结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
结合中断上下文切换和进程上下文切换分析Linux内核一般执行过程
- 以fork和execve系统调用为例分析中断上下文的切换
- 分析fork子进程启动执行时进程上下文的特殊之处
- 分析execve系统调用中断上下文的特殊之处
- 以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
一、系统调用中断上下文的切换(以fork及execve为例分析)
-
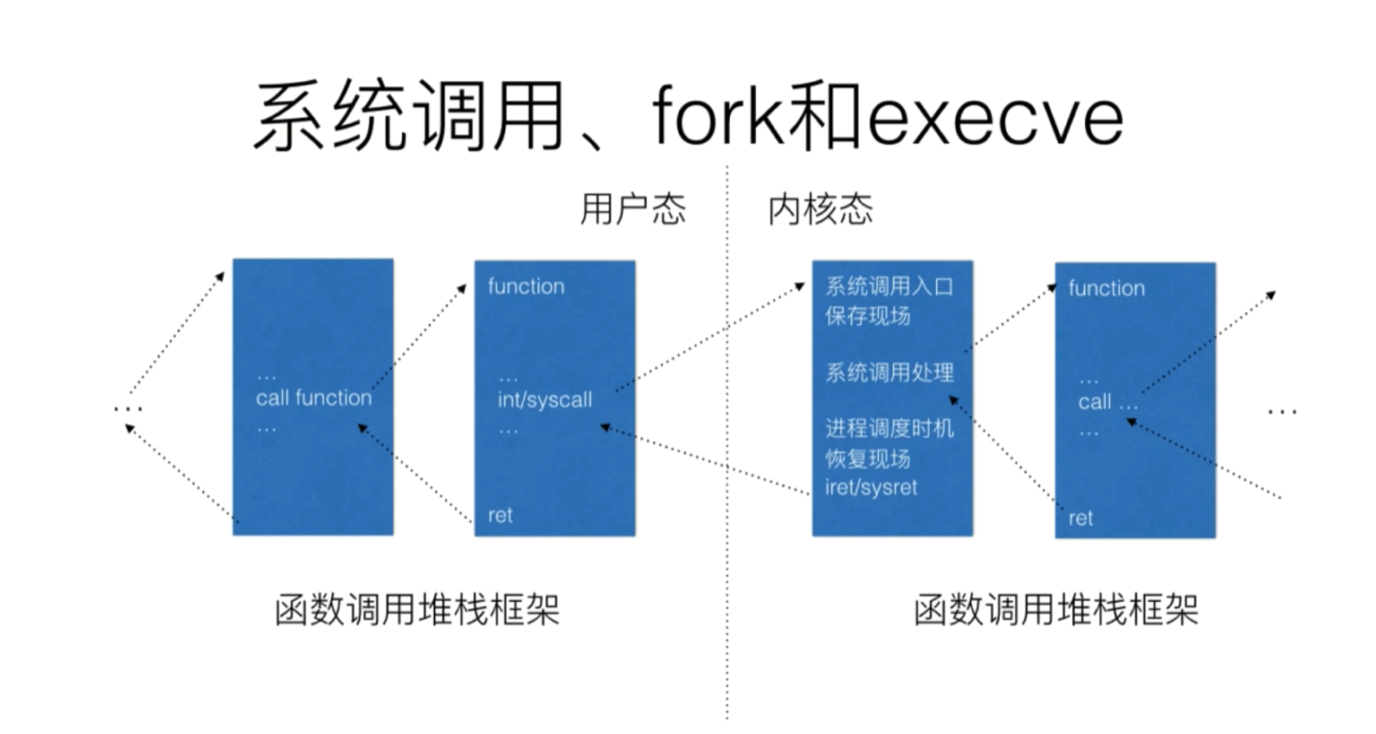
系统调用
系统调用利用陷阱来实现,是异常的一种,从而从用户态进⼊到内核态。- 系统调用能将用户从底层的硬件编程中解放出来。操作系统为我们管理硬件,⽤户态进程不用直接与硬件设备打交道。
- 同时极⼤地提高系统的安全性。如果用户态进程直接与硬件设备打交道,会产⽣安全隐患,可能引起系统崩溃。
- 使得用户程序具有可移植性。
-
一般的系统调用
-
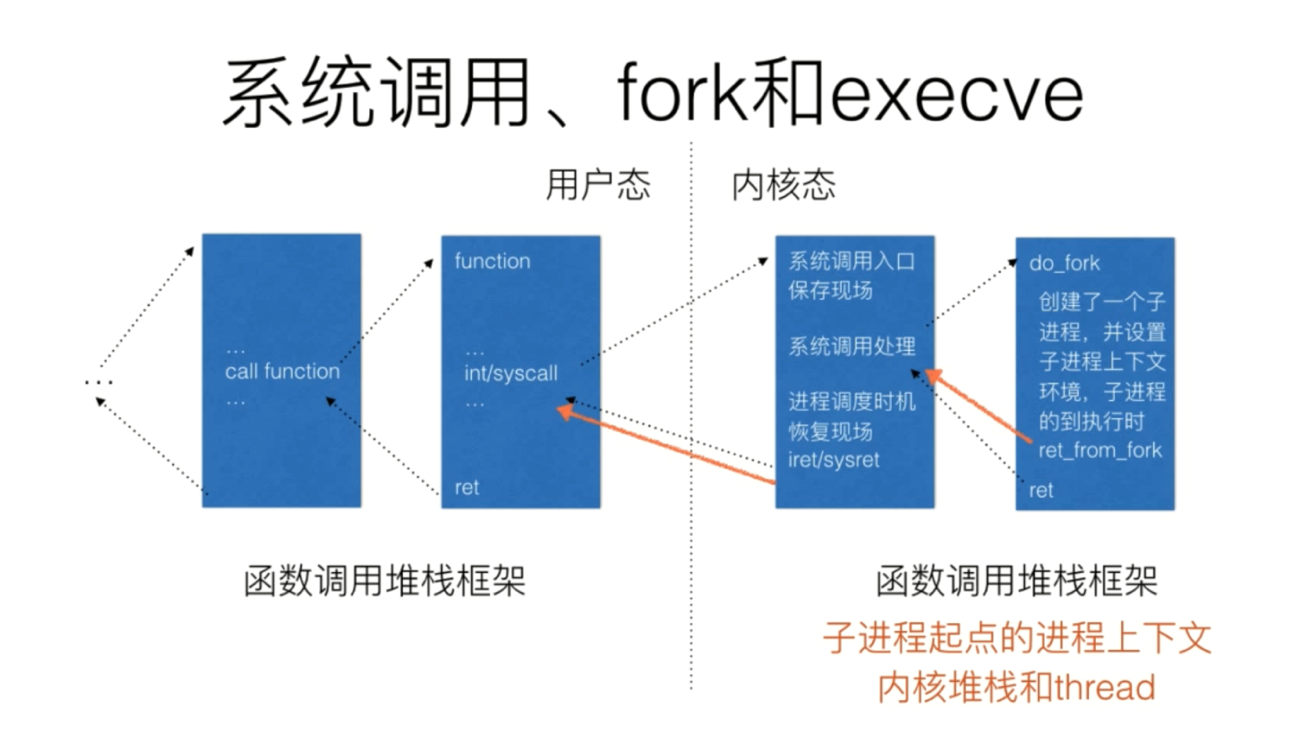
fork 系统调用过程
fork系统调用用于创建一个新进程,称为子进程,它与进程(称为系统调用fork的进程)同时运行,此进程称为父进程。创建新的子进程后,两个进程将执行fork()系统调用之后的下一条指令。子进程使用相同的pc(程序计数器),相同的CPU寄存器,在父进程中使用的相同打开文件。它不需要参数并返回一个整数值。下面是fork()返回的不同值。一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程(child process)。fork函数被调用一次但返回两次。两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。因此,可以通过返回值来判定该进程是父进程还是子进程
子进程是父进程的副本,它将获得父进程数据空间、堆、栈等资源的副本。子进程持有的是上述存储空间的“副本”,这意味着父子进程间不共享这些存储空间。UNIX将复制父进程的地址空间内容给子进程,因此,子进程有了独立的地址空间。fork调用一次,返回两次,这两个返回分别带回它们各自的返回值,其中在父进程中的返回值是子进程的进程号,而子进程中的返回值则返回 0。
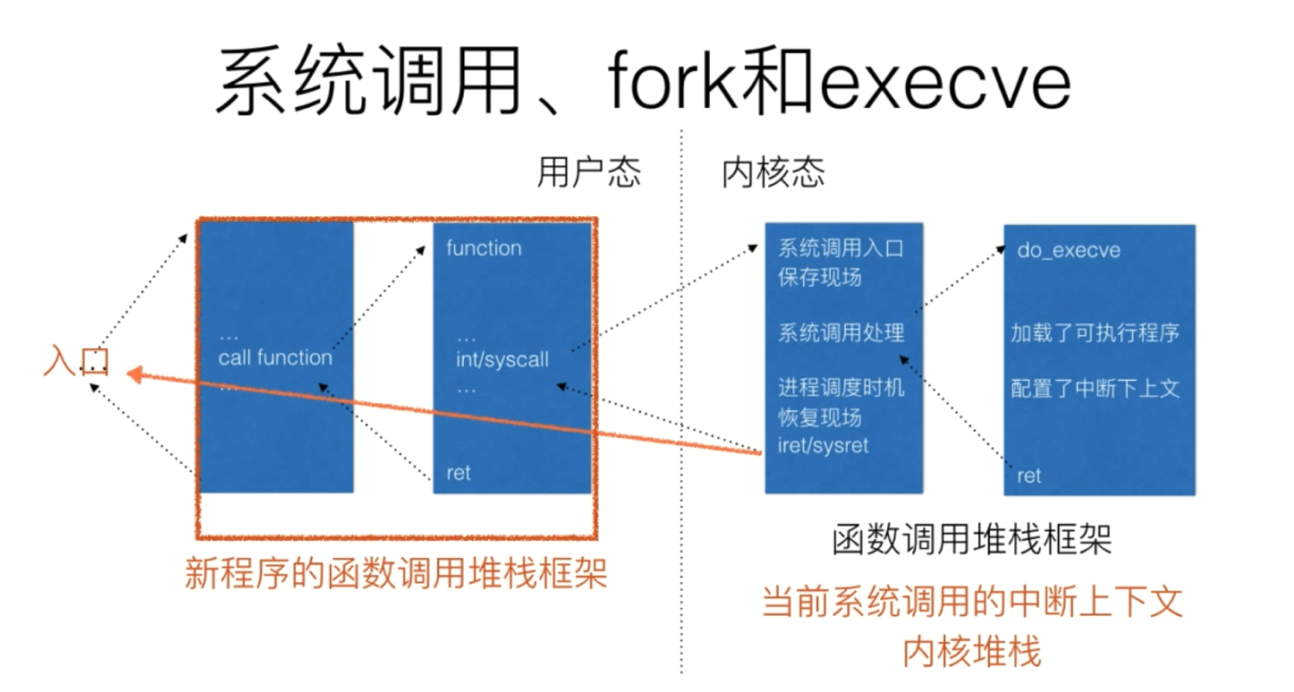
- execve系统调用
Linux系统⼀般会提供了execl、 execlp、 execle、 execv、 execvp和execve等6个⽤以加载执⾏⼀个可执⾏⽂件的库函数,这些库函数统称为exec函数,差异在于对命令⾏参数和环境变量参数的传递⽅式不同。 exec函数都是通过execve系统调⽤进⼊内核,对应的系统调⽤内核处理函数为__x64_sys_execve,它们都是通过调⽤do_execve来具体执⾏加载可执⾏⽂件的⼯作。
整体的调用关系为如下
- __x64_sys_execve
- do_execve()
- do_execveat_common()
- __do_execve_file
- exec_binprm()
- search_binary_handler()
- load_elf_binary()
- start_thread()
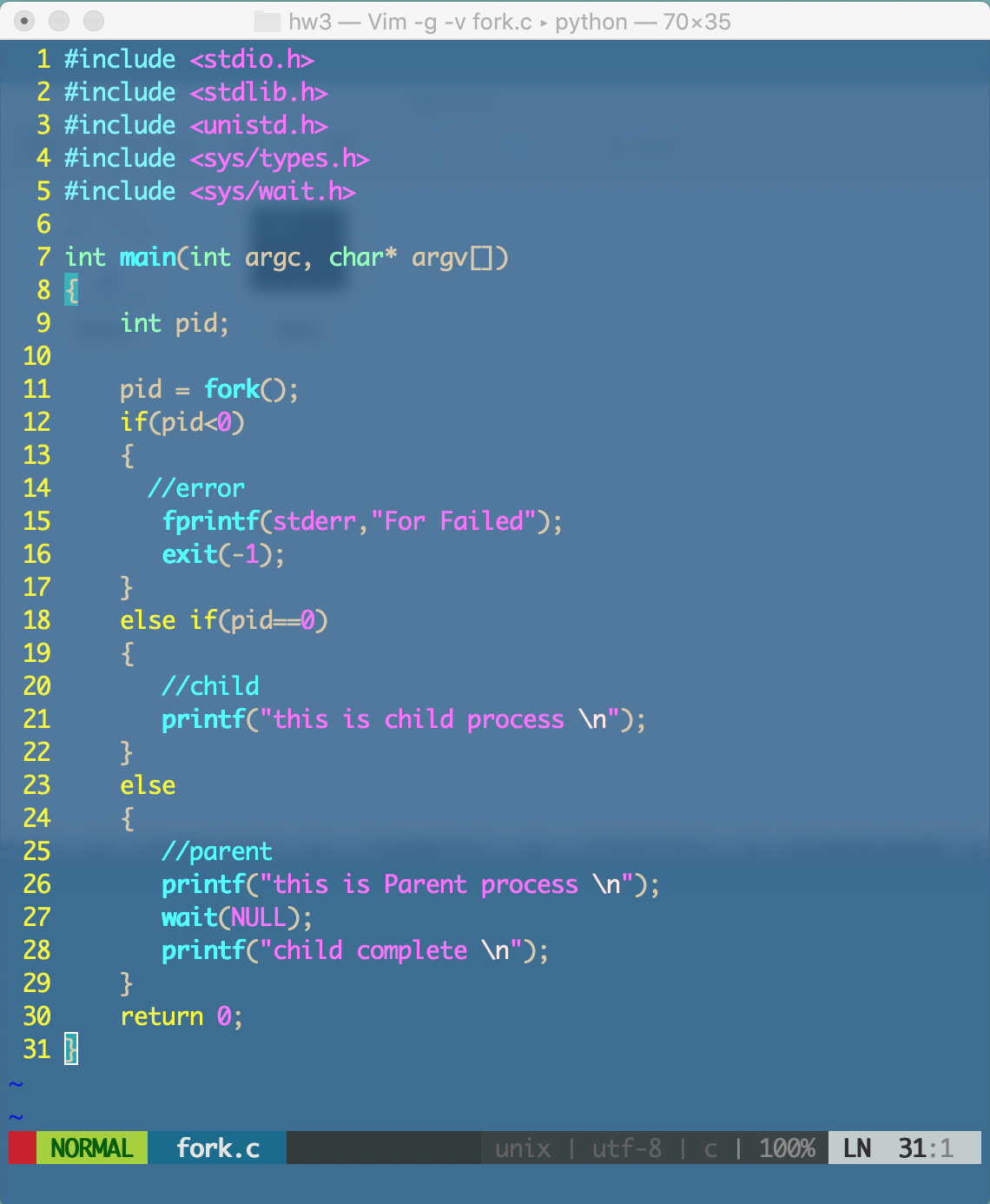
二、fork系统调用
(1) fork调用程序
(2) 编译执行
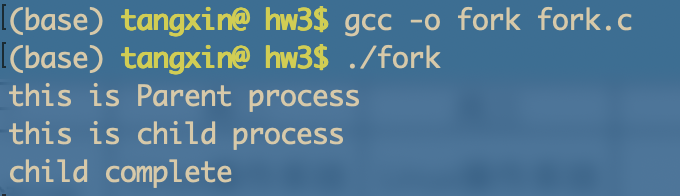
(3) 反汇编来查看fork系统调用过程
objdump -S fork > fork.s
打开fork.s文件可查询如下:

(4) 查看系统文件
通过查看汇编代码已知调用了56号系统调用,查询/linux-5.4.34/arch/x86/entry/syscalls/syscall_64.tbl 有:
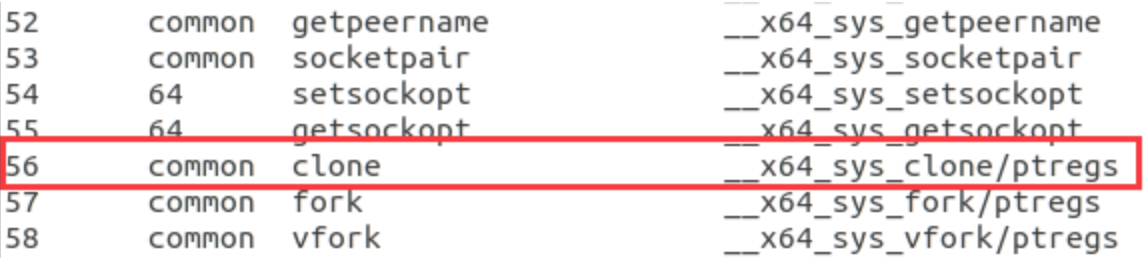
即内核函数调用__64_sys_clone,通过查询linux-5.4.34/kernel/fork.c 可确定sys_clone的函数返回值为do_fork()。
(5)通过gdb查看fork运行函数栈
在__x64_sys_clone, _do_fork, copy_process, dup_task_struct, copy_thread_tls 上设置断点,并运行fork查看此时的函数栈。
qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz -S -s -nographic -append "console=ttyS0"
gdb vmlinux
- 设置断点

- 运行
./fork,在每个断点通过bt查看堆栈



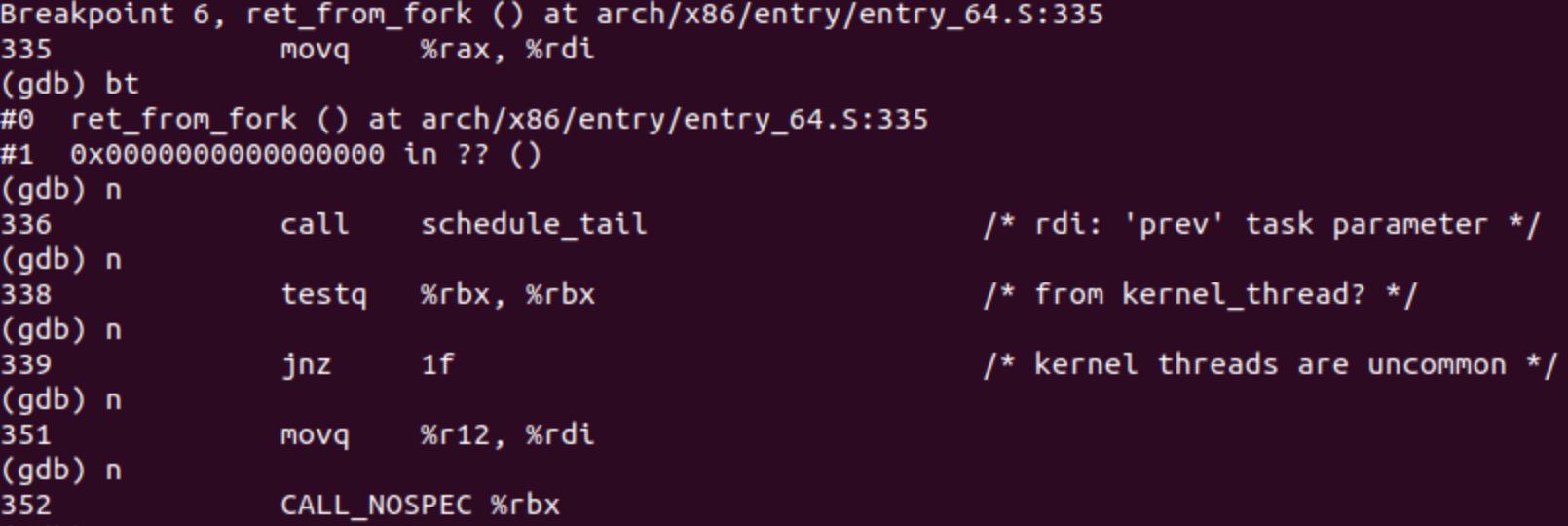
三、execve系统调用
- 通过查看堆栈可发现
execve系统调用的堆栈情况如下:
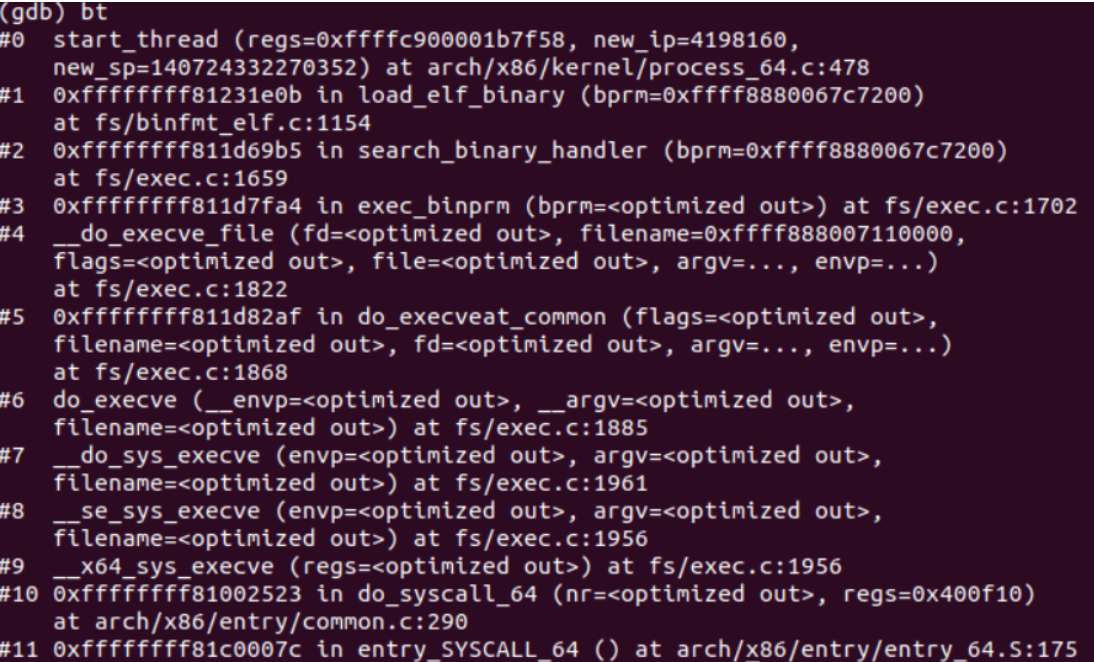
sys_execve的核心是调用do_execve函数,传给do_execve的第一个参数是已经拷贝到内核空间的路径名filename,第二个和第三个参数仍然是系统调用execve的第二个参数argv和第三个参数envp,它们代表的传给可执行文件的参数和环境变量仍然保留在用户空间中。
四、Linux系统的一般执行过程
Linux中断分为两个半部:上半部(tophalf)和下半部(bottom half)。
上半部的功能是"登记中断",当一个中断发生时,它进行相应地硬件读写后就把中断例程的下半部挂到该设备的下半部执行队列中去。因此,上半部 执行的速度就会很快,可以服务更多的中断请求。但是,仅有"登记中断"是远远不够的,因为中断的事件可能很复杂。
因此,Linux引入了一个下半部,来完 成中断事件的绝大多数使命。下半部和上半部最大的不同是下半部是可中断的,而上半部是不可中断的,下半部几乎做了中断处理程序所有的事情,而且可以被新的中断打断,下半部则相对来说并不是非常紧急的,通常还是比较耗时的,因此由系统自行安排运行时机,不在中断服务上下文中执行。在Linux驱动程序中,为设备实现一个中断包含两个步骤:
1)向内核注册中断
2)实现中断处理函数,其中request_irq用于实现中断的注册功能:int request_irq(unsigned int irq, void (*handler)(int, void*, struct pt_regs *), unsigned long flags, const char *devname, void *dev_id)
-
进程上下文
当一个进程在执行时,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容被称为该进程的上下文。
当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的上下文,以便在再次执行该进程时,能够必得到切换时的状态执行下去。
在LINUX中,当前进程上下文均保存在进程的任务数据结构中。在发生中断时,内核就在被中断进程的上下文中,在内核态下执行中断服务例程。但同时会保留所有需要用到的资源,以便中断服务结束时能恢复被中断进程的执行。 -
进程调度时机
- ⽤户进程上下⽂中主动调⽤特定的系统调⽤进⼊中断上下⽂,系统调⽤返回⽤户态之前进⾏进程调度。
- 内核线程或可中断的中断处理程序,执⾏过程中发⽣中断进⼊中断上下⽂,在中断返回前进⾏进程调度。
- 内核线程主动调⽤schedule函数进⾏进程调度。
- 中断处理程序执⾏过程主动调⽤schedule函数进⾏进程调度,与前述两类调度时机对应
-
上下文切换
上下文切换 , 其实际含义是任务切换, 或者CPU寄存器切换。当多任务内核决定运行另外的任务时, 它保存正在运行任务的当前状态, 也就是CPU寄存器中的全部内容。这些内容被保存在任务自己的堆栈中, 入栈工作完成后就把下一个将要运行的任务的当前状况从该任务的栈中重新装入CPU寄存器, 并开始下一个任务的运行, 这一过程就是context switch。 -
Linux执行过程如下
以正在运行的用户态进程X切换到用户态进程Y为例具体表述如下:- 正在运行的用户态进程X
- 发生中断(包括异常、系统调用等),硬件完成以下动作:1)save cs:eip/ss:eip/eflags:当前CPU上下文压入用户态进程X的内核堆栈;2)load cs:eip/ss:esp:加载当前进程内核堆栈相关信息,跳转到中断处理程序处,即中断处理程序的起点
- SAVE_ALL,保存现场,此时完成了中断上下文的切换,即从进程X的用户态到进程X的内核态
- 中断处理过程中或中断返回前调用了schedule函数进行进程上下文切换。将当前用户进程X的内核堆栈切换到挑选出的next进程Y的内核堆栈,并完成进程上下文所需的EIP等寄存器的状态切换;
- 标号1,即$1f,之后开始运行用户态进程Y
- restore_all,恢复现场,与SAVE_ALL保存现场相对应
- 从Y进程的内核堆栈弹出步骤2硬件完成的压栈内容,此时完成中断上下文的切换,即从进程Y的内核态返回进程Y的用户态;
- 继续运行进程Y
-
中断处理程序的限制
- 不能向用户空间发送或接受数据
- 不能使用可能引起阻塞的函数
- 不能使用可能引起调度的函数