Hbase特点
HBase是一个构建在HDFS上的分布式列存储系统;
HBase是基于Google BigTable模型开发的,典型的key/value系统;
HBase是Apache Hadoop生态系统中的重要一员,主要用于海量结构化数据存储;
从逻辑上讲,HBase将数据按照表、行和列进行存储。
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
Hbase 储存原理
HBase不是一个关系型数据库,它需要不同的方法定义你的数据模型,HBase实际上定义了一个四维数据模型,下面就是每一维度的定义:
行键:每行都有唯一的行键,行键没有数据类型,它内部被认为是一个字节数组。
列簇:数据在行中被组织成列簇,每行有相同的列簇,但是在行之间,相同的列簇不需要有相同的列修饰符。在引擎中,HBase将列簇存储在它自己的数据文件中,所以,它们需要事先被定义,此外,改变列簇并不容易。
列修饰符:列簇定义真实的列,被称之为列修饰符,你可以认为列修饰符就是列本身。
版本:每列都可以有一个可配置的版本数量,你可以通过列修饰符的制定版本获取数据
RowKey:是Byte array,是表中每条记录的“主键”,方便快速查找,Rowkey的设计非常重要。
Column Family:列族,拥有一个名称(string),包含一个或者多个相关列
Column:属于某一个columnfamily,familyName:columnName,每条记录可动态添加
Version Number:类型为Long,默认值是系统时间戳,可由用户自定义
Value(Cell):Byte array
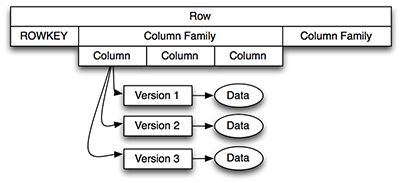
Hbase 物理储存模型
每个column family存储在HDFS上的一个单独文件中,空值不会被保存。
Key 和 Version number在每个 column family中均有一份;
HBase 为每个值维护了多级索引,即:<key, column family, column name, timestamp>
物理储存
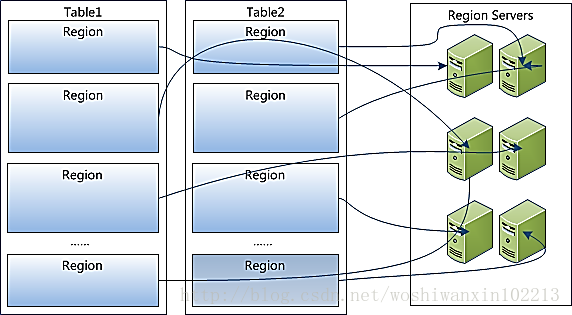
1,table中所有的行都是按照row key的字典排序
2,table在行方向上分割为多个Region
3,Region按大小分割,每个表做出一个region 随着数据的增加,达到一个值只够
就会自动拆分,之后会越来越多的Region
4,Region是Hbase中分布式储存和负载均衡的最小单元
不同的Region 分布到不同的RegionServer上
5,Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个store保存一个columns family;每个Strore又由一个memStore和0至多个StoreFile组成,StoreFile包含HFile;memStore存储在内存中,StoreFile存储在HDFS上
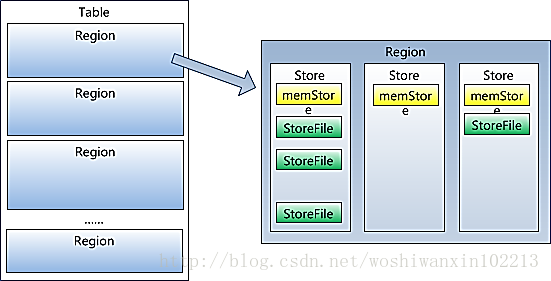
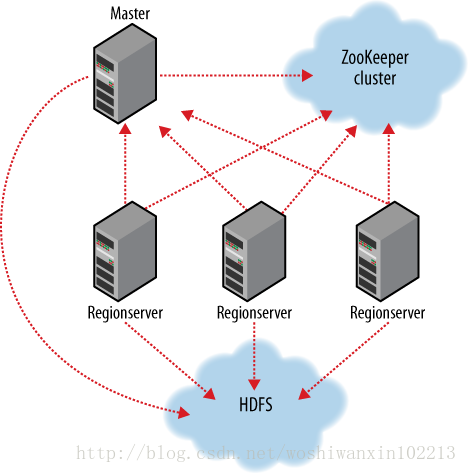
Hbase架构及基本组件
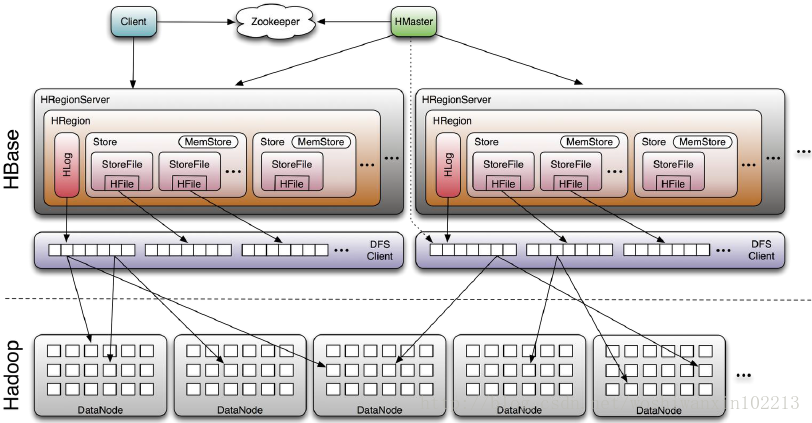
Hbase基本组件说明
Client
包含访问hbase的接口,并维护cache来加快对HBase的访问,比如region的位置信息
Master
1为region server 分配region
2负责region server 的负载均衡
3发现生效的region server并重新分配其他的region
4管理用户对表的增删改查
Region server
1 region server维护region 处理对这些region'的io请求
2 region server 负责切分运行过程中变大的region
Zookeeoer
1 通过选举,保证任何时候,集群中只有一个master master与regionservers启动时会向zooker注册
2储存所有region的寻址入口
3实时监控region server的上下线信息,并实时给master
4 储存hbase的schema和table元数据
5默认下 hbase管理zooeeper的实例,比如启动或者停止zookeeper
6 zookeeper 的引入使得master不再是单点故障
write-ahead-Log(wal)
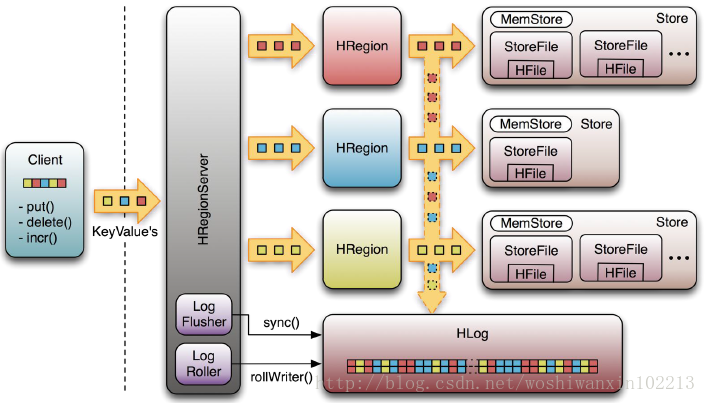
该机制用于数据的容错和恢复:
每个HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead Log的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中(HLog文件格式见后续),HLog文件定期会滚动出新的,并删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的 HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取 到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复
HBase容错性
Master容错:Zookeeper重新选择一个新的Master
ü无Master过程中,数据读取仍照常进行
ü无master过程中,region切分、负载均衡等无法进行
RegionServer容错:定时向Zookeeper汇报心跳,如果一旦时间内未出现心跳,Master将该RegionServer上的Region重新分配到其他RegionServer上,失效服务器上“预写”日志由主服务器进行分割并派送给新的RegionServer
Zookeeper容错:Zookeeper是一个可靠地服务,一般配置3或5个Zookeeper实例
Region定位流程: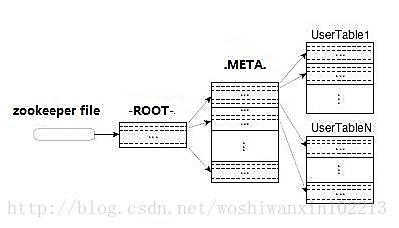
寻找RegionServer
ZooKeeper--> -ROOT-(单Region)--> .META.--> 用户表
-ROOT-
ü表包含.META.表所在的region列表,该表只会有一个Region;
üZookeeper中记录了-ROOT-表的location。
.META.
表包含所有的用户空间region列表,以及RegionServer的服务器地址。
Hbase使用场景
1大数据量的存储,大数据量高并发的操作
2需要对数据的随机的读写操作
3读写均是简单的操作
Hdfs 适合批处理场景不支持数据的随机查找 不支持增量数据的查找
不支持数据的更新
参考地址http://blog.csdn.net/woshiwanxin102213/article/details/17584043
Hbase shell 使用
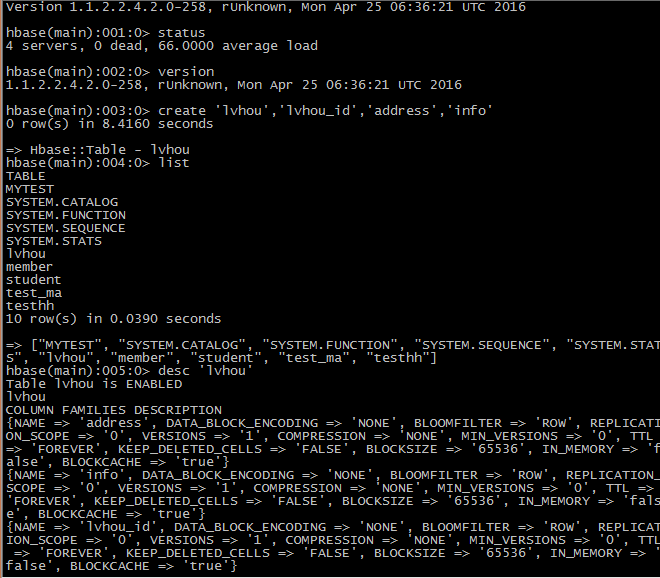
使用hbase shell 进入命令行
1 查询服务器状态
Status
2创建表
注意不能加:
Create ‘lvhou’,’lvhou_id’,’address’,’info’
3获取表的结构 及查看表
List
Desc ‘lvhou’
4 删出一个列族
Disable ‘lvhou’
Alter ‘member’,{NAME=>’address’,METHOD=>’delete’}
Desc ‘lvhou’
Enable ‘lvhou’
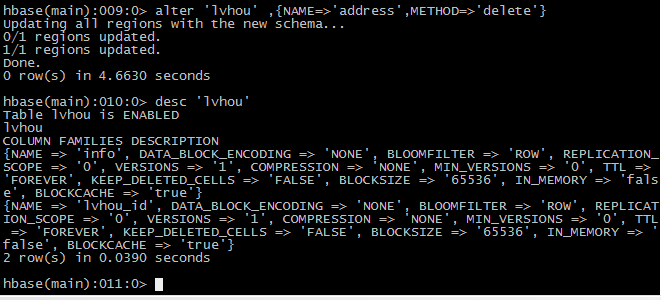
5 删除一个表
删之前一定要设置表不可用
Disable ‘lvhou’
Drop ‘lvhou’
Desc ‘lvhou’
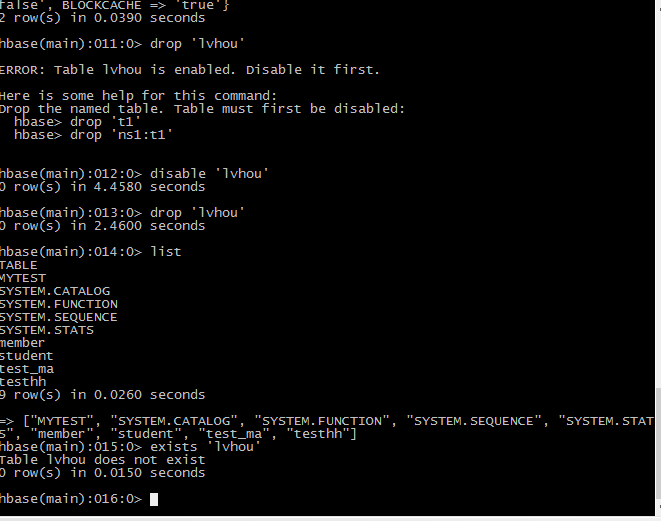
6将表重新创建回来
Create ‘lvhou’,’lvhou_id’,’addrss’,’info’
7插入数据
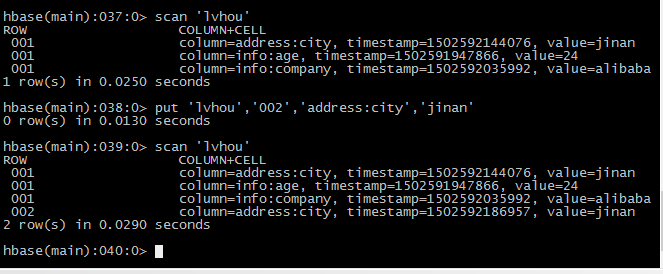
8查询数据
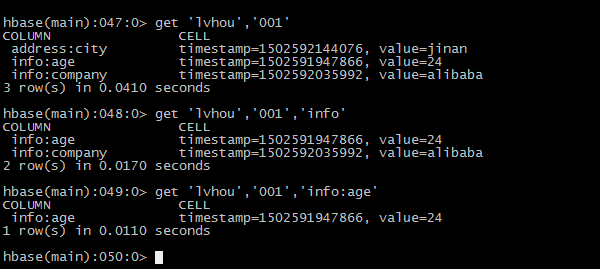
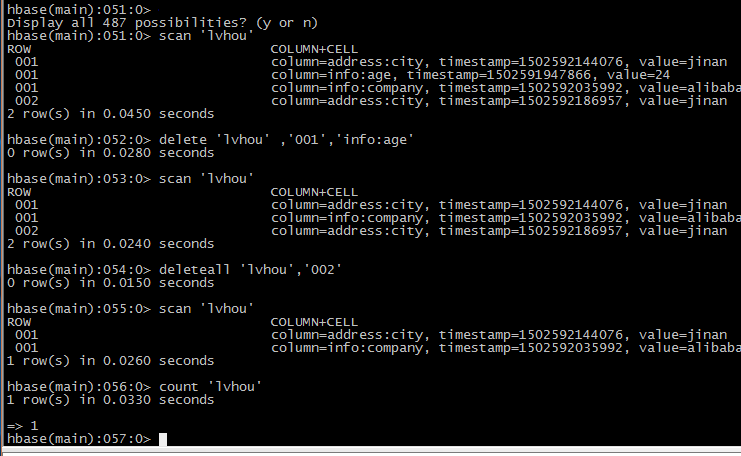
扫描全表
删除id=‘001’的info:age字段
删除整行
查询表中的行数
将整张表清空

使用hive操作表
首先在hbase中创建表
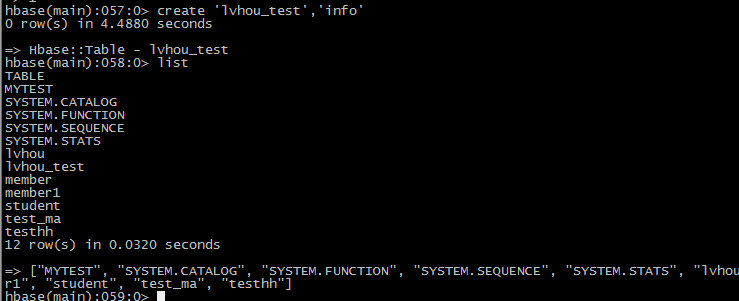
2在hive中创建表

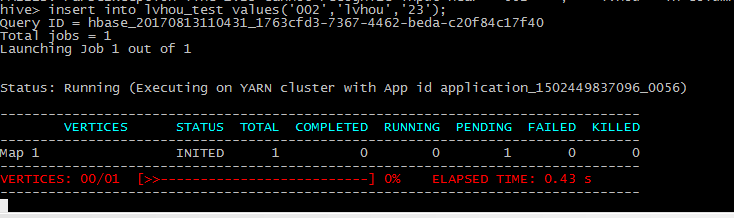
3在hive插入数据
在hbase中查寻

PHOENIX操作
登陆到phoenix
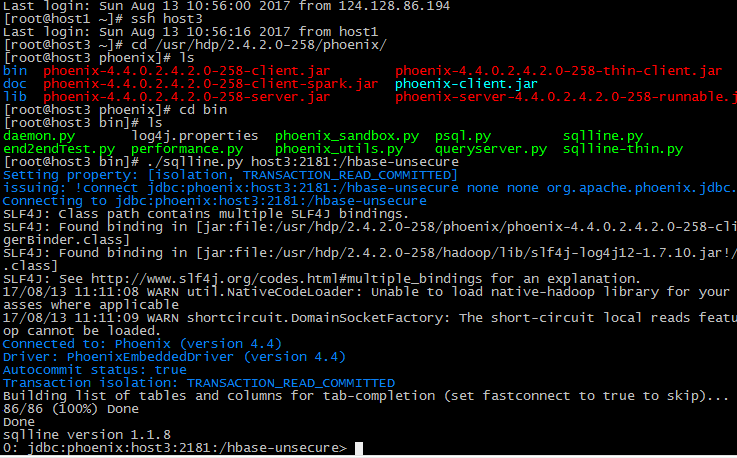
查看表
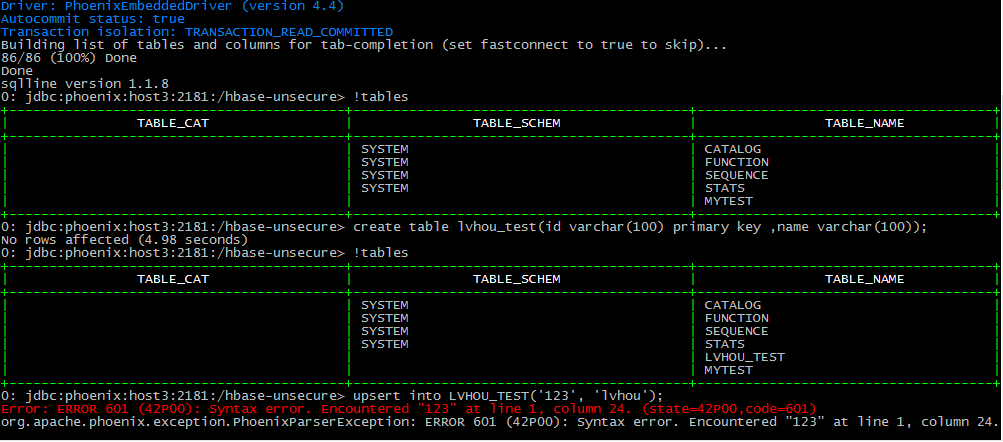
插入数据

查看数据

查看hbase数据

官网phoenix总结
1select
Select * from lvhou_test limit 1000;
从一个或多个表中选择数据。UNION ALL组合来自多个select语句的行。ORDER BY根据给定的表达式对结果进行排序。LIMIT(或FETCH FIRST)限制查询返回的行数,如果未指定或指定为null或小于零,则不应用限制。的LIMIT(或FETCH FIRST)子句后执行ORDER BY,以支持前N个类型的查询子句。OFFSET子句在开始返回行之前跳过很多行。可选的提示可用于覆盖由查询优化器做出的决定。
SELECT * FROM TEST LIMIT 1000;
SELECT * FROM TEST LIMIT 1000 OFFSET 100;
SELECT full_name FROM SALES_PERSON WHERE ranking >= 5.0
UNION ALL SELECT reviewer_name FROM CUSTOMER_REVIEW WHERE score >= 8.0
2 Upsert values
如果不存在则插入,否则更新表中的值。列的列表是可选的,如果不存在,则值将按照它们在模式中声明的顺序映射到列。值必须计算为常数。
ON DUPLICATE KEY如果您需要UPSERT原子,请使用该条款(Phoenix 4.9中提供)。在这种情况下,性能会更慢,因为在完成提交时需要在服务器端读取该行。使用IGNORE,如果你不是要不要UPSERT,如果行已存在执行。否则,UPDATE表达式将被评估,并且用于设置列的结果,例如执行原子增量。一个UPSERT以相同的同一行提交的批处理将在执行顺序进行处理。
例:
UPSERT INTO TEST VALUES('foo','bar',3);
UPSERT INTO TEST(NAME,ID) VALUES('foo',123);
UPSERT INTO TEST(ID, COUNTER) VALUES(123, 0) ON DUPLICATE KEY UPDATE COUNTER = COUNTER + 1;
UPSERT INTO TEST(ID, MY_COL) VALUES(123, 0) ON DUPLICATE KEY IGNORE;
Upsert select
如果不存在插入,并根据运行另一个查询的结果更新表中的行。这些值根据源和目标表之间的匹配位置来设置。列的列表是可选的,如果不存在,将按照它们在模式中声明的顺序映射到列。如果自动提交开启,并且a)目标表与源表匹配,并且b)select不执行聚合,则目标表的总体将在服务器端完成(具有约束违反记录但是否则忽略)。否则,在客户端上缓存数据,如果自动提交开启,则按照UpsertBatchSize连接属性(或phoenix.mutate.upsertBatchSize HBase配置属性默认为10000行)按行批处理提交数据,
例:
UPSERT INTO test.targetTable(col1, col2) SELECT col3, col4 FROM test.sourceTable WHERE col5 < 100
UPSERT INTO foo SELECT * FROM bar;
3 Delete
删除where子句选择的行。如果自动提交开启,则删除完全由服务器端执行。
例:
DELETE FROM TEST;
DELETE FROM TEST WHERE ID=123;
DELETE FROM TEST WHERE NAME LIKE 'foo%';
4 Crteate table
创建一个新表。HBase引用的表和列族如果不存在,将被创建。除非是双引号,否则所有表,列系列和列名都是高位,在这种情况下,它们是区分大小写的。HBase表中存在但未列出的列系列将被忽略。在创建时,为了提高查询性能,如果没有明确定义列族,则将空键值添加到任何现有行或默认列族的第一列系列中。Upserts还将添加这个空键值。这可以通过拥有一个键值列来提高查询性能,我们可以保证始终存在,从而最小化必须投影并随后返回给客户端的数据量。HBase表和列配置选项可以作为键/值对传递,以HBase根据需要配置表。请注意,当使用该IF NOT EXISTS子句时,如果表已经存在,则不会对此进行任何更改。另外,没有验证是否检查现有的表元数据是否与提出的表元数据相匹配。所以最好使用DROP TABLE后面CREATE TABLE是表元数据可能会改变。
例:
CREATE TABLE my_schema.my_table ( id BIGINT not null primary key, date)
CREATE TABLE my_table ( id INTEGER not null primary key desc, date DATE not null,
m.db_utilization DECIMAL, i.db_utilization)
m.DATA_BLOCK_ENCODING='DIFF'
CREATE TABLE stats.prod_metrics ( host char(50) not null, created_date date not null,
txn_count bigint CONSTRAINT pk PRIMARY KEY (host, created_date) )
CREATE TABLE IF NOT EXISTS "my_case_sensitive_table"
( "id" char(10) not null primary key, "value" integer)
DATA_BLOCK_ENCODING='NONE',VERSIONS=5,MAX_FILESIZE=2000000 split on (?, ?, ?)
CREATE TABLE IF NOT EXISTS my_schema.my_table (
org_id CHAR(15), entity_id CHAR(15), payload binary(1000),
CONSTRAINT pk PRIMARY KEY (org_id, entity_id) )
TTL=86400
5 Drop table
放一张桌子 可选CASCADE关键字也会导致表上的任何视图都被删除。删除表时,默认情况下,底层HBase数据和索引表将被删除。phoenix.schema.dropMetaData可用于覆盖此值,并保留HBase时间点查询的表。
例:
DROP TABLE my_schema.my_table;
DROP TABLE IF EXISTS my_table;
DROP TABLE my_schema.my_table CASCADE;