers) and applications, the two initializations only need to be done once in an offline manner.
在离线训练阶段,Edgent执行两次初始化:(1)对移动设备和边缘服务器进行分析,以针对不同类型的DNN层(例如,卷积,池化等)生成基于回归的性能预测模型(第3.2节)。 (2)使用Branchynet训练具有不同退出点的DNN模型,从而实现提前退出。请注意,性能分析依赖于基础结构,而DNN训练则取决于应用程序。 因此,给定基础设施(即,移动设备和边缘服务器)和应用程序,两个初始化仅需要以离线方式进行一次。
At online optimization stage, the DNN optimizer selects the best partition point and early-exit point of DNNs to maximize the accuracy while providing performance guarantee on the end-to-end latency, based on the input: (1) the profiled layer latency prediction models and Branchynet trained DNN models with various sizes. (2) the observed available bandwidth between the mobile device and edge server. (3) The pre-defined latency requirement. The optimization algorithm is detailed in Sec. 3.3.
在线优化阶段,DNN优化器选择DNN的最佳分区点和早期退出点,以最大化准确性,同时根据输入提供端到端延迟的性能保证:(1)分析的层延迟预测模型和各种尺寸的Branchynet训练的DNN模型。(2)移动设备和边缘服务器之间观察到的可用带宽。(3)预先确定的延迟要求。 优化算法详见第3.3节。
At co-inference stage, according to the partition and early-exit plan, the edge server will execute the layer before the partition point and the rest will run on the mobile device.
在协同推理阶段,根据划分和提前退出规划,边缘服务器将执行该层划分点之前的层,且其余部分将在移动设备上运行。
3.2 Layer Latency Prediction (层延迟预测)
When estimating the runtime of a DNN, Edgent models the per-layer latency rather than modeling at the granularity of a whole DNN. This greatly reduces the profling overhead since there are very limited classes of layers. By experiments, we observe that the latency of different layers is determined by various independent variables (e.g., input data size, output data size) which are summarized in Table 1. Note that we also observe that the DNN model loading time also has an obvious impact on the overall runtime. Therefore, we further take the DNN model size as a input parameter to predict the model loading time. Based on the above inputs of each layer, we establish a regression model to predict the latency of each layer based on its profles. The fnal regression models of some typical layers are shown in Table 2 (size is in bytes and latency is in ms).
在估计DNN的运行时间时,Edgent会对每层的延迟进行建模,而不是以整个DNN为粒度进行建模。 这极大地减少了分析开销,因为存在非常有限的层类别。 通过实验,我们观察到不同层的延迟由各种独立变量(例如,输入数据大小,输出数据大小)决定,如表1所示。注意,我们还观察到DNN模型的加载时间对总运行时间也有明显的影响。 因此,我们进一步将DNN模型的大小作为输入参数来预测模型的加载时间。 基于每层的上述输入,我们建立回归模型以基于分析预测每个层的延迟。 表2中显示了一些典型层的最终回归模型(大小以字节为单位,延迟以毫秒为单位)。


3.3 Joint Optimization on DNN Partition and DNN Right-Sizing (DNN划分和DNN正确大小调整的协同优化)
At online optimization stage, the DNN optimizer receives the latency requirement from the mobile device, and then searches for the optimal exit point and partition point of the trained branchynet model. The whole process is given in Algorithm 1. For a branchy model with M exit points, we denote that the i-th exit point has Ni layers. Here a layer index i correspond to a more accurate inference model of larger size. We use the above-mentioned regression models to predict EDj the runtime of the j-th layer when it runs on device and ESj the runtime of the j-th layer when it runs on server. Dp is the output of the p-th layer. Under a specific bandwidth B, with the input data Input, then we calcuate Ai,p the whole runtime 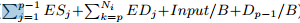 when the p-th is the partition point of the selected model of i-th exit point. When p = 1, the model will only run on the device then ESp = 0, Dp-1/B = 0, Input/B = 0, and when p = Ni, the model will only run on the server then EDp = 0, Dp-1/B = 0. In this way, we can find out the best partition point having the smallest latency for the model of i-th exit point. Since the model partition does not affect the inference accuracy, we can then sequentially try the DNN inference models with different exit points(i.e., with different accuracy), and find the one having the largest size and meanwhile satisfying the latency requirement. Note that since regression models for layer latency prediction are trained beforehand, Algorithm 1 mainly involves linear search operations and can be done very fast (no more than 1ms in our experiments) .
when the p-th is the partition point of the selected model of i-th exit point. When p = 1, the model will only run on the device then ESp = 0, Dp-1/B = 0, Input/B = 0, and when p = Ni, the model will only run on the server then EDp = 0, Dp-1/B = 0. In this way, we can find out the best partition point having the smallest latency for the model of i-th exit point. Since the model partition does not affect the inference accuracy, we can then sequentially try the DNN inference models with different exit points(i.e., with different accuracy), and find the one having the largest size and meanwhile satisfying the latency requirement. Note that since regression models for layer latency prediction are trained beforehand, Algorithm 1 mainly involves linear search operations and can be done very fast (no more than 1ms in our experiments) .
在线优化阶段,DNN优化器从移动设备接收延迟要求,然后搜索训练的branchynet模型的最佳出口点和分区点。整个过程在算法1中给出。对于具有M个出口点的分支模型,我们表示第i个出口点具有Ni层。这里,更大的层索引i对应于更准确的推断模型。我们使用上面提到的回归模型来预测第j层在设备上运行时的运行时间EDj,ESj是它在服务器上运行时运行时间。 Dp是第p层的输出。在特定带宽B下,使用输入数据Input,我们计算总运行时间Ai,p= ,其中,p是所选模型的划分点,i表示个出口点。当p = 1时,模型将仅在设备上运行,那么ESp = 0,Dp-1 / B = 0,Input/ B = 0;当p = Ni时,模型将仅在服务器上运行,那么EDp = 0 ,Dp-1 / B = 0。通过这种方式,我们可以找到具有最小延迟的最佳分区点,用于第i个出口点的模型。由于模型划分不影响推理精度,我们可以依次尝试具有不同出口点的DNN推理模型(即,具有不同的精度),并找到具有最大尺寸并同时满足延迟要求的模型。请注意,由于预先训练了层延迟预测的回归模型,因此算法1主要涉及线性搜索操作,并且可以非常快速地完成(在我们的实验中不超过1ms)。
,其中,p是所选模型的划分点,i表示个出口点。当p = 1时,模型将仅在设备上运行,那么ESp = 0,Dp-1 / B = 0,Input/ B = 0;当p = Ni时,模型将仅在服务器上运行,那么EDp = 0 ,Dp-1 / B = 0。通过这种方式,我们可以找到具有最小延迟的最佳分区点,用于第i个出口点的模型。由于模型划分不影响推理精度,我们可以依次尝试具有不同出口点的DNN推理模型(即,具有不同的精度),并找到具有最大尺寸并同时满足延迟要求的模型。请注意,由于预先训练了层延迟预测的回归模型,因此算法1主要涉及线性搜索操作,并且可以非常快速地完成(在我们的实验中不超过1ms)。

4 EVALUATION (评估)
We now present our preliminary implementation and evaluation results.
现在,我们给出初步实现和评估结果。
4.1 Prototype (原型)
We have implemented a simple prototype of Edgent to verify the feasibility and efcacy of our idea. To this end, we take a desktop PC to emulate the edge server, which is equipped with a quad-core Intel processor at 3.4 GHz with 8 GB of RAM, and runs the Ubuntu system. We further use Raspberry Pi 3 tiny computer to act as a mobile device. The Raspberry Pi 3 has a quad-core ARM processor at 1.2 GHz with 1 GB of RAM. The available bandwidth between the edge server and the mobile device is controlled by the WonderShaper [10] tool. As for the deep learning framework, we choose Chainer [11] that can well support branchy DNN structures.
我们已经实现了Edgent的简单原型系统来验证我们的想法的可行性和有效性。 为此,我们采用台式机PC模拟边缘服务器,该服务器配备了3.4 GHz的四核英特尔处理器和8 GB的RAM,并运行Ubuntu系统。 我们进一步使用Raspberry Pi 3微型计算机充当移动设备。 Raspberry Pi 3具有1.2 GHz的四核ARM处理器和1 GB的RAM。 边缘服务器和移动设备之间的可用带宽由WonderShaper [10]工具控制。 至于深度学习框架,我们选择能够很好地支持分支DNN结构的Chainer [11]。
For the branchynet model, based on the standard AlexNet model, we train a branchy AlexNet for image recognition over the large-scale Cifar-10 dataset [8]. The branchy AlexNet has five exit points as showed in Fig. 4 (Sec. 2), each exit point corresponds to a sub-model of the branchy AlexNet. Note that in Fig. 4, we only draw the convolution layers and the fully-connected layers but ignore other layers for ease of illustration. For the five sub-models, the number of layers they each have is 12, 16, 19, 20 and 22, respectively.
对于branchynet模型,基于标准的AlexNet模型,我们训练了一个分支的AlexNet,用于大规模Cifar-10数据集的图像识别[8]。 如图4(第2节)所示,分支的AlexNet具有5个出口点,每个出口点对应于分支AlexNet的子模型。 请注意,在图4中,我们仅绘制卷积层和完全连接的层,为了便于说明而忽略其他层。 对于这5个子模型,它们各自具有的层数分别为12,16,19,20和22。
For the regression-based latency prediction models for each layer, the independent variables are shown in the Table. 1, and the obtained regression models are shown in Table 2.
对于每层的基于回归预测模型,独立变量显示在表1中, 获得的回归模型如表2所示。
4.2 Results (结果)
We deploy the branchynet model on the edge server and the mobile device to evaluate the performance of Edgent. Specifcally, since both the pre-defned latency requirement and the available bandwidth play vital roles in Edgent’s optimization logic, we evaluate the performance of Edgent under various latency requirements and available bandwidth.
我们在边缘服务器和移动设备上部署了branchynet模型,以评估Edgent的性能。 具体而言,由于预先确定的延迟要求和可用带宽在Edgent的优化逻辑中起着至关重要的作用,因此我们在各种延迟要求和可用带宽下评估Edgent的性能。
We first investigate the effect of the bandwidth by fixing the latency requirement at 1000ms and varying the bandwidth 50kbps to 1.5Mbps. Fig. 6(a) shows the best partition point and exit point under different bandwidth. While the best partition points may fluctuate, we can see that the best exit point gets higher as the bandwidth increases. Meaning that the higher bandwidth leads to higher accuracy. Fig. 6(b) shows that as the bandwidth increases, the model runtime first drops substantially and then ascends suddenly. However, this is reasonable since the accuracy gets better while the latency is still within the latency requirement when increase the bandwidth from 1.2Mbps to 2Mbps. It also shows that our proposed regression-based latency approach can well estimate the actual DNN model runtime latency. We further fix the bandwidth at 500kbps and vary the latency from 100ms to 1000ms. Fig. 6(c) shows the best partition point and exit point under different latency requirements. As expected, the best exit point gets higher as the latency requirement increases, meaning that a larger latency goal gives more room for accuracy improvement.
我们首先通过使用固定的1000ms的延迟要求并将带宽由50kbps到1.5Mbps变化来研究带宽的影响。图6(a)显示了不同带宽下的最佳划分点和退出点。虽然最佳划分点可能会波动,但我们可以看到随着带宽的增加,最佳退出点会变得更高,这意味着更高的带宽会带来更高的准确性。图6(b)显示随着带宽的增加,模型运行时间首先大幅下降,然后突然上升。但是,这是合理的,因为当将带宽从1.2Mbps增加到2Mbps时,准确性变得更好,而延迟仍然在延迟要求内。它还表明我们提出的基于回归的延迟方法可以很好地估计实际的DNN模型运行时延迟。我们进一步将带宽固定在500kbps,并将延迟从100ms改为1000ms。图6(c)显示了不同延迟要求下的最佳划分点和出口点。正如预期的那样,随着延迟需求的增加,最佳出口点会越来越高,这意味着更大的延迟目标可以为更高的准确性提供更多空间。
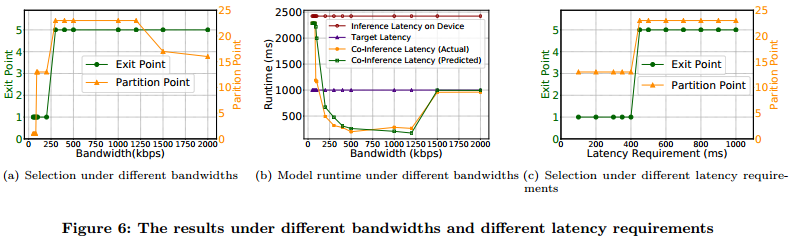
图6:不同带宽和延迟要求下的结果。
In Fig. 7, under different latency requirements, it shows the model accuracy of different inference methods. The accuracy is negative if the inference can not satisfy the latency requirement. The network bandwidth is set to 400kbps. Seen in the Fig. 7, at a very low latency requirement (100ms), all four methods can’t satisfy the requirement. As the latency requirement increases, inference by Edgent works earlier than the other methods that at the 200ms to 300ms requirements, by using a small model with a moderate inference accuracy to meet the requirements. The accuracy of the model selected by Edgent gets higher as the latency requirement relaxes.
在图7中,根据不同的延迟要求,显示了不同推理方法的模型精度。 如果推断不能满足延迟要求,则准确度为负。 网络带宽设置为400kbps。 如图7所示,在非常低的延迟要求(100ms)下,所有四种方法都不能满足要求。 随着延迟要求的增加,Edgent的推理比其他200ms至300ms要求的方法更早结束,通过使用具有中等推理精度的小模型来满足要求。 随着延迟要求的放松,Edgent选择的模型的准确性会提高。
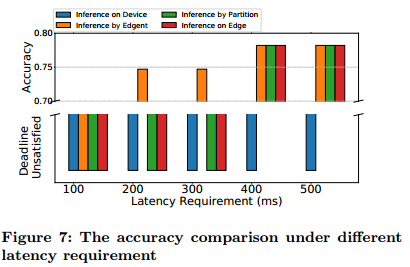
图7:不同延迟需求下的精度比较。