当我们在学习和临摹垃圾回收(Garbage Collection, 缩写为 GC)相关算法和源码时候, 内在细节离不开
这两大类搜索算法支撑. 这就是构建的背景❉, 文章定位是科普扫盲❤.
0. 引述与目录
[0] 知乎 - 节点 or 结点 ? [走进科学]
[1] 维基百科 - 广度优先搜索 [概念参照]
[2] 维基百科 - 深度优先搜索 [概念参照]
[3] 维基百科 - 树的遍历 [概念参照]
[4] CSDN - 二叉树的深度优先遍历与广度优先遍历 [盗图]
[5] 博客园 - 数据结构之图的基本概念 [递归抄袭]
[6] 博客园 - 图的遍历之 深度优先搜索和广度优先搜索 [深度抄袭]
[7] github - 深度搜索和广度搜索 [演示素材]
目录
1. 概念介绍
2. 树的例子
2.1 前序遍历
2.2 中序遍历
2.3 后序遍历
2.4 层次遍历
2.5 搜索算法源码
3. 图的例子
3.0 图的基本概念
3.0.1 图的定义
3.0.2 图的基本概念
3.0.3 图最基础的两类存储结构
3.0.3.1 邻接矩阵表示法
3.0.3.2 邻接表表示法
3.1 深度优先搜索图文介绍
3.1.1 深度优先搜索介绍
3.1.2 深度优先搜索图解
3.1.2.1 无向图的深度优先搜索
3.1.2.2 有向图的深度优先搜索
3.2 广度优先搜索图文介绍
3.2.1 广度优先搜索介绍
3.2.2 广度优先搜索图解
3.2.2.1 无向图的广度优先搜索
3.2.2.2 有向图的广度优先搜索
3.3 搜索算法源码
3.3.1 邻接矩阵图表示的无向图 (Matrix Undirected Graph)
3.3.2 邻接矩阵图表示的有向图 (Matrix Directed Graph)
3.3.3 邻接链表图表示的无向图 (List Undirected Graph)
3.3.4 邻接链表图表示的有向图 (List Directed Graph)
1. 概念介绍
关于遍历算法种类有很多很多, 这里选了最通用, 深度优先遍历和广度优先遍历两类搜索算法进行浅显
讲解(作者能力有限). 基础有时候很有趣, 真的! ok, 那我们 go on.
深度优先搜索算法(Depth-First-Search, 缩写为 DFS), 是一种用于遍历或搜索树或图的算法. 这个算法
会尽可能深的搜索树的分支. 当结点 v 的所在边都己被探寻过, 搜索将回溯到发现结点 v 的那条边的起始结
点. 这一过程一直进行到已发现从源结点可达的所有结点为止. 如果还存在未被发现的结点, 则选择其中一
个作为源结点并重复以上过程, 整个进程反复进行直到所有结点都被访问为止.
广度优先搜索算法(Breadth-First Search, 缩写为 BFS), 又译作宽度优先搜索, 或横向优先搜索, 是一种
图形搜索算法. 简单的说, BFS 是从根结点开始, 沿着树的宽度遍历树的结点. 如果所有结点均被访问, 则算法
中止.
在计算机科学里, 树的遍历(也称为树的搜索)是图的遍历的一种, 指的是按照某种规则, 不重复地访问某
种树的所有结点的过程. 具体的访问操作可能是检查结点的值, 更新结点的值等. 不同的遍历方式, 其访问结
点的顺序是不一样的. 以下我们将二叉树的广度优先和深度优先遍历算法归类,但它们也适用于其它树形结
构.
深度优先遍历(搜索)
前序遍历(Pre-Order Traversal)

深度优先搜索 - 前序遍历: F -> B -> A -> D -> C -> E -> G -> I ->H
中序遍历(In-Order Traversal)

深度优先搜索 - 中序遍历: A -> B -> C -> D -> E -> F -> G -> H -> I
后序遍历(Post-Order Traversal)

深度优先搜索 - 后序遍历: A -> C -> E -> D -> B -> H -> I -> G -> F
广度优先遍历(搜索)
层次遍历(Level Order Traversal)

广度优先搜索 - 层次遍历:F -> B -> G -> A -> D -> I -> C -> E -> H
通过阅读和思考以上维基百科中提供的摘录, 我们大致对两类遍历算法有了点直观的认知. 不知道有没
有人有这样的疑惑, 为什么宽度优先搜索叫法没有广度优先搜索这个叫法流传广, 明明在树结构中要好理解
多了呢? 乍看确实这样, 但不要忘了树结构是一种特殊图结构, 而复杂图结构可能没有直观从上到下, 从左到
右这种直观的观感了. 因而宽度优先搜索名词在一般化中显得不够准确了. 哈哈哈. 另外一个认知是关于必要
条件的. 例如深度和广度优先搜索包含很多不同遍历相关相关算法, 不仅仅只有文章中介绍那几个, 这点大家
要充分认识.
2. 树的例子

观察图片, 提示中可以发现前中后序遍历定义是围绕根结点访问时机定义的(还存在潜规则, 默认先左子
树后右子树). 下面我们通过具体的代码来表达遍历思路. 首先我们构造树结构
/** * 方便测试和描述算法, 用 int node 构建 */ typedef int node_t; static void node_printf(node_t value) { printf(" %2d", value); } struct tree { struct tree * left; struct tree * right; node_t node; }; static inline struct tree * tree_new(node_t value) { struct tree * node = malloc(sizeof (struct tree)); node->left = node->right = NULL; node->node = value; return node; } static void tree_delete_partial(struct tree * node) { if (node->left) tree_delete_partial(node->left); if (node->right) tree_delete_partial(node->right); free(node); } void tree_delete(struct tree * root) { if (root) tree_delete_partial(root); }
2.1 前序遍历
static void tree_preorder_partial(struct stack * s) { struct tree * top; // 2.1 访问栈顶结点, 并将其出栈 while ((top = stack_pop_top(s))) { // 2.2 做业务处理 node_printf(top->node); // 3. 如果根结点存在右孩子, 则将右孩子入栈 if (top->right) stack_push(s, top->right); // 4. 如果根结点存在左孩子, 则将左孩子入栈 if (top->left) stack_push(s, top->left); } } /* * 前序遍历: * 根结点 -> 左子树 -> 右子树 * * 遍历算法: * 1. 先将根结点入栈 2. 访问栈顶结点, 做业务处理, 并将其出栈 3. 如果根结点存在右孩子, 则将右孩子入栈 4. 如果根结点存在左孩子, 则将左孩子入栈 重复 2 - 4 直到栈空 */ void tree_preorder(struct tree * root) { if (!root) return; struct stack s[1]; stack_init(s); // 1. 先将根结点入栈 stack_push(s, root); // 重复 2 - 4 直到栈空 tree_preorder_partial(s); stack_free(s); }
2.2 中序遍历
static void tree_inorder_partial(struct tree * node, struct stack * s) { // 4. 重复第 2 - 3步, 直到栈空并且不存在待访问结点 while (!stack_empty(s) || node) { // 2. 将当前结点的所有左孩子入栈, 直到左孩子为空 while (node) { // 1. 先将根结点入栈 stack_push(s, node); node = node->left; } // 3.1 弹出并访问栈顶元素, node = stack_pop_top(s); // 3.2 做业务处理. node_printf(node->node); // 4.1 如果栈顶元素存在右孩子 node = node->right; } } /* * 中序遍历: * 左子树 -> 根结点 -> 右子树 * * 遍历算法: * 1. 先将根结点入栈 2. 将当前结点的所有左孩子入栈, 直到左孩子为空 3. 弹出并访问栈顶元素, 做业务处理. 4. 如果栈顶元素存在右孩子, 重复第 2 - 3步, 直到栈空并且不存在待访问结点 */ void tree_inorder(struct tree * root) { if (!root) return; struct stack s[1]; stack_init(s); tree_inorder_partial(root, s); stack_free(s); }
2.3 后序遍历
static void tree_postorder_partial(struct stack * s) { struct tree * top; // 记录前一次出栈结点 struct tree * last = NULL; // 重复 1-2 直到栈空 while ((top = stack_top(s))) { // 2.2 如果我们发现它左右子结点都为空, 则可以做业务处理; // 2.3 或者,如果发现前一个出栈的结点是它的左结点或者右子结点,则可以做业务处理; if ((!top->left && !top->right) || (last && (last == top->left || last == top->right))) { // 做业务处理 node_printf(top->node); // 出栈 stack_pop(s); // 记录此次出栈结点 last = top; } else { // 2.4. 否则,表示这个结点是一个新的结点,需要尝试将其右左子结点依次入栈. if (top->right) stack_push(s, top->right); if (top->left) stack_push(s, top->left); } } } /* * 后序遍历: * 左子树 -> 右子树 -> 根结点 * * 遍历算法: * 1. 拿到一个结点, 先将其入栈, 则它一定在比较靠栈底的地方, 比较晚出栈 2. 在出栈时候判断到底是只有左结点还是只有右结点或者是两者都有或者是都没有. 如果我们发现它左右子结点都为空, 则可以做业务处理; 或者,如果发现前一个出栈的结点是它的左结点或者右子结点,则可以做业务处理; 否则,表示这个结点是一个新的结点,需要尝试将其右左子结点依次入栈. 重复 1-2 直到栈空 */ void tree_postorder(struct tree * root) { if (!root) return; struct stack s[1]; stack_init(s); // 1. 先将根结点入栈 stack_push(s, root); // 重复 1 - 4 直到栈空 tree_postorder_partial(s); stack_free(s); }
思考上面深度优先搜索三种方式, 大致会感觉, 占用栈空间大小映象是 前序遍历 < 中序遍历 < 后序遍历 (存在
特例). 可能, 这也是前序遍历是树深度优先搜索算法中流传最广的原因. 对于树的后序遍历代码实现, 版本也有
好几个. 有的很容易手写, 很花哨偷巧, 这里推荐的是正规工程版本.
2.4 层次遍历
/* * 层次遍历: * 根结点 -> 下一层 | 左结点 -> 右结点 * * 遍历算法: * 1. 对于不为空的结点, 先把该结点加入到队列中 * 2. 从队中弹出结点, 并做业务处理, 尝试将左结点右结点依次压入队列中 * 重复 1 - 2 指导队列为空 */ void tree_level(struct tree * root) { if (!root) return; q_t q; q_init(q); // 1. 对于不为空的结点, 先把该结点加入到队列中 q_push(q, root); do { // 2.1 从队中弹出结点, 并做业务处理 struct tree * node = q_pop(q); node_printf(node->node); // 2.2 尝试将左结点右结点依次压入队列中 if (node->left) q_push(q, node->left); if (node->right) q_push(q, node->right); // 重复 1 - 2 指导队列为空 } while (q_exist(q)); q_free(q); }
上面思路非常正规直白, 也可以做语言配合算法进行简单优化(推荐).
/* * 层次遍历: * 根结点 -> 下一层 | 左结点 -> 右结点 * * 遍历算法: * 1. 开始结点判空, 决定是否继续 * 2. 构建辅助队列结构 * 3. 直接对结点做业务处理 * 4. 尝试将不为空左结点右结点依次压入队列中 * 5. 队列出队赋值保存 * 重复 3 - 5 直到变量为空 */ void tree_level_optimize(struct tree * root) { // 1. 开始结点判空, 决定是否继续 if (!root) return; // 2. 构建辅助队列结构 q_t q; q_init(q); do { // 3. 直接对结点做业务处理 node_printf(root->node); // 4. 尝试将不为空左结点右结点依次压入队列中 if (root->left) q_push(q, root->left); if (root->right) q_push(q, root->right); // 5. 队列出队赋值保存 root = q_pop(q); // 重复 3 - 5 直到变量为空 } while (root); q_free(q); }
2.5 搜索算法源码
3. 图的例子
本章会先对图的深度优先搜索和广度优先搜索进行简单介绍, 然后再给出 C 的源码实现.
3.0 图的基本概念
3.0.1 图的定义
定义: 图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成, 通常表示为: G(V, E), 其中, G 表示一个图,
V 是 图 G 中顶点的集合, E 是 图 G 中边的集合.
在图中需要注意的是:
(1) 线性表中我们把数据元素叫元素, 树中将数据元素叫结点, 在图中数据元素, 我们则称之为顶点(Vertex).
(2) 线性表可以没有元素, 称为空表; 树中可以没有结点, 称为空树; 但是, 在图中不允许没有顶点(有穷非空性).
(3) 线性表中的各元素是线性关系, 树中的各元素是层次关系, 而, 图中各顶点的关系是用边来表示(边集可以为
空).
3.0.2 图的基本概念
(1) 无向图

如果图中任意两个顶点之间的边都是无向边(简而言之就是没有方向的边), 则称该图为无向图(Undirected
graphs).
(2) 有向图

如果图中任意两个顶点之间的边都是有向边(简而言之就是有方向的边), 则称该图为有向图(Directed graphs).
(3) 完全图
① 无向完全图: 在无向图中, 如果任意两个顶点之间都存在边, 则称该图为无向完全图. (含有 n 个顶点的无向完
全图有 (n×(n-1))/2 条边) 如下图所示:

② 有向完全图: 在有向图中, 如果任意两个顶点之间都存在方向互为相反的两条弧, 则称该图为有向完全图. (含
有 n 个顶点的有向完全图有 n×(n-1) 条边) 如下图所示:

PS: 当一个图接近完全图时, 则称它为稠密图(Dense Graph), 而当一个图含有较少的边时, 则称它为稀疏图(
Spare Graph).
(4) 顶点的度
顶点 V 的度(Degree) 是指在图中与 V 相关联的边的条数. 对于有向图来说, 有入度(In-degree)和出度
(Out-degree) 之分, 有向图顶点的度等于该顶点的入度和出度之和. 例如 A -> B 标识 A 出度为 1, B 入度为 1.
(5) 邻接
① 若无向图中的两个顶点 V 和 W 存在一条边(V, W), 则称顶点 V 和 W 邻接(Adjacent);
② 若有向图中存在一条边<V, W>,则称 顶点 V 邻接到 顶点 W ,活 顶点 W 邻接自 顶点 V;
以 (2) 有向图 举例, 有 <A, D> <B, A> <B, C> <C, A> 邻接关系.
(6) 弧头和弧尾
有向图中, 无箭头一端的顶点通常被称为"初始点"或"弧尾", 箭头直线的顶点被称为"终端点"或"弧头". <A, D>
邻接关系中, 顶点 A 就是弧尾, 顶点 D 就是弧头.
PS: 无向图中的边使用小括号"()"表示, 而有向图中的边使用尖括号"<>" 表示.
(7) 路径
在无向图中, 若从顶点 V 出发有一组边可到达顶点 W, 则称顶点 V 到顶点 W 的顶点序列, 为从顶点 V 到顶点 W的
路径(Path).
(8) 连通
若从 V 到 W 有路径可通, 则称顶点 V 和顶点 W 是连通(Connected)的.
(9) 权

有些图的边或弧具有与它相关的数字, 这种与图的边或弧相关的数叫做权(Weight).
有些图的边或弧具有与它相关的数字, 这种与图的边或弧相关的数叫做权(Weight).
3.0.3 图最基础的两类存储结构
图的存储结构除了要存储图中的各个顶点本身的信息之外, 还要存储顶点与顶点之间的关系, 因此, 图的结
构也比较复杂. 常用最基础的两类图的存储结构有邻接矩阵和邻接表.
3.0.3.1 邻接矩阵表示法
图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图. 一个一维数组存储图中顶点信息, 一个
二维数组(称为邻接矩阵)存储图中的边或弧的信息.
(1) 无向图
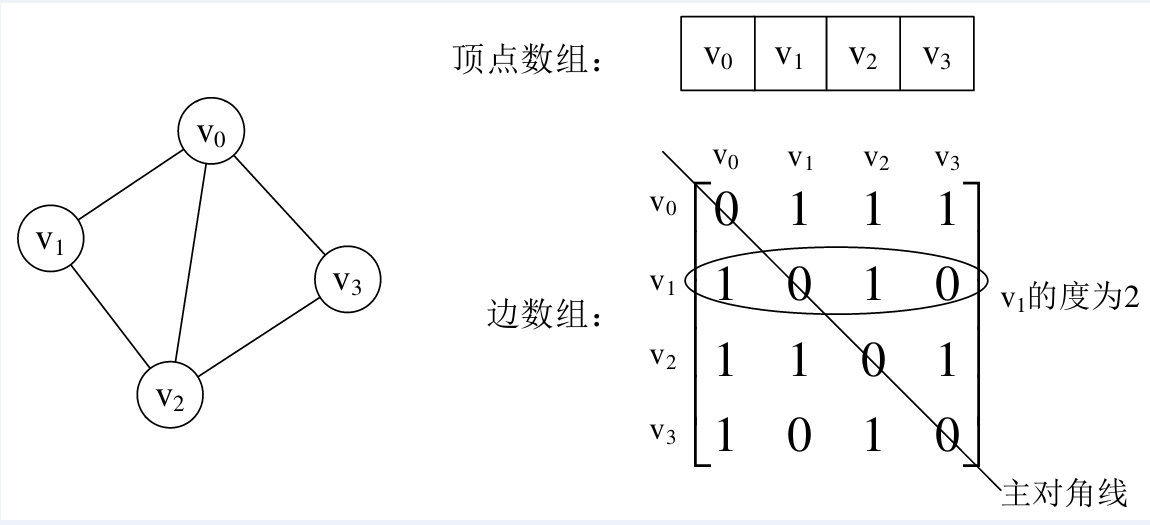
我们可以设置两个数组, 顶点数组为 vertex[4] = {V0, V1, V2, V3}, 边数组 edges[4][4] 为上图右边这样的一个矩
阵. 对于矩阵的主对角线的值, 即 edges[0][0], edges[1][1], edges[2][2], edges[3][3], 全为 0, 因为不存在顶点
自己到自己的边.
(2) 有向图
我们再来看一个有向图样例, 如下图所示的左边. 顶点数组为 vertex[4] = {V0, V1, V2, V3}, 弧数组 edges[4][4]
为下图右边这样的一个矩阵. 主对角线上数值依然为 0. 但因为是有向图, 所以此矩阵并不对称, 比如由 V1 到 V0
有弧, 得到 edges[1][0] = 1, 而 V0 到 V1 没有弧, 因此 edges[0][1] = 0.
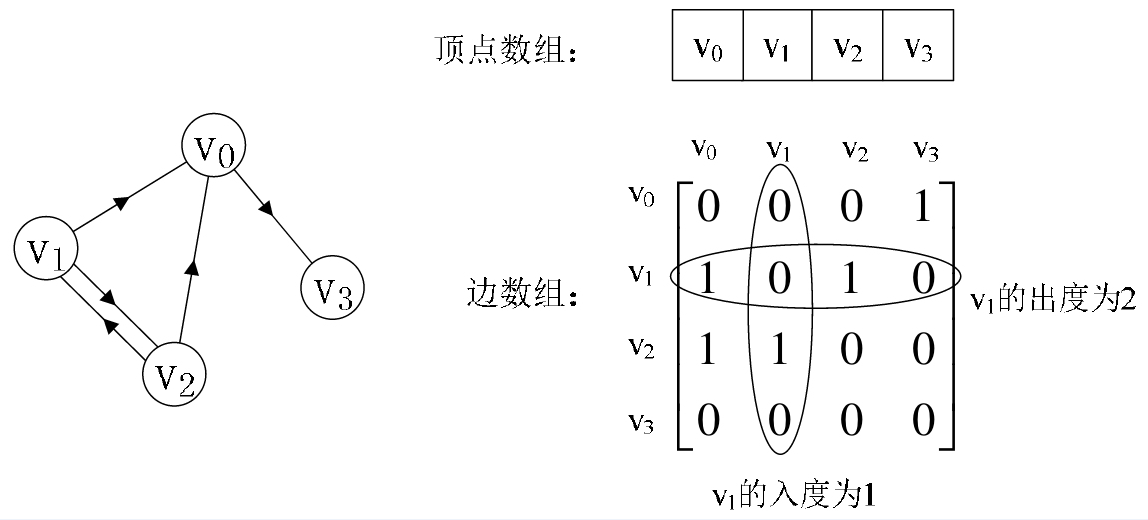
不足: 由于存在 n 个顶点的图需要 n*n 个数组元素进行存储, 当图为稀疏图时, 使用邻接矩阵存储方法将会出
现大量 0 元素, 这会造成极大的空间浪费. 这时, 可以考虑使用邻接表表示法来存储图中的数据.
3.0.3.2 邻接表表示法
首先, 回忆我们烙印在身体里的线性表存储结构, 顺序存储结构因为存在预先分配内存可能造成存储空间
浪费的问题, 于是想到了链式存储的结构. 同样的, 我们也可以尝试对边或弧使用链式存储的方式来避免空间浪
费的问题.
邻接表由表头结点和表结点两部分组成, 图中每个顶点均对应一个存储在数组中的表头结点. 如果这个表
头结点所对应的顶点存在邻接结点, 则把邻接结点依次存放于表头结点所指向的单向链表中.
(1) 无向图: 下图所示的就是一个无向图的邻接表结构.
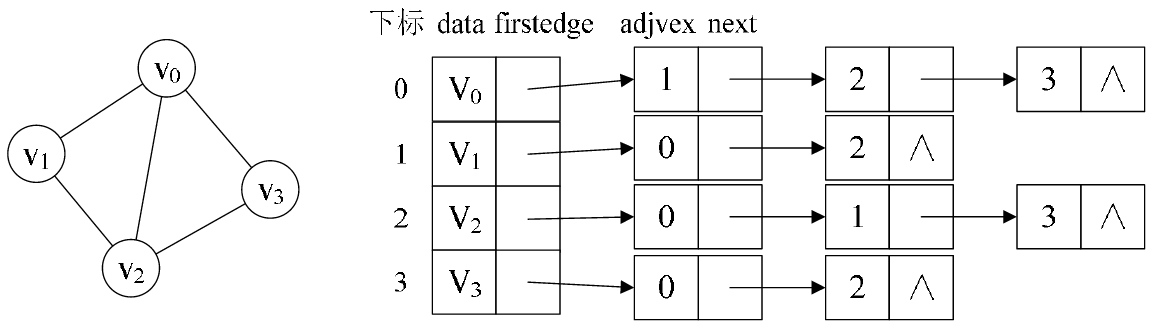
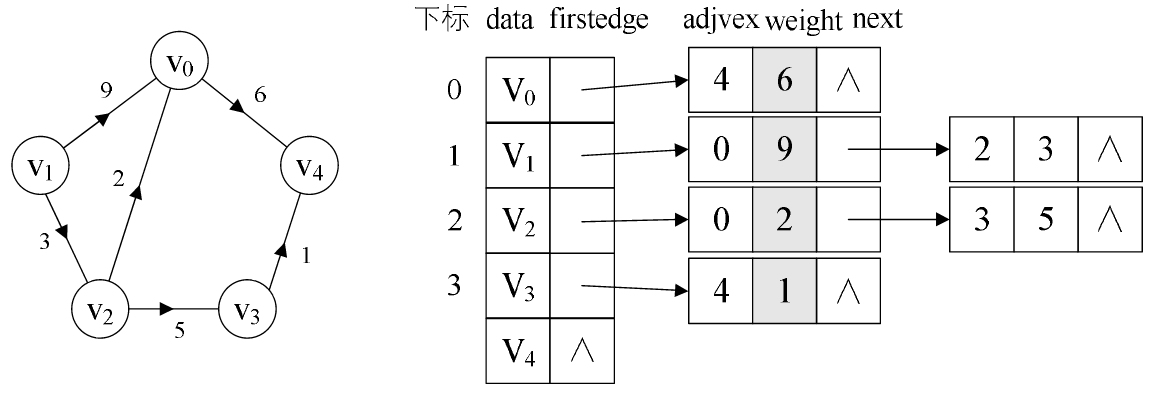
从上图中我们知道, 顶点表的各个结点由 data 和 firstedge 两个域表示, data 是数据域, 存储顶点的信息,
firstedge 是指针域, 指向边表的第一个结点, 即此顶点的第一个邻接点. 边表结点由 adjvex 和 next 两个域组成.
adjvex 是邻接点域, 存储某顶点的邻接点在顶点表中的下标, next 则存储指向边表中下一个结点的指针. 例如:
V1 顶点与 V0, V2 互为邻接点, 则在 V1 的边表中,adjvex 分别为 V0 的 0 和 V2 的 2.
PS: 对于无向图来说, 使用邻接表进行存储也会出现数据冗余的现象. 例如上图中, 顶点 V0 所指向的链表中存
在一个指向顶点 V3 的同时,顶点 V3 所指向的链表中也会存在一个指向 V0 的顶点。
(2) 有向图: 若是有向图, 邻接表结构是类似的,但要注意的是有向图由于有方向的. 因此, 有向图的邻接表分为
出边表和入边表(又称逆邻接表), 出边表的表结点存放的是从表头结点出发的有向边所指的尾结点; 入边表的表
结点存放的则是指向表头结点的某个顶点, 如下图所示.
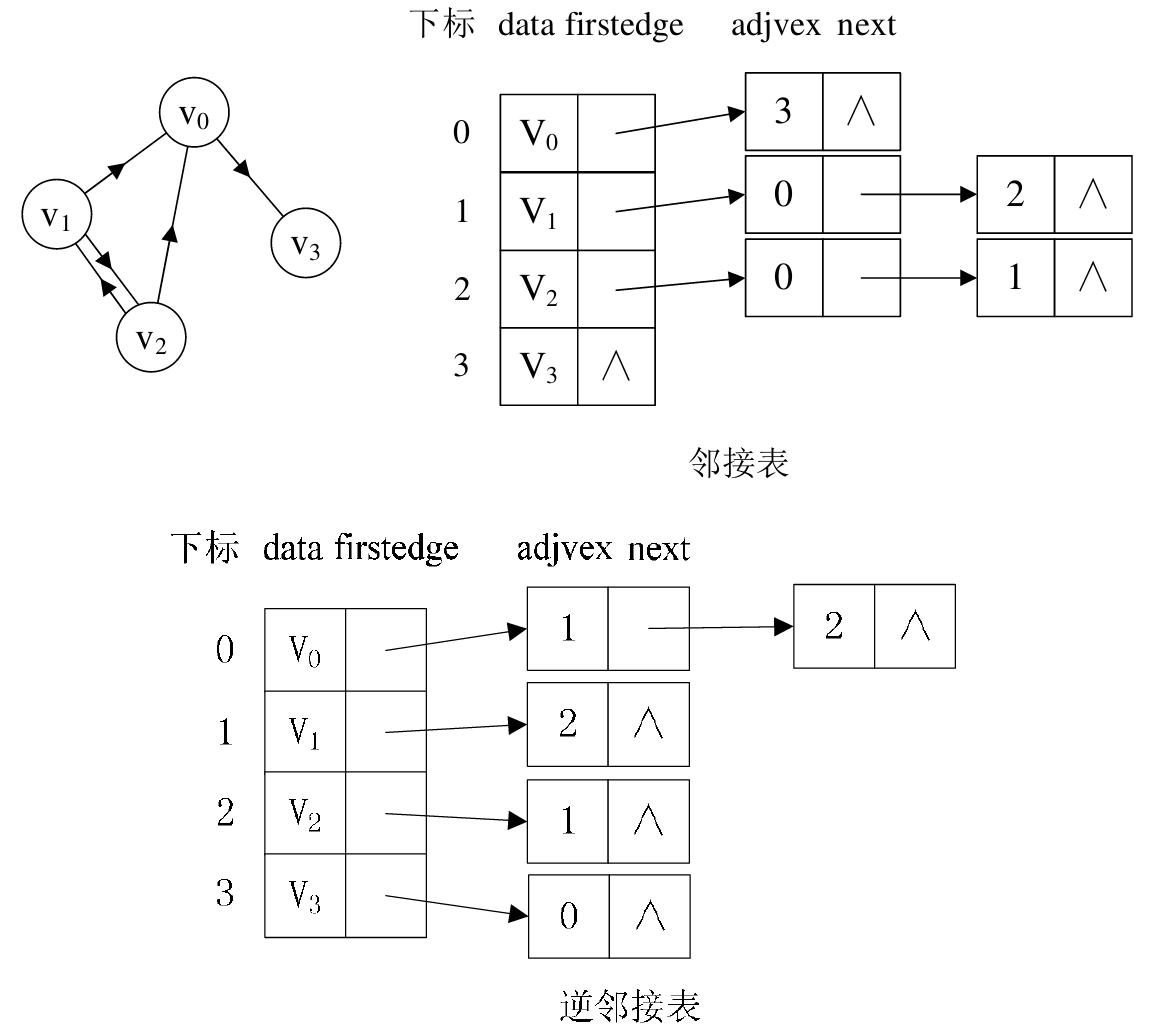
(3) 带权图: 对于带权值的网图, 可以在边表结点定义中再增加一个 weight 的数据域, 存储权值信息即可, 如下
图所示.
3.1 深度优先搜索图文介绍
3.1.1 深度优先搜索介绍
图的深度优先搜索(Depth First Search),我们再重复重复加深理解. 我们介绍下它的搜索步骤: 假设初始
状态是图中所有顶点均未被访问, 则从某个 顶点(结点) v 出发, 首先访问该顶点, 然后依次从它的各个未被访问
的邻接点出发深度优先搜索遍历图, 直至图中所有和 顶点 v 有路径相通的顶点都被访问到. 若此时, 尚有其他顶
点未被访问到, 则另选一个未被访问的顶点作起始点, 重复上述过程, 直至图中所有顶点都被访问到为止. 显然,
深度优先搜索对于图这类结构很容易被递归过程所构造.
3.1.2 深度优先搜索图解
3.1.2.1 无向图的深度优先搜索
下面以"无向图"为例, 来对深度优先搜索进行演示.
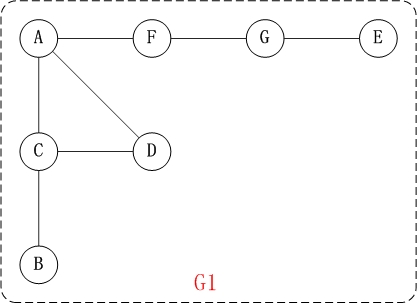
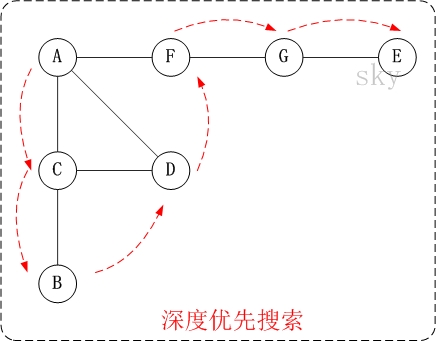
对上面的 图 G1 进行深度优先遍历,从 顶点 A 开始.
第1步: 访问 A.
第2步: 访问(A 的邻接点) C.
在 第1步 访问 A 之后, 接下来应该访问的是 A 的邻接点, 即 "C, D, F" 中的一个. 但在本文的实现中,
顶点 ABCDEFG 是按照顺序存储,C在"D和F"的前面,因此,先访问C.
第3步: 访问(C 的邻接点) B.
在 第2步 访问 C 之后, 接下来应该访问 C 的邻接点, 即 "B和D" 中一个(A已经被访问过,就不算在内)
. 而由于 B 在 D 之前, 先访问 B.
第4步: 访问(C 的邻接点) D.
在 第3步 访问了 C 的邻接点 B 之后, B 没有未被访问的邻接点; 因此, 返回访问 C 的另一个邻接点 D.
第5步: 访问(A 的邻接点) F.
前面已经访问了 A, 并且访问完了 "A 的邻接点 B 的所有邻接点(包括递归的邻接点在内)"; 因此, 此时
返回到访问A的另一个邻接点F。
第6步: 访问(F 的邻接点) G.
第7步: 访问(G 的邻接点) E.
因此访问顺序是: A -> C -> B -> D -> F -> G -> E
3.1.2.2 有向图的深度优先搜索
下面以"有向图"为例, 来对深度优先搜索进行演示.
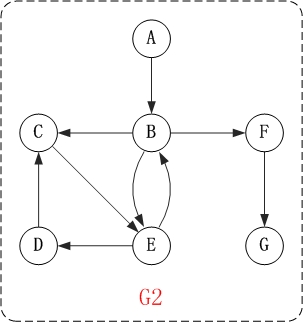
对上面的 图 G2 进行深度优先遍历, 从 顶点 A 开始.
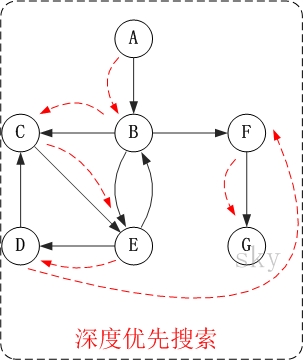
第1步: 访问 A.
第2步: 访问 B.
在访问了 A 之后, 接下来应该访问的是 A 的出边的另一个顶点, 即顶点 B.
第3步: 访问 C.
在访问了 B 之后, 接下来应该访问的是 B 的出边的另一个顶点, 即 顶点 C, E, F. 在本文实现的图中, 顶
点 ABCDEFG 按照顺序存储, 因此先访问 C.
第4步: 访问 E.
接下来访问 C 的出边的另一个顶点, 即顶点 E.
第5步: 访问 D.
接下来访问 E 的出边的另一个顶点, 即 顶点 B, D. 顶点 B 已经被访问过, 因此访问 顶点 D.
第6步: 访问 F.
接下应该回溯"访问 A 的出边的另一个顶点 F".
第7步: 访问 G.
因此访问顺序是: A -> B -> C -> E -> D -> F -> G
3.2 广度优先搜索图文介绍
3.2.1 广度优先搜索介绍
广度优先搜索算法(Breadth First Search), 又称为"宽度优先搜索"或"横向优先搜索", 简称BFS. 它的遍历
常规思路是: 从图中某顶点(结点) v 出发, 在访问了 v 之后依次访问 v 的各个未曾访问过的邻接点, 然后分别从
这些邻接点出发依次访问它们的邻接点, 并使得"先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问
, 直至图中所有已被访问的顶点的邻接点都被访问到. 如果此时图中尚有顶点未被访问, 则需要另选一个未曾被
访问过的顶点作为新的起始点, 重复上述过程, 直至图中所有顶点都被访问到为止. 换句话说, 广度优先搜索遍历
图的过程是以 v 为起点, 由近至远, 依次访问和 v 有路径相通且'路径长度'为 1, 2 ... 的顶点.
3.2.2 广度优先搜索图解
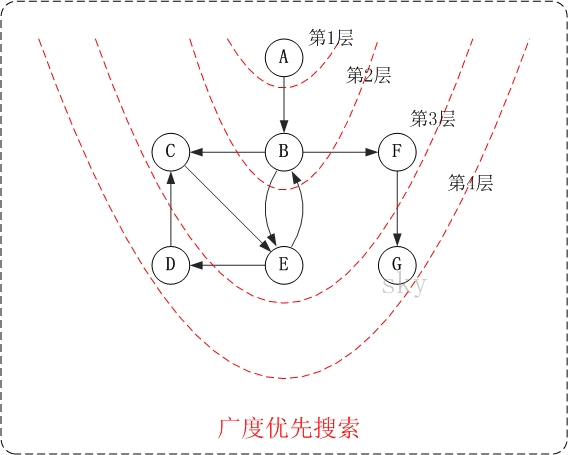
3.2.2.1 无向图的广度优先搜索
下面以"无向图"为例, 来对广度优先搜索进行演示. 还是以上面的 图 G1 为例进行说明.
第1步: 访问 A.
第2步: 依次访问 C, D, F.
在访问了 A 之后,接下来访问 A 的邻接点. 前面已经说过, 在本文实现中, 顶点 ABCDEFG 按照顺序存储
的, C 在 "D 和 F" 的前面, 因此, 先访问 C. 再访问完 C 之后, 再依次访问 D, F.
第3步: 依次访问 B, G.
在 第2步 访问完 C, D, F 之后, 再依次访问它们的邻接点. 首先访问 C 的邻接点 B, 再访问 F 的邻接点 G.
第4步: 访问 E.
在 第3步 访问完 B, G 之后, 再依次访问它们的邻接点. 只有 G 有邻接点 E, 因此访问 G 的邻接点 E.
因此访问顺序是: A -> C -> D -> F -> B -> G -> E
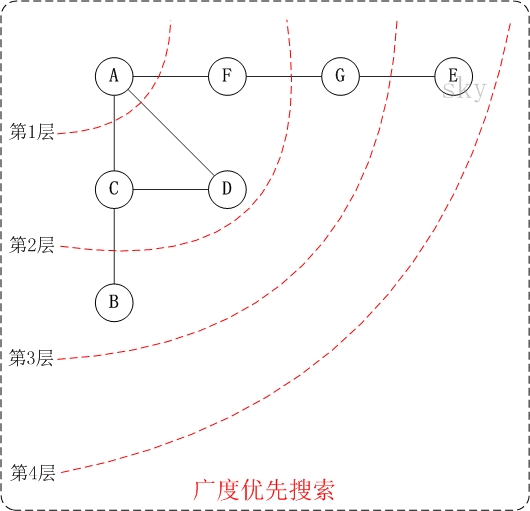
3.2.2.2 有向图的广度优先搜索
下面以"有向图"为例, 来对广度优先搜索进行演示. 还是以上面的 图 G2 为例进行说明.
第1步: 访问 A.
第2步: 访问 B.
第3步: 依次访问 C, E, F.
在访问了 B 之后, 接下来访问 B 的出边的另一个顶点, 即 C, E, F. 前面已经说过, 在本文实现中,顶点
ABCDEFG 按照顺序存储的, 因此会先访问 C, 再依次访问 E, F.
第4步: 依次访问 D, G.
在访问完 C, E, F 之后, 再依次访问它们的出边的另一个顶点. 还是按照 C, E, F 的顺序访问, C 的已经全部
访问过了, 那么就只剩下 E, F; 先访问 E 的邻接点 D, 再访问 F 的邻接点 G.
因此访问顺序是:A -> B -> C -> E -> F -> D -> G